はじめに
HDFS (Hadoop分散ファイルシステム)は、ApacheHadoopプロジェクトの重要なコンポーネントです。 Hadoopは、ビッグデータの管理を支援するために連携するソフトウェアのエコシステムです。 Hadoopの2つの主要な要素は次のとおりです。
- MapReduce –タスクの実行を担当します
- HDFS –データの維持に責任を負います
この記事では、2つのモジュールの2番目について説明します。 学ぶ HDFSとは何か、その仕組み、および基本的なHDFS用語 。

HDFSとは何ですか?
Hadoop分散ファイルシステムは、コモディティハードウェアで実行されるフォールトトレラントなデータストレージファイルシステムです。これは、従来のデータベースでは不可能だった課題を克服するために設計されました。したがって、その可能性を最大限に活用するのは、ビッグデータを処理する場合のみです。
Hadoopファイルシステムが解決しなければならなかった主な問題は速度でした 、コスト 、および信頼性 。
HDFSのメリットは何ですか?
実際、HDFSの利点は、ファイルシステムが前述の課題に対して提供するソリューションです。
- 高速です。 クラスタアーキテクチャのおかげで、1秒あたり2GBを超えるデータを配信できます。
- 無料です。 HDFSは、ライセンスやサポートの費用がかからないオープンソースソフトウェアです。
- 信頼できます。 ファイルシステムは、データの複数のコピーを別々のシステムに保存して、常にアクセスできるようにします。
これらの利点は、ビッグデータを処理する場合に特に重要であり、HDFSがデータを処理する特定の方法で可能になりました。
HDFSはどのようにデータを保存しますか?
HDFSはファイルをブロックに分割し、各ブロックをDataNodeに保存します。複数のDataNodeは、クラスター内のマスターノードであるNameNodeにリンクされています。マスターノードは、これらのデータブロックのレプリカをクラスター全体に分散します。また、必要な情報の場所をユーザーに指示します。
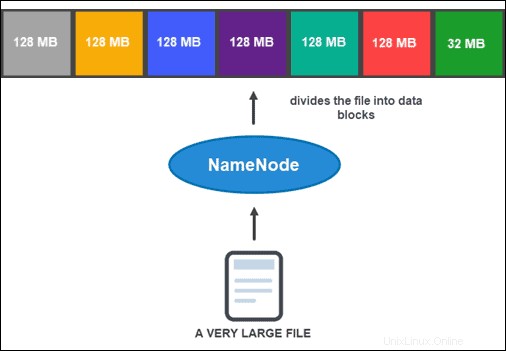
ただし、NameNodeがデータの保存と管理に役立つ前に、まずファイルをより小さく管理しやすいデータブロックに分割する必要があります。このプロセスはデータブロック分割と呼ばれます 。
データブロック分割
デフォルトでは、ブロックのサイズは128MB以下にすることができます。ブロック数は、ファイルの初期サイズによって異なります。最後のブロックを除くすべてが同じサイズ(128 MB)ですが、最後のブロックはファイルの残りの部分です。
たとえば、800MBのファイルは7つのデータブロックに分割されます。 7つのブロックのうち6つは128MBで、7番目のデータブロックは残りの32MBです。
次に、各ブロックが複数のコピーに複製されます。
データレプリケーション
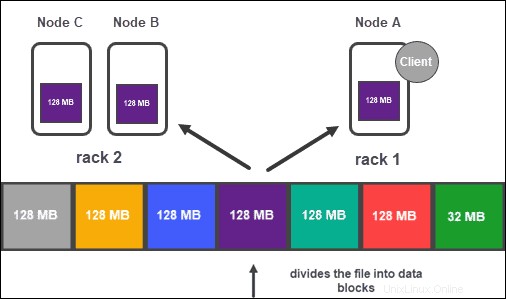
クラスタの構成に基づいて、NameNodeはレプリケーション方法を使用して各データブロックのコピーをいくつか作成します。 。
少なくとも3つのレプリカを用意することをお勧めします。これは、デフォルト設定でもあります。マスターノードは、それらをクラスターの個別のDataNodeに格納します。ノードの状態は綿密に監視され、データが常に利用可能であることを確認します。
高いアクセシビリティ、信頼性、およびフォールトトレランスを確保するために、開発者は次のトポロジを使用して3つのレプリカを設定することをお勧めします。
- 最初のレプリカを保存します クライアントが配置されているノード上。
- 次に、2番目のレプリカを保存します 別のラックにあります。
- 最後に、3番目のレプリカを保存します 2番目のレプリカと同じラックにありますが、ノードが異なります。
HDFSアーキテクチャ:NameNodesとDataNodes
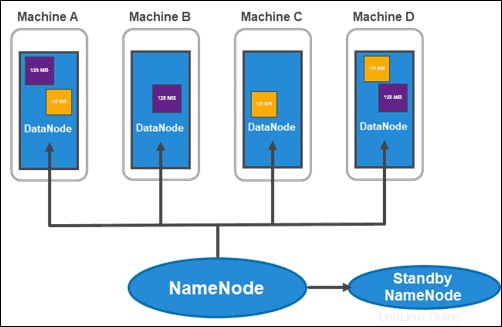
HDFSにはマスタースレーブアーキテクチャがあります。マスターノードはNameNode 、 DataNodesと呼ばれるクラスター内の複数のスレーブノードを管理します 。
NameNodes
Hadoop 2.xでは、ラックごとに複数のNameNodeを持つ可能性が導入されました。クラスター内のすべての情報を含む単一のマスターノードを持つことは大きな脆弱性をもたらすため、この目新しさは非常に重要でした。
通常のクラスターは2つのNameNodeで構成されています:
