はじめに
今日、ビッグデータ処理のための無料のソリューションがたくさんあります。多くの企業は、オープンソースプラットフォームを補完するための特殊なエンタープライズ機能も提供しています。
この傾向は、1999年にApacheLuceneの開発から始まりました。フレームワークはすぐにオープンソースになり、Hadoopの作成につながりました。現在使用されている最も人気のあるビッグデータ処理フレームワークの2つは、オープンソースです。ApacheHadoopとApacheSparkです。
使用するフレームワーク、Hadoop、またはSparkについては常に質問があります。
この記事では、を学びます HadoopとSparkの主な違い そして、どちらかを選択するか、それらを一緒に使用する必要がある場合。

注 :HadoopとSparkを直接比較する前に、これら2つのフレームワークについて簡単に説明します。
Hadoopとは何ですか?
Apache Hadoopは、大規模なデータセットを分散して処理するプラットフォームです。フレームワークはMapReduceを使用します データをブロックに分割し、クラスター全体のノードにチャンクを割り当てます。次に、MapReduceは各ノードでデータを並列処理して、一意の出力を生成します。
クラスタ内のすべてのマシンは、データの保存と処理の両方を行います。 Hadoopは、 HDFSを使用してデータをディスクに保存します 。このソフトウェアは、シームレスなスケーラビリティオプションを提供します。最小1台のマシンから始めて、数千台に拡張し、あらゆるタイプのエンタープライズまたはコモディティハードウェアを追加できます。
Hadoopエコシステムは、フォールトトレラント性が高くなっています。 Hadoopは、高可用性を実現するためにハードウェアに依存しません。基本的に、Hadoopは、アプリケーション層で障害を探すように構築されています。クラスタ全体でデータを複製することにより、ハードウェアの一部に障害が発生した場合、フレームワークは不足している部分を別の場所から構築できます。
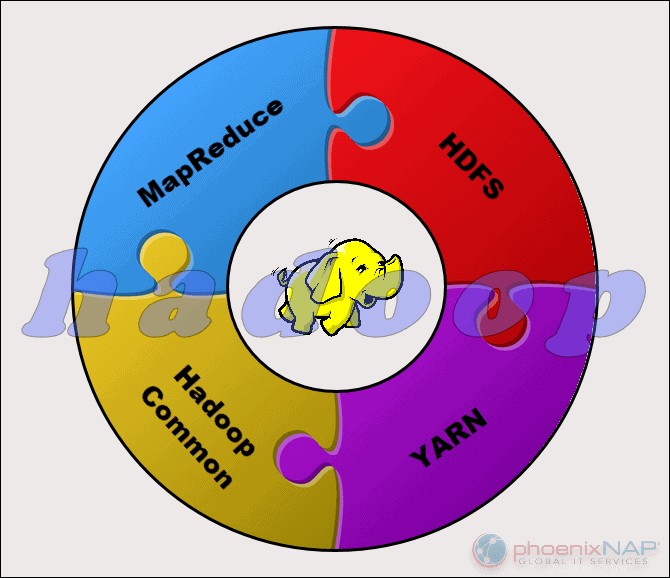
Apache Hadoopプロジェクトは、次の4つの主要モジュールで構成されています。
- HDFS – Hadoop分散ファイルシステム。これは、Hadoopクラスター全体の大量のデータセットのストレージを管理するファイルシステムです。 HDFSは、構造化データと非構造化データの両方を処理できます。ストレージハードウェアは、あらゆる民生用HDDからエンタープライズドライブまでさまざまです。
- MapReduce。 Hadoopエコシステムの処理コンポーネント。 HDFSからのデータフラグメントをクラスター内の個別のマップタスクに割り当てます。 MapReduceはチャンクを並行して処理し、ピースを組み合わせて目的の結果にします。
- ヤーン。 さらに別のリソースネゴシエーター。コンピューティングリソースとジョブスケジューリングの管理を担当します。
- Hadoop共通。 他のモジュールが依存する共通ライブラリとユーティリティのセット。このモジュールの別名は、他のすべてのHadoopコンポーネントをサポートするHadoopコアです。
Hadoopの性質により、Hadoopを必要とするすべての人がHadoopにアクセスできます。オープンソースコミュニティは大きく、アクセス可能なビッグデータ処理への道を開いています。
Sparkとは何ですか?
