はじめに
Apache Hadoopは、ビッグデータによってもたらされる多くの課題を解決するために管理する、非常に成功したフレームワークです。この効率的なソリューションは、クラスター内の数千のノードにストレージと処理能力を分散します。完全に開発されたHadoopプラットフォームには、コアHadoopフレームワークを強化し、あらゆる障害を克服できるようにするツールのコレクションが含まれています。
基盤となるアーキテクチャと、Hadoopエコシステムで利用可能な多くのツールの役割は、初心者にとって複雑であることが判明する可能性があります。
この記事では、Apache Hadoopのエキサイティングなエコシステムを探索するのに役立つ、多くの図と簡単な説明を使用しています。

Hadoopアーキテクチャの概要
膨大な量とさまざまなデータ構造を持つビッグデータは、従来のネットワークフレームワークとツールを圧倒してきました。高性能のハードウェアと専用サーバーを使用すると役立ちますが、柔軟性がなく、かなりの値札が付いています。
Hadoopは、相互接続された手頃な価格のコモディティハードウェアを使用して、膨大な量のデータを処理および保存することができます。数百または数千もの低コストの専用サーバーが連携して、単一のエコシステム内でデータを保存および処理します。
Hadoop分散ファイルシステム(HDFS)、 YARN 、および MapReduce そのエコシステムの中心にあります。 HDFSは、大規模なデータセットを保存するために使用されるプロトコルのセットですが、MapReduceは受信データを効率的に処理します。
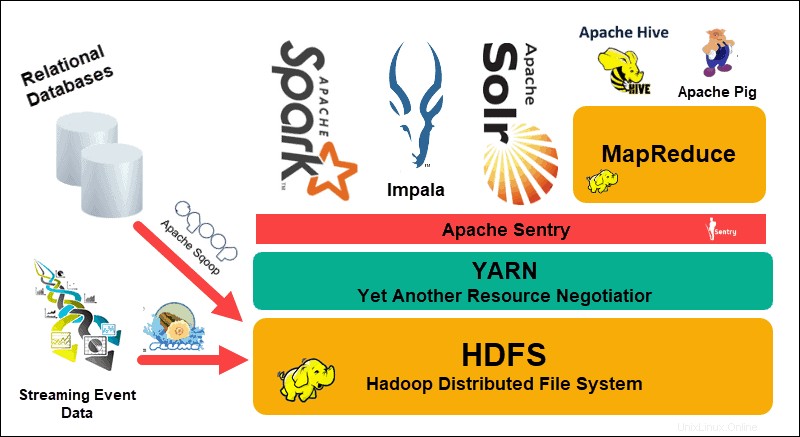
Hadoopクラスターは、1つまたは複数のマスターノードと、さらに多くのいわゆるスレーブノードで構成されます。 HDFSとMapReduceは、ノードを追加することで線形にスケールアウトできる柔軟な基盤を形成します。ただし、ビッグデータの複雑さは、常に改善の余地があることを意味します。
さらに別のリソースネゴシエーター(YARN) Hadoopクラスターのリソース管理とスケジューリングプロセスを改善するために作成されました。汎用インターフェースを備えたYARNの導入により、他のデータ処理ツールをHadoopエコシステムに組み込むための扉が開かれました。
それ以来、活気に満ちた開発者コミュニティは、Hadoopを補完するために多数のオープンソースApacheプロジェクトを作成してきました。これらのソリューションの多くには、Apache Hive、Impala、Pig、Sqoop、Spark、Flumeなどのキャッチーでクリエイティブな名前が付いています。これらのツールは、さまざまなデータ型をコンパイルおよび処理します。また、ユーザーフレンドリーなインターフェース、メッセージングサービスを提供し、クラスターの処理速度を向上させます。
HDFS、YARN、およびMapReduceをコアとする拡張ソフトウェアスタックにより、Hadoopはビッグデータを処理するための頼りになるソリューションになります。
Hadoopアーキテクチャのレイヤーを理解する
分散システムの要素を機能レイヤーに分離することで、データの管理と開発を合理化できます。開発者は、より広範なエコシステム上の他のプロセスに悪影響を与えることなく、フレームワークに取り組むことができます。
