はじめに
Spark DataFrameは、分散ビッグデータ処理を簡素化するための使いやすいAPIを備えた統合データ構造です。 DataFrameは、Java、Python、Scalaなどの汎用プログラミング言語で使用できます。
これは、強力でありながらコードをより効率的に記述できるように最適化されたSparkRDDAPIの拡張機能です。
この記事では、Spark DataFrameとは何か、機能、およびデータを収集する際のSparkDataFrameの使用方法について説明します。

前提条件
- Sparkがインストールおよび構成されています(ガイド:UbuntuにSparkをインストールする方法、Windows 10にSparkをインストールする方法に従ってください)。
- Java、Python、またはScalaでSparkを使用するように構成された環境(このガイドではPythonを使用します)。
DataFrameとは何ですか?
DataFrameは、SparkSQLモジュールのプログラミング抽象化です。 DataFrameは、リレーショナルデータベーステーブルに似ているか、ヘッダー付きのExcelスプレッドシートに似ています。データは、さまざまなデータ型の行と列に存在します。
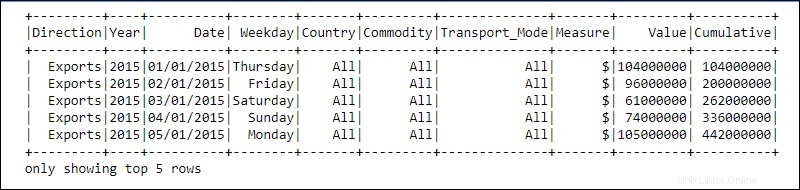
処理は、複雑なユーザー定義関数と、並べ替え、結合、グループ化などの使い慣れたデータ操作関数を使用して実現されます。
分散データの情報は、スキーマに構造化されています。 。 DataFrameのすべての列には、列 name が含まれています 、データ型、 およびnull許容 プロパティ。 null許容の場合 trueに設定されています 、列は nullを受け入れます プロパティも。

DataFrameはどのように機能しますか?
DataFrame APIは、SparkSQLモジュールの一部です。 APIは、Java、Python、Scalaなどの汎用言語と統合しながら、SparkSQLフレームワーク内でデータを操作する簡単な方法を提供します。
Python PandasとRデータフレームには類似点がありますが、Sparkは別のことをします。このAPIは、データサイエンスや機械学習のために大規模なデータと統合するように調整されており、多数の最適化をもたらします。
Spark DataFrameは複数のクラスターに分散可能であり、Catalystで最適化されています。 Catalystオプティマイザーはクエリ(DataFrameに適用されるSQLコマンドを含む)を受け取り、最適な並列計算プランを作成します。
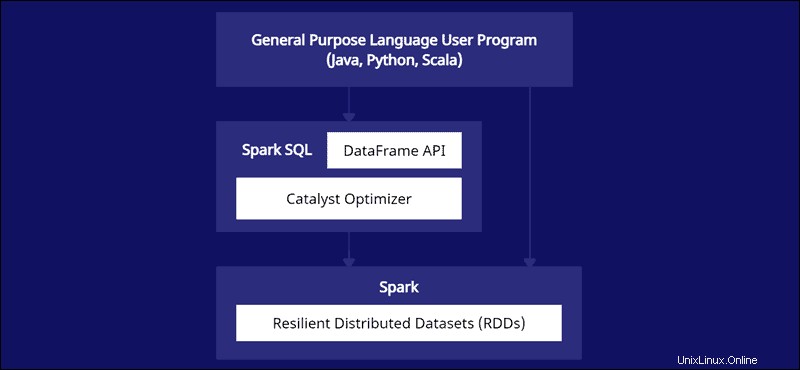
PythonとRのデータフレームの経験がある場合、SparkDataFrameコードは見覚えがあります。一方、Spark RDD(Resilient Distributed Dataset)を使用する場合、データ構造に関する情報があると、最適化の機会が得られます。
Sparkの作成者は、ビッグデータの課題に最も効率的な方法で取り組むためにDataFrameを設計しました。開発者は、使い慣れた、より最適化されたAPIを使用して、分散コンピューティングのパワーを活用できます。
SparkDataFrameの機能
Spark DataFrameには、多くの価値ある機能が付属しています。
- Hive、CSV、XML、JSON、RDD、Cassandra、Parquetなどのさまざまなデータ形式のサポート
- さまざまなビッグデータツールとの統合のサポート。
- 小規模なマシンではキロバイト、クラスターではペタバイトのデータを処理する機能。
- 複数の言語にわたる効率的なデータ処理のためのCatalystオプティマイザー。
- データのスケマティックビューによる構造化されたデータ処理。
- RDDと比較して過負荷を減らしパフォーマンスを向上させるカスタムメモリ管理。
- Java、R、Python、Spark用のAPI。
Spark DataFrameを作成するには?