ApacheSparkはオープンソースツールです。このフレームワークは、スタンドアロンモードで実行することも、ApacheMesosなどのクラウドまたはクラスターマネージャーやその他のプラットフォームで実行することもできます。 高速パフォーマンス用に設計されており、RAMを使用します データのキャッシュと処理用。
Sparkは、さまざまなタイプのビッグデータワークロードを実行します。これには、MapReduceのようなバッチ処理のほか、リアルタイムストリーム処理、機械学習、グラフ計算、インタラクティブクエリが含まれます。使いやすい高レベルAPIを使用して、Sparkは PyTorchを含む多くの異なるライブラリと統合できます。 およびTensorFlow。これら2つのライブラリの違いについては、PyTorchとTensorFlowに関する記事をご覧ください。
Sparkエンジンは、MapReduceの効率を改善し、その利点を維持するために作成されました。 Sparkにはファイルシステムがありませんが、さまざまなストレージソリューションのデータにアクセスできます。 Sparkが使用するデータ構造は、復元力のある分散データセットと呼ばれます。 、またはRDD。
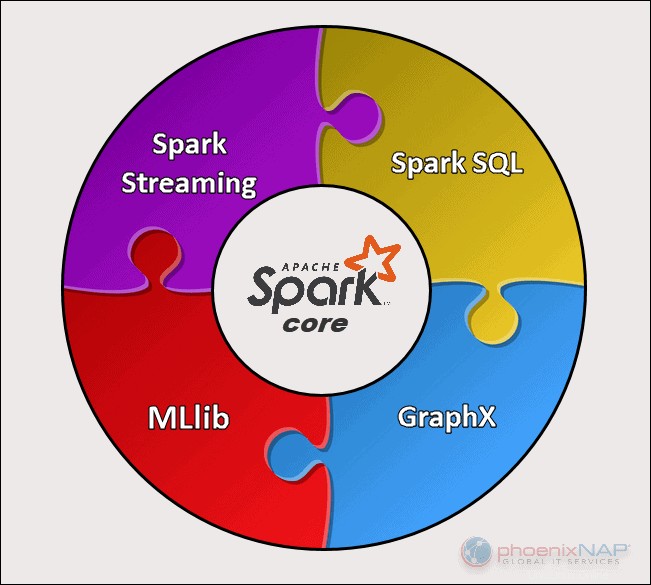
ApacheSparkには5つの主要なコンポーネントがあります:
- Apache Spark Core 。プロジェクト全体の基礎。 Spark Coreは、スケジューリング、タスクディスパッチ、入出力操作、障害回復などの必要な機能を担当します。その他の機能は、その上に構築されています。
- SparkStreaming。このコンポーネントは、ライブデータストリームの処理を可能にします。データは、Kafka、Kinesis、Flumeなどのさまざまなソースから発信できます。
- スパークSQL 。 Sparkはこのコンポーネントを使用して、構造化データとデータの処理方法に関する情報を収集します。
- 機械学習ライブラリ(MLlib) 。このライブラリは、多くの機械学習アルゴリズムで構成されています。 MLlibの目標は、スケーラビリティと機械学習をより利用しやすくすることです。
- GraphX 。グラフ分析タスクを容易にするために使用される一連のAPI。
HadoopとSparkの主な違い
次のセクションでは、2つのフレームワークの主な相違点と類似点について概説します。 HadoopとSparkをさまざまな角度から見ていきます。
これらのいくつかはコストです 、パフォーマンス 、セキュリティ 、および使いやすさ 。
次の表は、次のセクションで行われた結論の概要を示しています。
HadoopとSparkの比較
| 比較用のカテゴリ | Hadoop | スパーク |
| パフォーマンス | パフォーマンスが低下し、ストレージにディスクを使用し、ディスクの読み取りおよび書き込み速度に依存します。 | ディスクの読み取りおよび書き込み操作が削減された、メモリ内の高速パフォーマンス。 |
| コスト | オープンソースプラットフォームであり、実行コストが低くなります。手頃な価格の消費者向けハードウェアを使用しています。訓練を受けたHadoopの専門家を見つけやすくなります。 | オープンソースプラットフォームですが、計算はメモリに依存しているため、ランニングコストが大幅に増加します。 |
| データ処理 | バッチ処理に最適です。 MapReduceを使用して、並列分析のためにクラスター全体で大きなデータセットを分割します。 | 反復およびライブストリームデータ分析に適しています。 RDDおよびDAGと連携して、操作を実行します。 |
| フォールトトレランス | フォールトトレラント性の高いシステム。ノード間でデータを複製し、問題が発生した場合にそれらを使用します。 | RDDブロックの作成プロセスを追跡し、パーティションに障害が発生したときにデータセットを再構築できます。 SparkはDAGを使用して、ノード間でデータを再構築することもできます。 |