Hadoopは、4つの特徴的なレイヤーに分割できます。
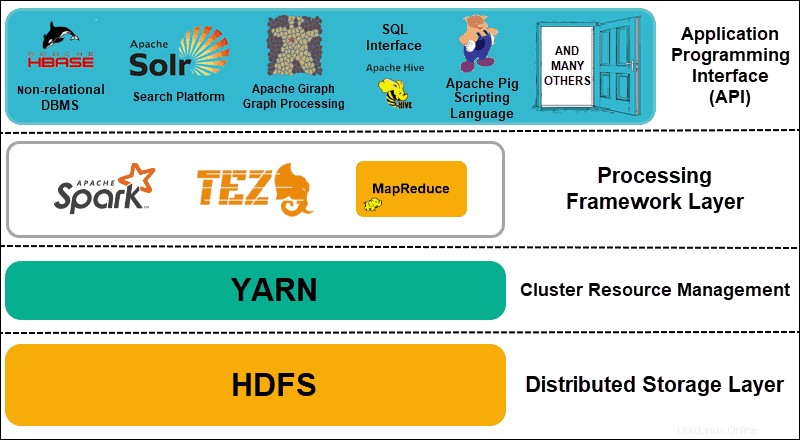
1。分散ストレージレイヤー
Hadoopクラスターの各ノードには、独自のディスクスペース、メモリ、帯域幅、および処理があります。着信データは個々のデータブロックに分割され、HDFS分散ストレージレイヤー内に保存されます。 HDFSは、クラスター内のすべてのディスクドライブとスレーブノードが信頼できないと想定しています。予防措置として、HDFSはクラスター全体に各データセットの3つのコピーを保存します。 HDFSマスターノード( NameNode )個々のデータブロックとそのすべてのレプリカのメタデータを保持します。
2。クラスタリソース管理
Hadoopは、無数のアプリケーションとユーザーがリソースを効果的に共有できるように、ノードを完全に調整する必要があります。当初、MapReduceはリソース管理とデータ処理の両方を処理していました。 YARNはこれら2つの機能を分離します。 Hadoopの事実上のリソース管理ツールとして、YARNはHadoop用に作成されたさまざまなフレームワークにリソースを割り当てることができるようになりました。これには、Apache Pig、Hive、Giraph、Zookeeperなどのプロジェクト、およびMapReduce自体が含まれます。
3。処理フレームワークレイヤー
処理レイヤーは、クラスターに入ってくるデータセットを分析および処理するフレームワークで構成されています。構造化データセットと非構造化データセットは、マッピング、シャッフル、並べ替え、マージされ、管理しやすい小さなデータブロックに縮小されます。これらの操作は、データが配置されているサーバーにできるだけ近い複数のノードに分散されます。 Spark、Storm、Tezなどの計算フレームワークにより、リアルタイム処理、インタラクティブなクエリ処理、およびMapReduceエンジンを支援し、HDFSをはるかに効率的に利用するその他のプログラミングオプションが可能になりました。
4。アプリケーションプログラミングインターフェイス
Hadoop 2にYARNが導入されたことで、新しい処理フレームワークとAPIが作成されました。ビッグデータは拡大を続けており、その成長に合わせてさまざまなツールを使用する必要があります。検索プラットフォーム、データストリーミング、ユーザーフレンドリーなインターフェース、プログラミング言語、メッセージング、フェイルオーバー、セキュリティに焦点を当てたプロジェクトはすべて、包括的なHadoopエコシステムの複雑な部分です。
HDFSの説明
Hadoop分散ファイルシステム(HDFS)は、設計上フォールトトレラントです。データは、複数のノードとサーバーラックにまたがる3つの別々のコピーの個々のデータブロックに保存されます。ノードまたはラック全体に障害が発生した場合でも、より広範なシステムへの影響はごくわずかです。
DataNodes NameNodes でデータブロックを処理し、保存します 多くのDataNodeを管理し、データブロックのメタデータを維持し、クライアントアクセスを制御します。
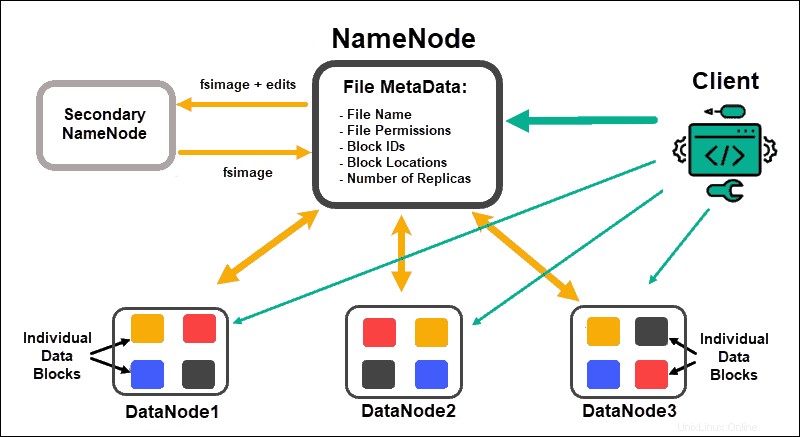
NameNode
最初に、データは抽象的なデータブロックに分割されます。これらのブロックのファイルメタデータには、ファイル名、ファイルのアクセス許可、ID、場所、レプリカの数が含まれ、NameNodeローカルメモリのfsimageに保存されます。
