はじめに
ビッグデータをキャプチャして処理する必要性は、NoSQLデータベースの人気の背後にある主な原動力です。保存されたデータは、いつでも、どこからでも、どのデバイスからでもアクセスできる必要があります。増大する需要に対応する1つの方法は、スケールアップしてより大きなサーバーを購入することです。ただし、スケールアウトしてオンデマンドサーバーのクラスターを使用する方が効率的です。
リレーショナルデータベースモデルは、複数のマシンにまたがる分散システムには適していません。 NoSQLデータベースは、パフォーマンスと可用性に重点を置きながら、リレーショナルデータベースで通常識別される一貫性の一部を犠牲にすることで、実行可能なソリューションを提供します。
「NoSQLとは」という質問に答える以外に 」、このチュートリアルでは、簡単な例を使用して、基本的なNoSQLの概念、機能、およびタイプを強調しています 。

NoSQLとは何ですか? (NoSQL定義)
NoSQL(SQLではないまたはSQLだけではない)は、リレーショナルモデルに依存しないデータベースに使用される一般的な用語です。データは、厳密なスキーマや通常のSQLテーブル構造を持つ必要はありません。最も一般的には、データはキーと値のペア、JSONドキュメント、グラフ、として集約されます。 またはワイド列テーブル。
NoSQLデータベースを使用すると、大量の非構造化データを受信時に保存し、後で構造化することができます。予想どおり、これによりスループットと読み取り/書き込み速度が大幅に向上し、サーバーを水平方向にスケールアウトできます。
非リレーショナルデータベースは、適切なユースケース環境に適用されると、パフォーマンスと柔軟性の点で大きなメリットをもたらします。ただし、データエントリポイントにスキーマを適用しないということは、NoSQLデータベースのクエリ、データの一貫性の維持、データセット間の関係の確立がより困難になることも意味します。
NoSQLの仕組み
NoSQLの背後にある基本的な考え方は、RDBMSに存在するいくつかのデータ整合性の制限を回避することにより、水平スケーリング、大量のデータ、および低遅延のためにデータベースのパフォーマンスを最適化することです。表、列、行などの厳密なデータモデルの代わりに、NoSQLデータベースは柔軟なモデルを提供します。リレーショナルの一貫性を必要としないユースケースでは、これらのモデルは、NoSQLがリレーショナルデータベースよりも優れたパフォーマンスを発揮するのに役立ちます。
NoSQLデータベースの機能
NoSQLデータベースは構造的に多様であり、さまざまなデータストレージモデルを提供します。ただし、NoSQLとリレーショナルデータベースを区別する一般的な属性がいくつかあります。
読み取りのスキーマ
NoSQLデータベースを使用すると、構造を適用する前にデータを保存できます。 またはスキーマ 。
スキーマは、データにアクセスする場合にのみアプリケーションコードによって適用されます。このプロセスは、多くの場合、読み取り時のスキーマと呼ばれます。 。 事前にデータを構造化しないことで、NoSQLデータベースはリレーショナルデータベースよりもはるかに高速に膨大な量のデータを読み書きできます。
NoSQLとリレーショナルデータベース
対照的に、SQLリレーショナルモデルは、データベースに書き込まれる前に受信データを構造化します。事前定義されたスキーマ設計を使用して、可能なすべてのデータ型を事前に分類します。データが構造化され、テーブル、列、行に格納されるため、スキーマは全面的に適用されます。
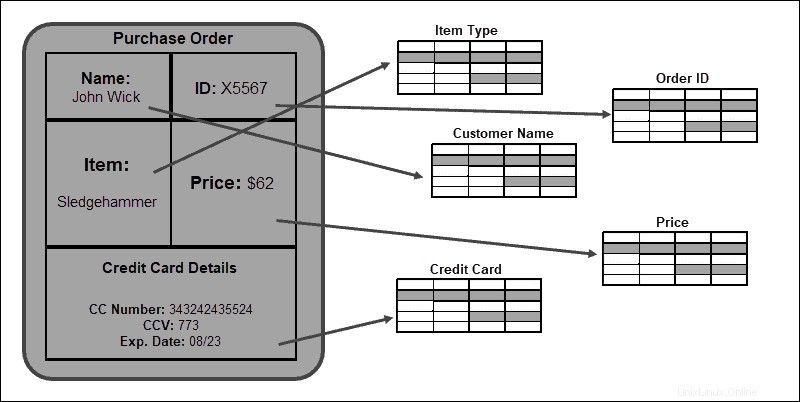