| スケーラビリティ | ストレージ用のノードとディスクを追加することで、簡単に拡張できます。既知の制限なしで数万のノードをサポートします。 | 計算をRAMに依存しているため、スケーリングが少し難しくなります。クラスタ内の数千のノードをサポートします。 |
| セキュリティ | 非常に安全です。 LDAP、ACL、Kerberos、SLAなどをサポートします。 | 安全ではありません。デフォルトでは、セキュリティはオフになっています。必要なセキュリティレベルを達成するために、Hadoopとの統合に依存しています。 |
| 使いやすさと 言語サポート | サポートされていない言語では使用がより困難になります。 MapReduceアプリにJavaまたはPythonを使用します。 | よりユーザーフレンドリー。インタラクティブシェルモードを許可します。 APIは、Java、Scala、R、Python、SparkSQLで記述できます。 |
| 機械学習 | Sparkより遅い。データフラグメントが大きすぎてボトルネックになる可能性があります。マハウトはメインライブラリです。 | インメモリ処理を使用すると、はるかに高速になります。計算にMLlibを使用します。 |
| スケジューリングとリソース管理 | 外部ソリューションを使用します。 YARNは、リソース管理の最も一般的なオプションです。 Oozieはワークフローのスケジューリングに使用できます。 | リソースの割り当て、スケジューリング、および監視のための組み込みツールがあります。 |
パフォーマンス
データの処理方法の観点からHadoopとSparkを比較すると 、2つのフレームワークのパフォーマンスを比較するのは自然に見えないかもしれません。それでも、線を引いて、どのツールが高速であるかを明確に把握することができます。
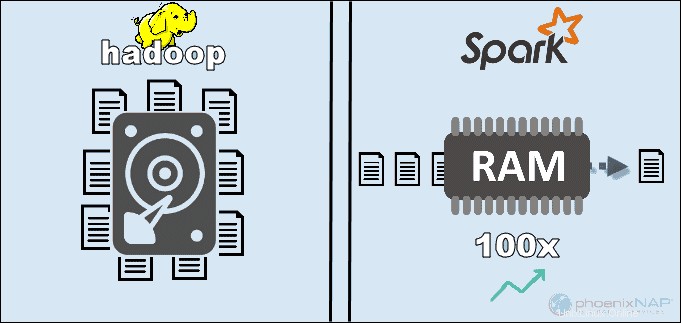
Hadoopは、HDFSにローカルに保存されているデータにアクセスすることで、全体的なパフォーマンスを向上させます。ただし、Sparkのメモリ内処理とは一致しません。 Apacheの主張によると、コンピューティングにRAMを使用する場合、MapReduceでHadoopを使用する場合よりもSparkの方が100倍高速であるように見えます。
優位性は、ディスク上のデータの並べ替えにとどまりました。 Sparkは3倍高速で、HDFSで100TBのデータを処理するために必要なノードは10分の1でした。このベンチマークは、2014年に世界記録を樹立するのに十分でした。
このSparkの優位性の主な理由は、中間データの読み取りとディスクへの書き込みを行わず、RAMを使用することです。 Hadoopはさまざまなソースにデータを保存し、MapReduceを使用してデータをバッチで処理します。
上記のすべてがSparkを絶対的な勝者として位置付ける可能性があります。ただし、データのサイズが使用可能なRAMよりも大きい場合は、Hadoopの方が論理的な選択です。考慮すべきもう1つのポイントは、これらのシステムの実行コストです。
コスト
コストを考慮してHadoopとSparkを比較すると、ソフトウェアの価格よりも深く掘り下げる必要があります。どちらのプラットフォームもオープンソースです 完全に無料です。それでも、大まかな総所有コスト(TCO)を取得するには、インフラストラクチャ、メンテナンス、および開発のコストを考慮する必要があります。
コストカテゴリで最も重要な要素は、これらのツールを実行するために必要な基盤となるハードウェアです。 Hadoopはあらゆる種類のディスクストレージに依存しているため データ処理の場合、実行コストは比較的低くなります。
一方、Sparkはメモリ内の計算に依存します リアルタイムデータ処理用。そのため、大量のRAMを搭載したノードを起動すると、所有コストが大幅に増加します。
もう1つの懸念は、アプリケーション開発です。 HadoopはSparkよりも長く使用されており、ソフトウェア開発者を見つけるのはそれほど難しくありません。
上記のポイントは、Hadoopインフラストラクチャの方が費用効果が高いことを示しています。 。このステートメントは正しいですが、Sparkはデータをはるかに高速に処理することに注意する必要があります。したがって、同じタスクを完了するために必要なマシンの数は少なくなります。