NameNodeに障害が発生した場合、HDFSはDataNode全体に分散されているデータセットを見つけることができません。これにより、NameNodeはクラスター全体の単一障害点になります。この脆弱性は、セカンダリNameNodeまたはスタンバイNameNodeを実装することで解決されます。
セカンダリNameNode
セカンダリNameNodeは、初期のHadoopバージョンではプライマリバックアップソリューションとして機能していました。セカンダリNameNodeは、頻繁に、現在のfsimageインスタンスをダウンロードし、NameNodeからログを編集してそれらをマージします。編集したfsimageは、プライマリNameNodeで取得および復元できます。
管理者はセカンダリNameNodeからデータを手動で回復する必要があるため、フェイルオーバーは自動化されたプロセスではありません。
スタンバイNameNode
高可用性 この機能は、NameNodeに障害が発生した場合のダウンタイムを回避するために、Hadoop2.0以降のバージョンで導入されました。この機能により、2つのNameNodeを別々の専用マスターノードで実行し続けることができます。
スタンバイNameNodeは、アクティブNameNodeが使用できなくなった場合の自動フェイルオーバーです。スタンバイNameNodeは、さらにチェックポイントプロセスを実行します。このプロパティのため、セカンダリとスタンバイのNameNodeには互換性がありません。 Hadoopクラスターはどちらか一方を維持できます。
ズーキーパー
Zookeeperは、高可用性と冗長性をサポートする軽量ツールです。スタンバイNameNodeは、Zookeeperデーモンとのアクティブなセッションを維持します。
アクティブなNameNodeが機能しなくなった場合、Zookeeperデーモンは障害を検出し、新しいNameNodeへのフェイルオーバープロセスを実行します。 Zookeeperを使用してフェイルオーバーを自動化し、NameNodeの障害がクラスターに与える可能性のある影響を最小限に抑えます。
DataNode
クラスタ内の各DataNodeは、バックグラウンドプロセスを使用して、データの個々のブロックをスレーブサーバーに保存します。
デフォルトでは、HDFSはすべてのデータブロックの3つのコピーを別々のDataNodeに保存します。 NameNodeは、ラック対応の配置ポリシーを使用します。これは、データブロックレプリカを含むDataNodeをすべて同じサーバーラックに配置することはできないことを意味します。
DataNodeは、NameNodeからの命令を1分間に約20回通信して受け入れます。また、そのノードにあるデータブロックのステータスと状態を1時間に1回報告します。提供された情報に基づいて、NameNodeはDataNodeに追加のレプリカを作成するか、それらを削除するか、ノードに存在するデータブロックの数を減らすように要求できます。
ラックアウェア配置ポリシー
HDFSのような分散ストレージシステムの主な目的の1つは、高可用性とレプリケーションを維持することです。したがって、データブロックは、さまざまなDataNodeだけでなく、さまざまなサーバーラックに配置されたノードにも分散する必要があります。