- アクティブなNameNode
- およびスタンバイNameNode
1つ目はクラスター内のすべてのクライアント操作を処理しますが、2つ目はフェイルオーバーが必要な場合にすべての作業と同期を保ちます。
アクティブなNameNode 各データブロックとそのレプリカのメタデータを追跡します。これには、ファイル名、権限、ID、場所、およびレプリカの数が含まれます。すべての情報をfsimageに保持します 、ファイルシステムのローカルメモリに保存されている名前空間イメージ。さらに、 EditLogsと呼ばれるトランザクションログを維持します 、システムで行われたすべての変更を記録します。
Stanby NameNodeの主な目的 単一障害点の問題を解決することです。 EditLogsに加えられた変更を読み取り、それを NameSpaceに適用します。 (データ内のファイルとディレクトリ)。マスターノードに障害が発生した場合、Zookeeperサービスはフェイルオーバーを実行し、スタンバイがアクティブなセッションを維持できるようにします。
DataNodes
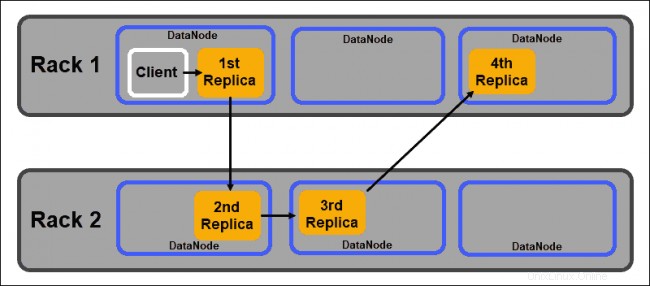
DataNodeは、NameNodeによって割り当てられたデータブロックを格納するスレーブデーモンです。上記のように、デフォルト設定では、各データブロックに3つのレプリカがあります。レプリカの数は変更できますが、3つ未満にすることはお勧めしません。
レプリカは、Hadoopのラック認識に従って配布する必要があります 次の点に注意するポリシー:
- レプリカの数は、ラックの数よりも多くする必要があります。
- 1つのDataNodeはデータブロックのレプリカを1つだけ保存できます。
- 1つのラックにデータブロックのレプリカを3つ以上保存することはできません。
これらのガイドラインに従うことで、次のことができます。
- ネットワーク帯域幅を最大化します。
- データの損失から保護します。
- パフォーマンスと信頼性を向上させます。
HDFSの主な機能
Hadoop分散ファイルシステムの主な特徴は次のとおりです。
1。ビッグデータを管理します。 HDFSは、大規模なデータセットの処理に優れており、従来のファイルシステムでは不可能だったソリューションを提供します。これは、データを管理可能なブロックに分離することで実現され、処理時間を短縮できます。
2。ラック対応。 これは、システムの高可用性と効率性を保証するラック認識のガイドラインに従います。
3。耐障害性。 データは複数のラックとノードに保存されるため、複製されます。これは、クラスター内のいずれかのマシンに障害が発生した場合、そのデータのレプリカが別のノードから利用できることを意味します。
4。スケーラブル。 ファイルシステムのサイズに応じてリソースをスケーリングできます。 HDFSには、垂直および水平のスケーラビリティメカニズムが含まれています。
HDFSの実際の使用法
大量のデータを扱う企業は、ストレージと分析機能により、ビッグデータを処理するための主要なソリューションの1つであるHadoopへの移行を長い間開始してきました。
金融サービス。 Hadoop分散ファイルシステムは、指数関数的に増大すると予想されるデータをサポートするように設計されています。このシステムは、複雑なデータ処理を遅くする危険なしにスケーラブルです。
小売。 顧客を知ることは小売業界で成功するための重要な要素であるため、多くの企業は構造化および非構造化の顧客データを大量に保持しています。彼らはHadoopを使用して収集されたデータを追跡および分析し、将来の在庫、価格設定、マーケティングキャンペーン、およびその他のプロジェクトの計画に役立てます。
電気通信。 電気通信業界は大量のデータを管理しており、ペタバイト規模で処理する必要があります。 Hadoop分析を使用して、通話データレコード、ネットワークトラフィック分析、およびその他の通信関連プロセスを管理します。
エネルギー産業。 エネルギー業界は、エネルギー効率を改善する方法を常に探しています。消費パターンと慣行の分析と理解を支援するために、Hadoopやそのファイルシステムなどのシステムに依存しています。
保険。 医療保険会社はデータ分析に依存しています。これらの結果は、ポリシーを策定および実装する方法の基礎として機能します。保険会社にとって、顧客の歴史に対する洞察は非常に貴重です。継続的に成長しながら、簡単にアクセスできるデータベースを維持できるため、多くの人がApacheHadoopを利用しています。