はじめに
Spark DataFrameの作成方法を学ぶことは、Spark環境での最初の実用的なステップの1つです。 Spark DataFramesは、データ構造およびその他のデータ操作機能のビューを提供するのに役立ちます。ファイルのデータソースとデータストレージ形式に応じて、さまざまな方法があります。
この記事では、PySparkを使用してPythonでSparkDataFrameを手動で作成する方法について説明します。

前提条件
- Python3がインストールおよび構成されています。
- PySparkがインストールおよび構成されています。
- コード例をテストする準備ができているPython開発環境(Jupyter Notebookを使用しています)。
SparkDataFrameの作成方法
SparkでDataFrameを手動で作成する方法は3つあります。
1.リストを作成し、 toDataFrame()を使用してDataFrameとして解析します SparkSessionのメソッド 。
2. toDF()を使用してRDDをDataFrameに変換します メソッド。
3.ファイルをSparkSessionにインポートします DataFrameとして直接。
例では、デモンストレーションにサンプルデータとRDDを使用していますが、一般的な原則は同様のデータ構造に適用されます。
データのリストからDataFrameを作成する
データのリストからSparkDataFrameを作成するには:
1.おもちゃのデータを含むサンプル辞書リストを生成します:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
2. SparkSessionをインポートして作成します :
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
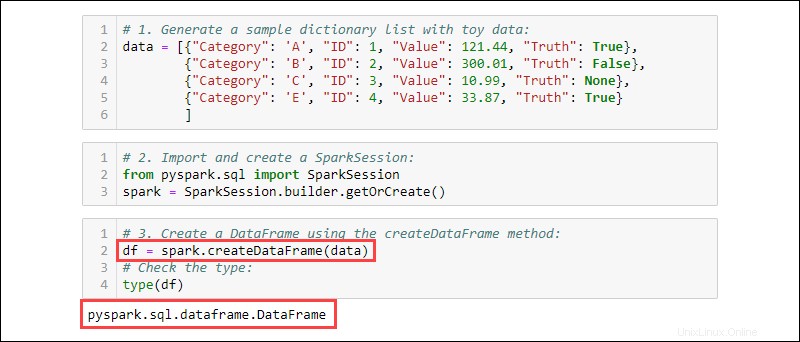
3. createDataFrameを使用してDataFrameを作成します 方法。データ型をチェックして、変数がDataFrameであることを確認します:
df = spark.createDataFrame(data)
type(df)
RDDからDataFrameを作成する
Sparkで作業するときの一般的なイベントは、既存のRDDからDataFrameを作成することです。サンプルRDDを作成し、それをDataFrameに変換します。
1.おもちゃのデータを含む辞書リストを作成します:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
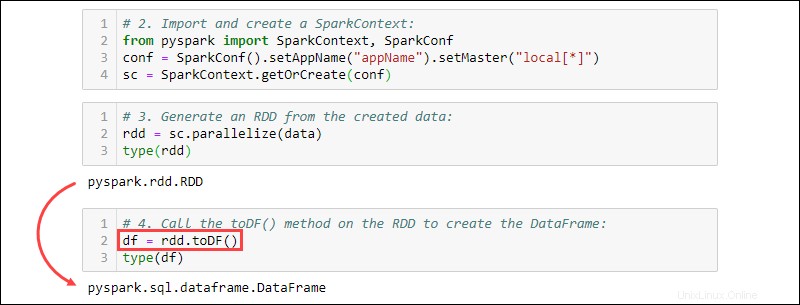
2. SparkContextをインポートして作成します :
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("projectName").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