これにより、ラック全体の障害によってすべてのデータレプリカが終了するわけではありません。 HDFS NameNodeは、デフォルトのラック対応レプリカ配置ポリシーを維持します:
- 最初のデータブロックレプリカは、クライアントと同じノードに配置されます。
- 2番目のレプリカは、別のラックのランダムなDataNodeに自動的に配置されます。
- 3番目のレプリカは、2番目のレプリカと同じラックの別のDataNodeに配置されます。
- 追加のレプリカは、クラスター全体のランダムなDataNodeに保存されます。
このラック配置ポリシーは、ノードごとに1つのレプリカのみを維持し、サーバーラックごとに2つのレプリカの制限を設定します。
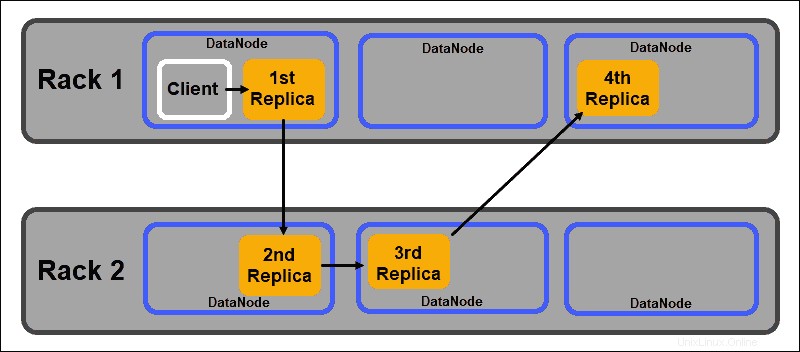
ラックの障害は、ノードの障害よりもはるかに少ない頻度です。 HDFSは、常に少なくとも1つのデータブロックレプリカを別のラックのDataNodeに保存することで、高い信頼性を保証します。
YARNの説明
YARN(Yet Another Resource Negotiator)は、Hadoop2およびHadoop3のデフォルトのクラスター管理リソースです。以前のHadoopバージョンでは、MapReduceはデータ処理とリソース割り当ての両方を実行するために使用されていました。時間の経過とともに、処理とリソース管理を分割する必要性がYARNの開発につながりました。
YARNのリソース割り当ての役割は、HDFSで表されるストレージレイヤーとMapReduce処理エンジンの間に配置されます。 YARNは、さまざまなデータ型の新しい処理エンジンを実装できる汎用インターフェイスも提供します。
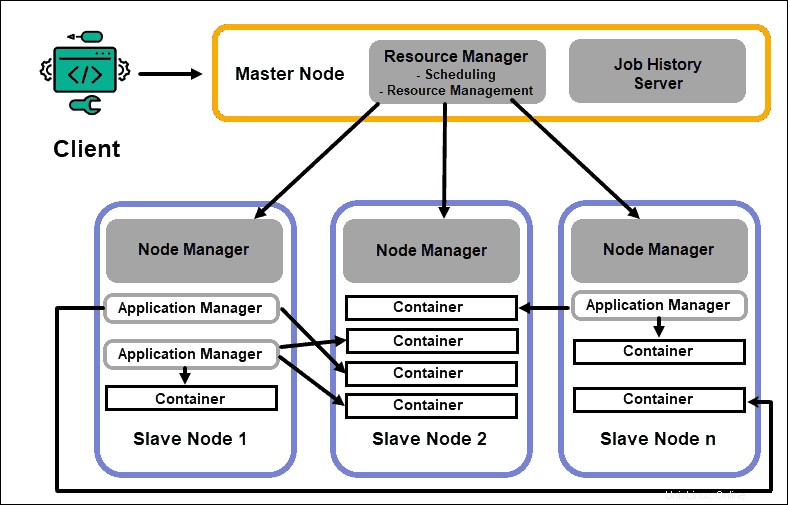
ResourceManager
ResourceManager(RM)デーモンは、Hadoopクラスター内のすべての処理リソースを制御します。その主な目的は、スレーブノードにある個々のアプリケーションにリソースを指定することです。進行中および計画中のプロセスのグローバルな概要を維持し、リソース要求を処理し、それに応じてリソースをスケジュールおよび割り当てます。 ResourceManagerはHadoopフレームワークに不可欠であり、専用のマスターノードで実行する必要があります。
RMの唯一の焦点は、ワークロードのスケジューリングです。 MapReduceとは異なり、フェイルオーバーや個々の処理タスクには関心がありません。 YARNでのこのタスクの分離により、Hadoopは本質的にスケーラブルになり、完全に開発されたコンピューティングプラットフォームになります。
NodeManager
各スレーブノードには、NodeManager処理サービスとDataNodeストレージサービスがあります。これらが一緒になって、Hadoop分散システムのバックボーンを形成します。
前述のように、DataNodeはHDFSの要素であり、NameNodeによって制御されます。 NodeManagerは、同様の方法で、ResourceManagerのスレーブとして機能します。 NodeManagerデーモンの主な機能は、スレーブノードの処理リソースデータを追跡し、定期的なレポートをResourceManagerに送信することです。
コンテナ