データ処理
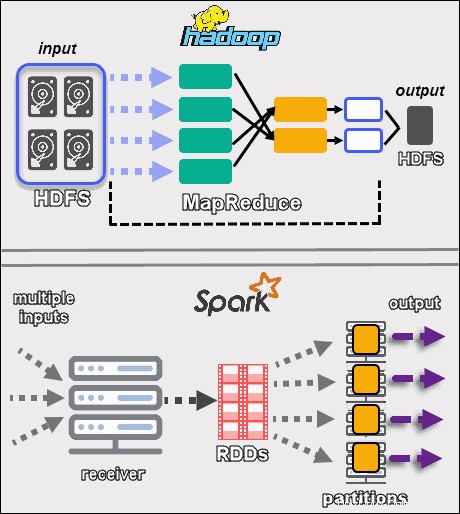
2つのフレームワークはまったく異なる方法でデータを処理します 。 MapReduceを使用したHadoopとRDDを使用したSparkはどちらも分散環境でデータを処理しますが、Hadoopはバッチ処理に適しています。対照的に、Sparkはリアルタイム処理で輝いています。
Hadoopの目標は、データをディスクに保存し、分散環境全体でバッチで並行して分析することです。 MapReduceは、大量のデータを処理するために大量のRAMを必要としません。 Hadoopは、ストレージを日常のハードウェアに依存しており、線形データ処理に最適です。
ApacheSparkは復元力のある分散データセットで動作します (RDD )。 RDDは、クラスター全体のノード上のパーティションに格納されている要素の分散セットです。 RDDのサイズは通常、1つのノードで処理するには大きすぎます。したがって、SparkはRDDを最も近いノードに分割し、操作を並行して実行します。システムは、有向非巡回グラフを使用して、RDDで実行されたすべてのアクションを追跡します。 ( DAG 。
インメモリ計算と高レベルAPIにより、Sparkは非構造化データのライブストリームを効果的に処理します。さらに、データは事前定義された数のパーティションに保存されます。 1つのノードに必要な数のパーティションを含めることはできますが、1つのパーティションを別のノードに拡張することはできません。
フォールトトレランス
フォールトトレランスカテゴリのHadoopとSparkについて言えば、どちらもかなりのレベルの処理障害を提供しますと言えます。 。また、フォールトトレランスへのアプローチ方法も異なると言えます。
Hadoopには、その動作の基礎としてフォールトトレランスがあります。ノード間でデータを何度も複製します。問題が発生した場合、システムは他の場所から欠落しているブロックを作成することによって作業を再開します。マスターノードは、すべてのスレーブノードのステータスを追跡します。最後に、スレーブノードがマスターからのpingに応答しない場合、マスターは保留中のジョブを別のスレーブノードに割り当てます。
SparkはRDDブロックを使用してフォールトトレランスを実現します。システムは、不変のデータセットがどのように作成されるかを追跡します。その後、問題が発生したときにプロセスを再開できます。 Sparkは、ワークフローのDAG追跡を使用して、クラスター内のデータを再構築できます。このデータ構造により、Sparkは分散データ処理エコシステムの障害を処理できます。
スケーラビリティ
このセクションでは、HadoopとSparkの間の境界線がぼやけます。 HadoopはHDFSを使用してビッグデータを処理します。データの量が急速に増加すると、Hadoopは需要に対応するために迅速に拡張できます。 Sparkにはファイルシステムがないため、データが大きすぎて処理できない場合は、HDFSに依存する必要があります。
クラスターは、ネットワークにサーバーを追加することで、コンピューティング能力を簡単に拡張および向上させることができます。その結果、両方のフレームワークのノード数が数千に達する可能性があります。各クラスターに追加できるサーバーの数と処理できるデータの量に明確な制限はありません。
確認された数の一部には、Spark環境の8000台のマシンが含まれます。 ペタバイトのデータで。 Hadoopクラスターについて言えば、数万台のマシンに対応することでよく知られています。 エクサバイトに近いデータです。
使いやすさとプログラミング言語のサポート
Sparkは、Hadoopほど多くの専門家がいない新しいフレームワークかもしれませんが、よりユーザーフレンドリーであることが知られています。対照的に、Sparkは複数の言語をサポートします 母国語(Scala)の隣:Java、Python、R、SparkSQL。これにより、開発者は好みのプログラミング言語を使用できます。