3.作成したデータからRDDを生成します。タイプをチェックして、オブジェクトがRDDであることを確認します:
rdd = sc.parallelize(data)
type(rdd)
4. toDF()を呼び出します DataFrameを作成するためのRDDのメソッド。オブジェクトタイプをテストして確認します:
df = rdd.toDF()
type(df)
データソースからDataFrameを作成する
Sparkは、さまざまな外部データソースを処理して、DataFrameを構築できます。ファイルから読み取るための一般的な構文は次のとおりです。
spark.read.format('<data source>').load('<file path/file name>')データソース名とパスはどちらも文字列型です。特定のデータソースには、ファイルをDataFrameとしてインポートするための代替構文もあります。
CSVファイルから作成
CSVファイルから直接読み取ってSparkDataFrameを作成します:
df = spark.read.csv('<file name>.csv')パスのリストを提供して、複数のCSVファイルを1つのDataFrameに読み込みます。
df = spark.read.csv(['<file name 1>.csv', '<file name 2>.csv', '<file name 3>.csv'])
デフォルトでは、Sparkは各列にヘッダーを追加します。 CSVファイルに含めるヘッダーがある場合は、optionを追加します インポート時のメソッド:
df = spark.read.csv('<file name>.csv').option('header', 'true')
個々のオプションは、次々に呼び出すことでスタックします。または、optionを使用します インポート中にさらにオプションが必要な場合の方法:
df = spark.read.csv('<file name>.csv').options(header = True)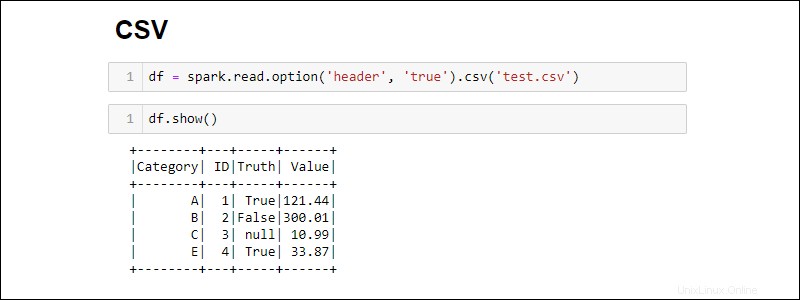
使用時の構文が異なることに注意してください option 対option 。
TXTファイルからの作成
次のテキストファイルからDataFrameを作成します:
df = spark.read.text('<file name>.txt')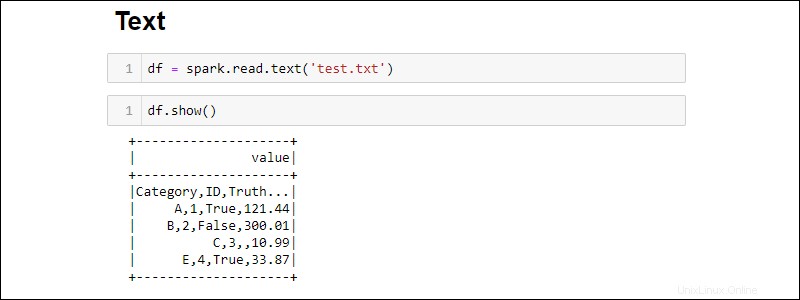
csv メソッドは、 txtから読み取るもう1つの方法です。 DataFrameへのファイルタイプ。例:
df = spark.read.option('header', 'true').csv('<file name>.txt')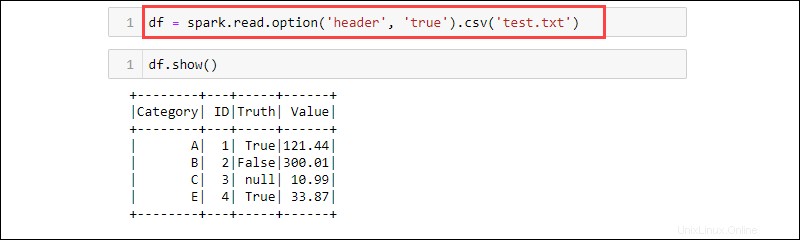
CSVはテキスト形式であり、区切り文字はコンマ(、)であるため、関数はテキストファイルからデータを読み取ることができます。
JSONファイルからの作成
次のコマンドを実行して、JSONファイルからSparkDataFrameを作成します。