Hadoopクラスターの処理リソースは、常にコンテナーにデプロイされます。コンテナには、メモリ、システムファイル、および処理スペースがあります。
コンテナのデプロイは一般的であり、要求されたカスタムリソースを任意のシステムで実行できます。要求されたクラスターリソースの量が許容範囲内である場合、RMはそのコンテナーを承認し、デプロイするようにスケジュールします。
スレーブノード上のコンテナプロセスは、最初にその特定のスレーブノード上のNodeManagerによってプロビジョニング、監視、および追跡されます。
アプリケーションマスター
スレーブノード上のすべてのコンテナには、専用のアプリケーションマスターがあります。アプリケーションマスターもコンテナーにデプロイされます。 MapReduceにも、マップを実行してタスクを削減するアプリケーションマスターがあります。
アプリケーションマスターは、アクティブである限り、現在のステータスと監視しているアプリケーションの状態に関するメッセージをリソースマネージャーに送信します。提供された情報に基づいて、リソースマネージャーは追加のリソースをスケジュールするか、不要になった場合はクラスター内の別の場所に割り当てます。
アプリケーションマスターは、RMから必要なコンテナーを要求することから、NodeManagerにコンテナーリース要求を送信することまで、アプリケーションのライフサイクル全体を監視します。
JobHistoryサーバー
JobHistoryサーバーを使用すると、ユーザーはアクティビティを完了したアプリケーションに関する情報を取得できます。 REST APIは相互運用性を提供し、問題のサーバーによって提供されている現在のジョブと完了したジョブについてユーザーに動的に通知できます。
YARNはどのように機能しますか?
YARNでのデプロイの基本的なワークフローは、クライアントアプリケーションがResourceManagerにリクエストを送信したときに開始されます。
- ResourceManager NodeManagerに指示します アプリケーションマスターを起動するには このリクエストの場合、コンテナで開始されます。
- 新しく作成されたアプリケーションマスター RMに自分自身を登録します 。アプリケーションマスターは、 HDFS NameNodeへの接続に進みます。 必要なデータブロックの場所を特定し、マップの量を計算して、データの処理に必要なタスクを削減します。
- アプリケーションマスター 次に、 RMに必要なリソースを要求します コンテナのライフサイクル全体を通じて、リソース要件を引き続き伝達します。
- RM 他のすべてのアプリケーションマスターからのリクエストとともにリソースをスケジュールします リクエストをキューに入れます。リソースが利用可能になると、RMは特定のスレーブノード上のアプリケーションマスターがそれらを利用できるようにします。
- アプリケーションマネージャー NodeManagerに連絡します そのスレーブノードに対して、変数、認証トークン、およびプロセスのコマンド文字列を提供することにより、コンテナを作成するように要求します。そのリクエストに基づいて、 NodeManager コンテナを作成して開始します 。
- アプリケーションマネージャー 次に、プロセスを監視し、障害が発生した場合は、次に使用可能なスロットでプロセスを再開することで対応します。 4回の試行後に失敗した場合、ジョブ全体が失敗します。このプロセス全体を通じて、ApplicationManagerはクライアントステータス要求に応答します。