HadoopフレームワークはJavaに基づいています 。 MapReduceコードを作成するための2つの主要な言語は、JavaまたはPythonです。 Hadoopには、ユーザーを支援するためのインタラクティブモードがありません。ただし、PigおよびHiveツールと統合して、複雑なMapReduceプログラムの作成を容易にします。
複数の言語でのAPIのサポートに加えて、使いやすさのセクションでSparkが勝ちます そのインタラクティブモードで。 Sparkシェルを使用して、ScalaまたはPythonでインタラクティブにデータを分析できます。シェルはクエリに即座にフィードバックを提供するため、SparkはHadoopMapReduceよりも使いやすくなっています。
Sparkを優勢にするもう1つの点は、プログラマーが該当する場合に既存のコードを再利用できることです。そうすることで、開発者はアプリケーション開発時間を短縮できます。履歴データとストリームデータを組み合わせて、このプロセスをさらに効果的にすることができます。
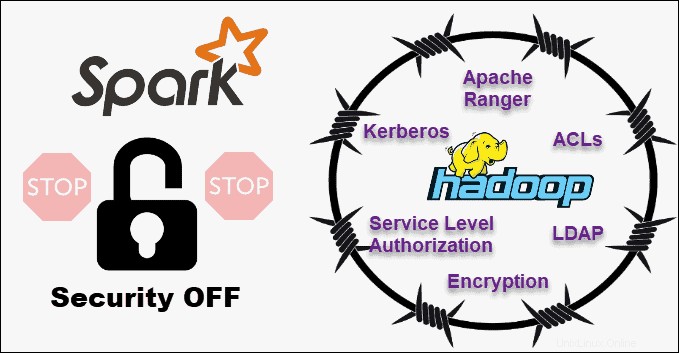
セキュリティ
HadoopとSparkのセキュリティを比較すると、猫はすぐにバッグから出されます–Hadoopが明らかに勝者です 。とりわけ、Sparkのセキュリティはデフォルトでオフになっています。これは、この問題に取り組まないと、セットアップが公開されることを意味します。
共有シークレットまたはイベントログを介した認証を導入することで、Sparkのセキュリティを向上させることができます。ただし、本番ワークロードにはそれだけでは不十分です。
対照的に、Hadoopは複数の認証およびアクセス制御方法で動作します。実装が最も難しいのはKerberos認証です。 Kerberosが多すぎて処理できない場合、Hadoopはレンジャーもサポートします 、 LDAP 、 ACL 、ノード間暗号化 、標準のファイル権限 HDFS、およびサービスレベル認証 。
ただし、SparkはHadoopと統合することで適切なレベルのセキュリティに到達できます 。このようにして、SparkはHadoopとHDFSで利用可能なすべてのメソッドを使用できます。さらに、SparkがYARNで実行される場合、上記の他の認証方法の利点を採用できます。
機械学習
機械学習は、インメモリコンピューティングを使用することで最も効果的に機能する反復プロセスです。このため、Sparkがより高速なソリューションであることが証明されました このエリアで。
この理由は、Hadoop MapReduceがジョブを並列タスクに分割し、機械学習アルゴリズムには大きすぎる可能性があるためです。このプロセスにより、これらのHadoopアプリケーションでI/Oパフォーマンスの問題が発生します。
Mahoutライブラリは、Hadoopクラスターの主要な機械学習プラットフォームです。 Mahoutは、クラスタリング、分類、および推奨を実行するためにMapReduceに依存しています。サムサラはこのプロジェクトに取って代わり始めました。
Sparkには、デフォルトの機械学習ライブラリであるMLlibが付属しています。このライブラリは、メモリ内のML計算を繰り返し実行します。回帰、分類、永続性、パイプラインの構築、評価などを実行するためのツールが含まれています。
MLlibを使用したSparkは、Hadoopディスクベースの環境でApacheMahoutよりも9倍高速であることが証明されました。 Hadoopが提供するものよりも効率的な結果が必要な場合は、機械学習にはSparkが適しています。
スケジューリングとリソース管理
Hadoopにはスケジューラーが組み込まれていません。リソース管理とスケジューリングに外部ソリューションを使用します。 ResourceManagerを使用 およびNodeManager 、YARNは、Hadoopクラスターのリソース管理を担当します。ワークフローのスケジューリングに使用できるツールの1つはOozieです。
YARNは、個々のアプリケーションの状態管理を扱いません。利用可能な処理能力のみを割り当てます。