SparkDataFrameを作成する方法は複数あります。 Jupyterノートブック環境を使用してPythonで作成する方法の例を次に示します。
1. APIセッションを初期化して作成します:
#Add pyspark to sys.path and initialize
import findspark
findspark.init()
#Load the DataFrame API session into Spark and create a session
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()2.辞書のリストとしておもちゃのデータを作成します:
#Generate toy data using a dictionary list
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
3. createDataFrameを使用してDataFrameを作成します 関数を実行し、dataを渡します リスト:
#Create a DataFrame from the data list
df = spark.createDataFrame(data)4.スキーマとテーブルを印刷して、作成されたDataFrameを表示します。
#Print the schema and view the DataFrame in table format
df.printSchema()
df.show()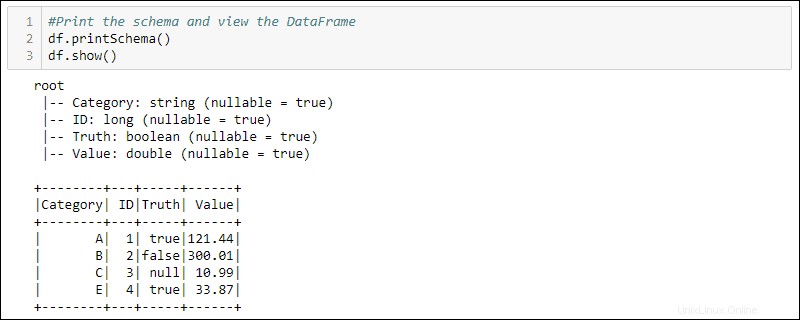
データフレームの使用方法
DataFrameに格納された構造化データは、2つの操作方法を提供します
- ドメイン固有言語の使用
- SQLクエリの使用。
次の2つの方法では、前の例のDataFrameを使用して、Truth列がtrueに設定されているすべての行を選択し、Value列でデータを並べ替えます。
方法1:ドメイン固有のクエリを使用する
Pythonには、データをフィルタリングおよび並べ替えるための組み込みメソッドが用意されています。 df.<column name>を使用して特定の列を選択します :
df.filter(df.Truth == True).sort(df.Value).show()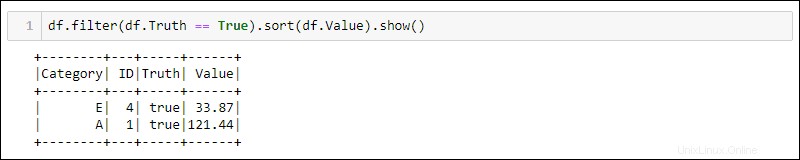
方法2:SQLクエリの使用
DataFrameでSQLクエリを使用するには、 createOrReplaceTempViewでビューを作成します 組み込みメソッドを使用し、 spark.sqlを使用してSQLクエリを実行します 方法:
df.createOrReplaceTempView('table')
spark.sql('''SELECT * FROM table WHERE Truth=true ORDER BY Value ASC''')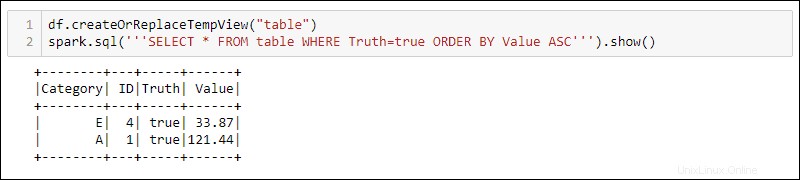
出力には、DataFrameの一時ビューに適用されたSQLクエリの結果が表示されます。これにより、複雑なデータ処理のために同じデータに対して複数のビューとクエリを作成できます。