すべてのタスクが完了すると、アプリケーションマスターは結果をクライアントアプリケーションに送信し、アプリケーションがタスクを完了したことをRMに通知し、リソースマネージャーから登録を解除して、シャットダウンします。
RMは、処理の優先順位が変更された場合に、プロセス中に特定のコンテナーを終了するようにNameNodeに指示することもできます。
MapReduceの説明
MapReduceは、Hadoopクラスター全体に分散されたデータを処理するプログラミングアルゴリズムです。 Hadoopの他のプロセスと同様に、MapReduceジョブが開始されると、ResourceManagerはアプリケーションマスターにMapReduceジョブのライフサイクルを管理および監視するように要求します。
アプリケーションマスターは、NameNodeに格納されている情報に基づいて、必要なデータブロックを見つけます。 AMは、データブロックが配置されているのと同じノードでMapReduceジョブを開始するようにResourceManagerに通知します。可能な限り、データはスレーブノードでローカルに処理され、帯域幅の使用量を減らし、クラスターの効率を向上させます。
入力データはマッピングされ、シャッフルされてから、集計結果に変換されます。 MapReduceジョブの出力は、HDFSに保存および複製されます。
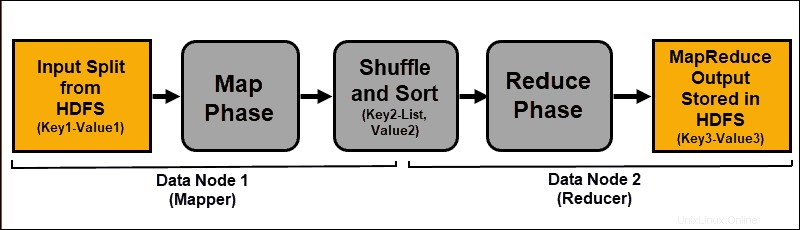
マッピングおよび削減タスクを実行するHadoopサーバーは、多くの場合、マッパーと呼ばれます。 および削減者 。
ResourceManagerは、使用するマッパーの数を決定します。この決定は、処理されたデータのサイズと各マッパーサーバーで使用可能なメモリブロックによって異なります。
マップフェーズ
マッピングプロセスは、HDFSデータブロックに格納されているデータの個々の論理式を取り込みます。これらの式は複数のデータブロックにまたがることができ、入力分割と呼ばれます。 。 入力分割は、キーと値のペアとしてマッピングプロセスに導入されます。 。
マッパータスクは、すべてのキーと値のペアを調べて、元の入力データとは異なる新しいキーと値のペアのセットを作成します。すべてのキーと値のペアの完全な品揃えは、マッパータスクの出力を表します。
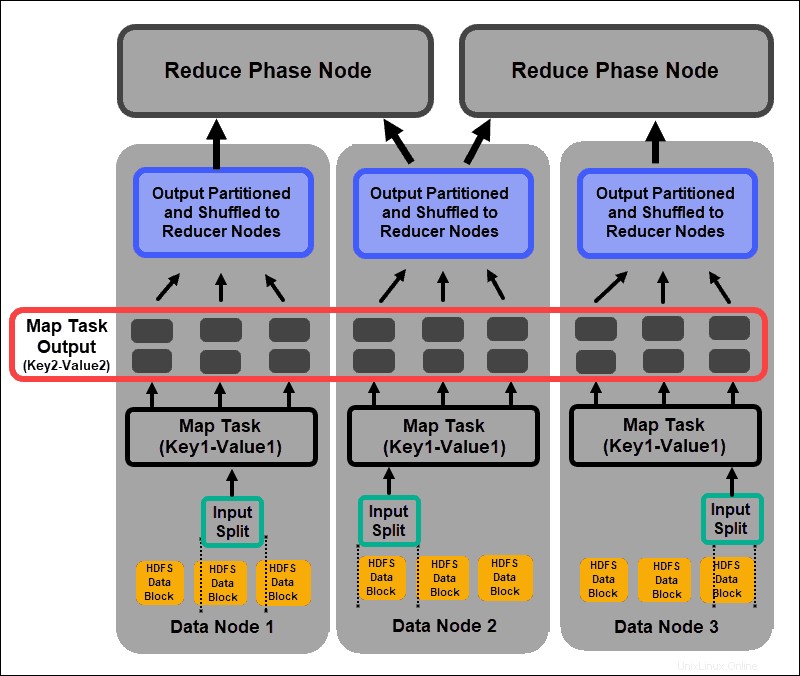
各ペアのキーに基づいて、データはグループ化され、パーティション化され、レデューサーノードにシャッフルされます。
シャッフルおよびソートフェーズ
シャッフル すべてのマップタスクの結果がレデューサーノードにコピーされるプロセスです。マップタスク出力のコピーは、MapReduceジョブ全体でノード間でデータを交換する唯一の方法です。
マップタスクの出力は、reduceフェーズの効率を向上させるために調整する必要があります。マッパーノードからシャッフルされるマップされたキーと値のペアは、対応する値を持つキーによって配列されます。入力がソートされた後、reduceフェーズが開始されます 単一の入力ファイルをキー入力します。
シャッフルフェーズとソートフェーズは並行して実行されます。マップ出力はマッパーノードから取得されますが、それらはレデューサーノードでグループ化およびソートされます。