Hadoop MapReduceは、 CapacitySchedulerなどのプラグインで動作します およびFairScheduler 。これらのスケジューラーは、クラスターの効率を維持しながら、アプリケーションが必要に応じて重要なリソースを確実に取得できるようにします。 FairSchedulerは、最終的にすべてのアプリケーションが同じリソース割り当てを取得することを追跡しながら、アプリケーションに必要なリソースを提供します。
一方、Sparkにはこれらの機能が組み込まれています。 DAGスケジューラ オペレーターをステージに分割する責任があります。すべてのステージには、DAGがスケジュールし、Sparkが実行する必要のある複数のタスクがあります。
SparkSchedulerとBlockManagerは、クラスター内でジョブとタスクのスケジューリング、監視、およびリソース分散を実行します。
HadoopとSparkのユースケース
上記のセクションでHadoopとSparkを比較すると、フレームワークごとにいくつかのユースケースを抽出できます。
Hadoopのユースケースは次のとおりです。
- データサイズが使用可能なメモリを超える環境で大規模なデータセットを処理する。
- 限られた予算でデータ分析インフラストラクチャを構築します。
- すぐに結果を出す必要がなく、時間が制限要因ではない場合に仕事を完了する。
- ディスクの読み取りおよび書き込み操作を利用するタスクとのバッチ処理。
- 履歴データとアーカイブデータの分析。
Sparkを使用すると、Hadoopよりも優れている次のユースケースを分離できます。
- リアルタイムストリームデータの分析。
- 時間が重要な場合、Sparkはメモリ内の計算で迅速な結果を提供します。
- 反復アルゴリズムを使用した並列操作のチェーンの処理。
- データをモデル化するためのグラフ並列処理。
- すべての機械学習アプリケーション。
注 :決定した場合は、UbuntuにHadoopをインストールする方法またはUbuntuにSparkをインストールする方法に関するガイドに従うことができます。 Windows 10で作業している場合は、Windows10にSparkをインストールする方法を参照してください。
HadoopまたはSpark?
HadoopとSparkは、ビッグデータを処理するためのテクノロジーです。それ以外は、データの管理と処理の方法がかなり異なるフレームワークです。
この記事の前のセクションによると、Sparkが明らかに勝者のようです。これはある程度真実かもしれませんが、実際には、それらは互いに競合するために作成されたのではなく、むしろ補完するために作成されています。
もちろん、この記事の前半でリストしたように、どちらかのフレームワークがより論理的な選択であるユースケースがあります。他のほとんどのアプリケーションでは、HadoopとSparkが最適に連携します 。後継者として、SparkはHadoopに取って代わるものではなく、その機能を使用して新しい改善されたエコシステムを作成するためにここにあります。
この2つを組み合わせることで、Sparkは、ファイルシステムなど、不足している機能を利用できます。 Hadoopは手頃な価格のハードウェアを使用して大量のデータを保存し、後で分析を実行しますが、Sparkは受信データを処理するためのリアルタイム処理をもたらします。 Hadoopがないと、ビジネスアプリケーションはSparkが処理できない重要な履歴データを見逃す可能性があります。
この協調的な環境では、SparkはHadoopのセキュリティとリソース管理の利点も活用します。 YARNを使用すると、Sparkクラスタリングとデータ管理がはるかに簡単になります。利用可能なリソースを使用して、Sparkワークロードを自動的に実行できます。
このコラボレーションは、遡及的なトランザクションデータ分析、高度な分析、およびIoTデータ処理で最高の結果を提供します。これらのユースケースはすべて、1つの環境で可能です。
HadoopとSparkの作成者は、2つのプラットフォームを互換性があり、最適な結果を生成することを目的としていました。 あらゆるビジネス要件に適合します。