厳密な表形式の構造は、テーブルとデータベース要素間の関係を確立する際の利点です。このスキーマに準拠することで、データの一貫性と整合性が保証されます。
非リレーショナルデータモデル
NoSQLデータベースは、個々のレコード間の関係を確立しません。通常、1つのレコードは個別のJSONドキュメントとして保存され、クラスター内の複数のノードに複製されます。
音楽バンドに関するデータを含む簡単な例を使用します。非リレーショナルモデルでは、 BandID 、バンド名 、国 、ジャンル 、ラベル 、 AlbumID 、アルバム名、 およびリリース日 属性は単一のレディオヘッドに保存されます 資料。 Radioheadアルバムのリリース日を確認する必要がある場合は、 OK Computer 、応答は非常に高速です。クエリは、(リレーショナルデータベースのように)複数のテーブルから情報を取得する必要がなく、単一のエントリから情報を取得する必要があるため、結果をはるかに迅速に提供します。
あるレコードの集約データを別のレコードの集約データに関連付けることはできません。ストリーミングサービスなどの属性を追加する場合は、データベース内の関連する各レコードを更新する必要があります。 したがって、NoSQLデータベースは、後で構造化または関連付ける必要のない大量のデータに最適です。
BASE vs ACID
データベースは、ネットワーク障害が発生した場合に操作をキャンセルしてデータの一貫性を確保する必要がありますか?または、データベースは高可用性を確保するためにデータの不整合のリスクを冒す必要がありますか?
NoSQLの主な焦点は、結果整合性を提供することで可用性を維持することです。 結果整合性 BASEセマンティクスの一部です。 BASEは、データが書き込まれると、最終的には読み取り用に表示されると述べています。強力な保証がないと、現在の状態がまだ収束していない可能性があるため、現在の状態を知る可能性は限られています。システムが機能していて、特定の入力セットの後に十分長く待つと、最終的にデータベースの実際の状態を知ることができます。
欠点は、競合が調整された後、データが持続しない可能性があることです。読み取りは、不明な期間の最新の書き込みを取得しない場合があります。 Facebookの投稿が数分間表示されないことは許容されますが、金融取引をすぐに確認できないことは重要な問題です。
ACID
- A トミシティ。指定されたデータのみが操作の影響を受けます。
- C 一貫性。各操作により、データベースが1つの一貫した状態から別の一貫した状態に移動します。
- 私 孤独。 1つの操作が他の同時操作に影響を与えることはありません。
- D 耐久性。トランザクションが成功してもデータが失われることはありません。
ベース
- B asically A 利用可能。 書き込みと読み取りの操作は可能な限り利用できますが、厳密な保証はありません。
- S 多くの場合、州。 保証がない場合、データが最終的に一貫性を持つようになるかどうかはわかりませんが、期待しています。
- E 腹側の一貫性。 システムが完全に機能し、十分な期間が経過した場合、最終的にデータベースの実際の状態がわかります。
リレーショナルデータベースは一貫性に重点を置いています 維持するためのより重要な機能として。 一貫性 データベースのプロパティにより、データベースにレコードを書き込んだ後、すぐにそのレコードを要求した場合に、そのレコードが表示されることが保証されます。リレーショナルデータベースによって適用されるACIDのプロパティセットは、データが書き込まれると、読み取りに完全な一貫性があることを意味します。
最も人気のある2つのデータベーストランザクションモデルとそれらの違いについては、ACIDとBASEの記事をご覧ください。
水平スケーリング