フェーズの削減
マップ出力はシャッフルされ、レデューサーノードにある単一のリデュース入力ファイルにソートされます。 reduce関数は、入力ファイルを使用して、対応するマップされたキーに基づいて値を集約します。リデュースプロセスからの出力は、新しいキーと値のペアです。この結果は、MapReduceジョブ全体の出力を表し、デフォルトではHDFSに保存されます。
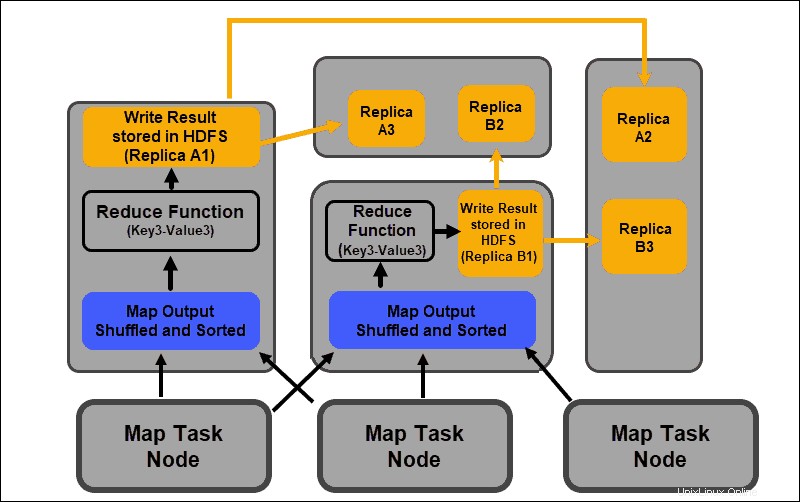
すべてのreduceタスクは同時に実行され、互いに独立して機能します。削減タスクもオプションです。
マップタスクの結果が望ましい結果であり、単一の出力値を生成する必要がない場合があります。
Hadoopをデプロイするためのベストプラクティス
次のセクションでは、基盤となるハードウェア、ユーザー権限、およびバランスの取れた信頼性の高いクラスターの維持が、Hadoopエコシステムをさらに活用するのにどのように役立つかについて説明します。
Hadoopユーザー権限の調整
Kerberosネットワークプロトコルは、Hadoopの主な認証システムです。検証済みのノードとユーザーのみがクラスター内でアクセスおよび操作できるようにします。
Kerberos Key Distribution Centerをインストールして構成したら、Hadoop構成ファイルにいくつかの変更を加える必要があります。 Hadoop core-site.xml ファイルは、Hadoopクラスター全体のパラメーターを定義します。 hadoop.security.authenticationを設定します core-site.xml内のパラメータ kerberosへ 。 同じプロパティをtrueに設定する必要があります サービス認証を有効にします。
hadoop-policy-xmlのアクセス制御リスト ファイルを編集して、特定のユーザーにさまざまなアクセスレベルを付与することもできます。基本的なコマンドラインツールでは、必要なユーザー権限と多すぎる権限のバランスをとることが難しい場合があります。
Apacheなどの追加のセキュリティフレームワークを使用することをお勧めします レンジャー またはApacheSentry 。これらのツールは、中央のユーザーフレンドリーな環境からすべてのセキュリティ関連タスクを管理するのに役立ちます。これらを使用して、プロセスを完全に制御しながら、タスクとユーザーに特定の承認を提供します。
バランスの取れたHadoopクラスター
Hadoopのような分散システムは動的な環境です。新しいノードを追加したり、古いノードを削除したりすると、クラスター内に一時的な不均衡が生じる可能性があります。データブロックは複製不足になる可能性があります。
目標は、クラスター内のスレーブノード間で可能な限り一貫してデータを分散することです。 Hadoopクラスターバランシングユーティリティを使用して、事前定義された設定を変更します。 hdfs balancerを使用してバランシングポリシーを定義します 指図。このコマンドとそのオプションを使用すると、ノードのディスク容量のしきい値を変更できます。
Hadoop2.x以降のデフォルトのブロックサイズは128MBです。 Hadoopを使用すると、ユーザーはこの設定を変更できます。かなりの量のデータを処理する場合は、デフォルトのデータブロックサイズを変更することを検討してください。そうしないと、開始されたジョブの数がクラスターを圧倒する可能性があります。