df = spark.read.json('<file name>.json')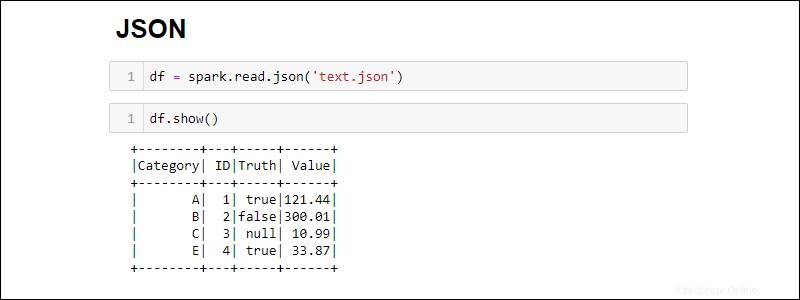
XMLファイルからの作成
XMLファイルの互換性はデフォルトでは利用できません。依存関係をインストールして、XMLソースからDataFrameを作成します。
1.SparkXML依存関係をダウンロードします。 .jarを保存します Sparkjarフォルダー内のファイル。
2.次のコマンドを実行してXMLファイルをDataFrameに読み込みます。
df = spark.read\
.format('com.databricks.spark.xml')\
.option('rowTag', 'row')\
.load('test.xml')
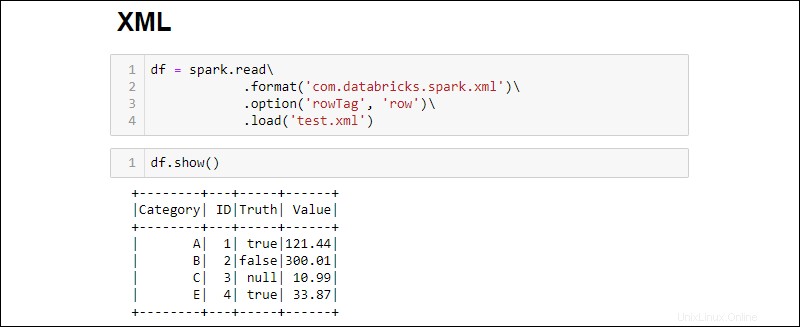
rowTagを変更します XMLの各行のオプション ファイルのラベルは異なります。
RDBMSデータベースからDataFrameを作成する
RDBMSから読み取るには、ドライバーコネクタが必要です。この例では、MySQLデータベースに接続してデータをプルする方法について説明します。他の種類のデータベースでも同様の手順が機能します。
1. MySQLJavaDriverコネクタをダウンロードします。 .jarを保存します Sparkjarフォルダー内のファイル。
2. SQLサーバーを実行し、接続を確立します。
3.接続を確立し、MySQLデータベーステーブル全体をDataFrameにフェッチします。
df = spark.read\
.format('jdbc')\
.option('url', 'jdbc:mysql://localhost:3306/db')\
.option('driver', 'com.mysql.jdbc.Driver')\
.option('dbtable','new_table')\
.option('user','root')\
.load()
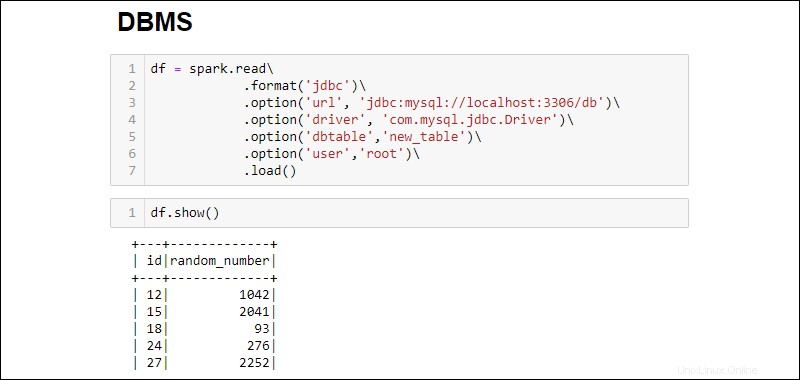
追加されたオプションは次のとおりです。
- URL
localhost:3306です サーバーがローカルで実行されている場合。それ以外の場合は、データベースサーバーのURLを取得します。 - データベース名 サーバー上の特定のデータベースにアクセスするためにURLを拡張します。たとえば、データベースの名前が
dbの場合 サーバーがローカルで実行されている場合、接続を確立するための完全なURLはjdbc:mysql://localhost:3306/dbです。 。 - テーブル名 データベーステーブル全体がDataFrameにプルされるようにします。
.option('query', '<query>')を使用します.option('dbtable', '<table name>')の代わりに テーブル全体を選択する代わりに、特定のクエリを実行します。 - ユーザー名を使用 およびパスワード 接続を確立するためのデータベースの。パスワードなしで実行する場合は、指定されたオプションを省略してください。