企業は、データを活用する効果的な方法を見つけました。そのデータの量、速度、多様性が急速に増大しているため、NoSQLデータベースが急増しています。
主要なWebサイトとオンラインプラットフォームは、読み取り/書き込み速度や事前にデータを正規化する必要性など、リレーショナルデータベースの制限のいくつかを克服する必要がありました。重要な制限の1つは、リレーショナルモデルの柔軟性の欠如です。 スケールアウトに関しては。リレーショナルモデルでは、データは通常、パーティション化または分離されていません。代わりに、単一のノードに集中しており、データベースは既存のハードウェアの能力を高めることによってのみスケールアップできます。
NoSQLデータベースは、分散システムで効率的に実行されるように設計されています すぐに水平方向にスケールアウトします。分散システムには、一定の高可用性を提供するという追加の利点があります。レコードの複数のレプリカがサーバーとラック間で保持され、ハードウェア障害がデータの可用性に影響を与えることはありません。高価なハイエンドサーバーの代わりにコモディティハードウェアを安全に使用して、急増するデータ負荷を管理できます。
NoSQLデータベースの種類
非リレーショナルデータベースモデルは、大きく4つのカテゴリに分類できます。
- キーバリューストア あらゆる種類のデータを一意のキーで保存できます。
- ドキュメントデータベースは、単一のJSONまたはXMLドキュメント内にさまざまなデータ型を集約することで同様のアプローチを使用します。
- 列ベース ベースは、選択した列の下にデータを格納します。
- グラフデータベースは、データ要素を表すノードのエッジとプロパティを確立します。
Key-Valueデータベース
Key-Valueデータベースは、Key-Valueストアと呼ばれることもあり、最も単純なデータモデル(キーと値のペア)を使用します。アプリケーションは、一意のキーを使用して値を取得します。
値には、任意のデータ構造またはタイプを含めることができます。コンテンツを理解するためにデータにアクセスしようとするのはアプリケーション次第です。
Key-Valueデータベースの例には、Redis、 Riakが含まれます。 、エアロスパイク 、および Oracle NoSQL 。
列ベースのデータベース
列ベースのデータベースは、読み取り操作の効率に重点を置いています。複数の行の複数の列をすばやく読み取る必要がある場合は、データを列のグループ(つまり、列ファミリー)に整理するのが理にかなっています。
モデル構造は、行識別子で構成されています これは、集計データと、より詳細な2次レベルの値(つまり、列)で構成される行集計を定義します。 。
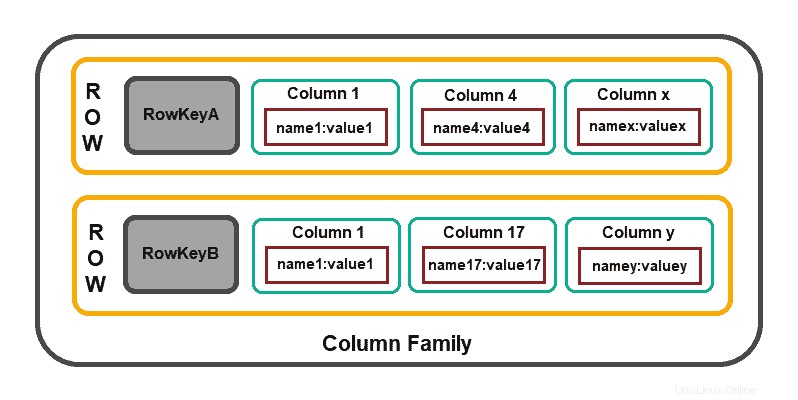
カサンドラ 、 HBase 、 Amazon DynamoDB およびクリックハウス 、は広く使用されている列ベースのソリューションの一部です。
ドキュメントデータベース
ドキュメントデータベースは、JSON、BSON、XML、またはその他の形式を使用して、部分的に構造化されたデータをドキュメントに格納します。ドキュメント内のデータは半構造化されているため、クエリを実行する際の柔軟性が高まります。基本的なKey-Valueストアとは異なり、ユーザーはレコード全体を取得する必要はなく、ドキュメントの関連部分のみを取得する必要があります。

Web向けのドキュメント、ユーザーコメント、およびWeb公開アプリはすべて、このデータモデルの恩恵を受けています。有名なドキュメントベースのNoSQLはMongoDB 、 OrientDB 、 Apache CouchDB 、および MarkLogic 。