データブロックサイズを大きくすると、マップタスクへの入力が大きくなり、開始されるマップタスクが少なくなります。これは、データをレデューサーノードに転送するときにシャッフルフェーズのスループットが大幅に向上することを意味します。この簡単な調整により、MapReduceジョブの完了にかかる時間を短縮できます。
スケーリングHadoop(ハードウェア)
NameNodeは、Hadoopクラスターの重要な要素です。このノードにできるだけ多くのプロセッシングコアを使用します。 RAMの量は、ノードのメモリから読み取られるデータの量を定義します。マスターノードで利用可能なリソースに過剰な負担をかけると、クラスターの成長能力が制限されます。
冗長電源は常にマスターノード用に予約する必要があります。データノードに冗長電源と貴重なハードウェアリソースを使用しないようにしてください。これらはHadoopエコシステムの重要な部分ですが、消耗品です。中間処理機能を備えた手頃な価格の専用サーバーは、消費電力と発熱量が少ないため、データノードに最適です。
Hadoopのスケーリング機能は、その広範な実装の背後にある主な推進力です。クラスタを拡張するために、常に十分なスペースが必要です。新しいノードまたはディスクスペースをすばやく追加するには、追加の電源、ネットワーク、および冷却が必要です。将来の成長を綿密に計画しなければ、これらすべてが非常に困難になる可能性があります。
スケーリングHadoop(ソフトウェア)
新しいHadoopプロジェクトは定期的に開発されており、既存のプロジェクトはより高度な機能で改善されています。
従来のツールでさえ、Hadoopエコシステムの恩恵を受けることができるようにアップグレードされています。この面での新しい開発に常に目を光らせてください。受信データセットの多様性と量により、追加のフレームワークの導入が義務付けられています。
新しいユーザーフレンドリーなツールを実装すると、カスタムソリューションを作成するよりも早く技術的なジレンマを解決できます。すでに開発された商用のクイックフィックスを躊躇しないでください。市場は、Hadoop-as-a-serviceまたはカスタマイズされたスタンドアロンツールを提供するベンダーで飽和状態になっています。
データの信頼性と障害許容度
H eartbeat 繰り返し発生するTCPハンドシェイク信号です。各スレーブサーバーにあるDataNodeは、マスターサーバーにあるNameNodeにハートビートを継続的に送信します。デフォルトのハートビート時間枠は3秒です。 NameNodeが10分を超えて信号を受信しない場合、DataNodeをオフに書き込み、そのデータブロックは異なるノードで自動スケジュールされます。
NameNodeの負荷を軽減するために、ハートビート周波数を下げないでください。非常に大規模なクラスターであっても、NameNodeに「情報を提供」することは非常に重要です。定期的かつ頻繁なハートビートの流入がないと、NameNodeは大幅に妨げられ、クラスターを効果的に制御できません。
重大な障害の影響を回避するには、デフォルトのラック認識設定を維持し、サーバーラック間でデータブロックのレプリカを保存します。サーバーラックを紛失しても、他のレプリカは存続し、データ処理への影響は最小限に抑えられます。