グラフデータベース
グラフデータベースはデータをノードに編成し、Edgeはこれらのデータノード間の関係を確立します。
このデータストレージモデルは、ソーシャルメディアプラットフォーム、顧客関係ソフトウェア、旅行および予約システムなど、関係を強調するアプリケーションで役立つことが証明されました。
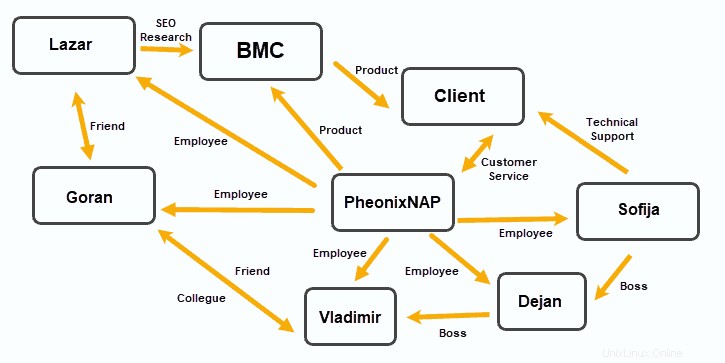
ドキュメントベースのOrientDBとMarkLogicは、グラフデータベースとして機能できます。 JanusGraph 、 RedisGraph 、および Neo4j 人気のあるグラフベースのソリューションです。
NoSQLの利点
- パフォーマンス – NoSQLデータベースは、高度なリレーショナルではないデータを処理するユースケースでより優れたパフォーマンスを提供します。 NoSQLは非正規化されたスキーマを想定し、それに応じて読み取りを最適化します。
- 柔軟性 – NoSQLの動的スキーマにより、特定のケースに最適な方法で非構造化データを保存できます。構造を定義せずにドキュメントを作成できます。
- スケーラビリティ –マシンのメモリ、ストレージ、または処理能力をアップグレードすることでRDBMSを垂直方向にスケーリングすることは可能ですが、NoSQLには水平方向のスケーリングという追加の利点があります。これは、追加のサーバーでデータベースをアップグレードすることにより、トラフィックの増加に対処できることを意味します。
NoSQLを使用するタイミング
考えられるすべてのシナリオに単一のデータベースソリューションを適用しようとするのは良い考えではありません。この記事で取り上げるさまざまなデータベースタイプは、特定のデータの問題に対処するように設計されています。これはNoSQLデータベースに限定されません。リレーショナルデータベースでさえ、さまざまなデータ型を厳密なスキーマに標準化するのに苦労しています。
リレーショナルデータベースの内部動作は十分に文書化されており、予測可能です。 SQL言語とリレーショナルテクノロジを使用して作成されたツールのセットはどこにでもあり、経験豊富なスタッフがすぐに利用できます。リレーショナルデータベースモデルを使用すると、データの保存方法に制限されることなく、さまざまな創造的な方法でデータにアクセスできます。
ビッグデータ
ビッグデータとそれを技術的に可能な限りキャプチャすることの価値は、リレーショナルモデルに適したワークロードではありません。厳密なスキーマを使用しないNoSQLデータベースは、大量の分類された非構造化データを格納するための優れた選択肢です。
ソフトウェア開発
アプリケーション開発は、NoSQLデータベースから劇的な恩恵を受けています。メモリ内のデータ構造とリレーショナルデータベースの間でデータをマッピングするために、多くの貴重な開発者の時間が無駄になりました。 NoSQLデータベースとは、モデルにアクセスするアプリケーションのニーズに合わせてモデルを作成し、必要なコーディング量を削減できることを意味します。
データベースにスキーマがない場合は、データにアクセスするアプリケーションにスキーマが必要であることを意味します。互いに独立して開発された複数のアプリケーションが同じデータベースにアクセスする必要がある場合、これはすぐに問題になる可能性があります。
読み取りの不整合は最終的には解決されますが、書き込みの整合性の欠如は深刻な問題です。この問題は、多くの場合、単一のアプリケーション内のすべてのデータベースの相互作用を制限し、Webサービスを使用して他のアプリケーションと統合することで解決されます。このソリューションは、統合の目的でWebサービスを使用するという一般的な傾向とよく関連しています。