はじめに
Apache HadoopやSparkなどのデータ処理フレームワークは、ビッグデータの開発を後押ししてきました。さまざまなデータストリームから大量のデータを収集する能力は驚くべきものですが、すべてのデータを分析、管理、クエリするためのデータウェアハウスが必要です。
データウェアハウスとは何か、データウェアハウスが何で構成されているかについて詳しく知りたいですか?
この記事では、データウェアハウスアーキテクチャについて説明しています システム内の各コンポーネントの役割。
データウェアハウスとは何ですか?
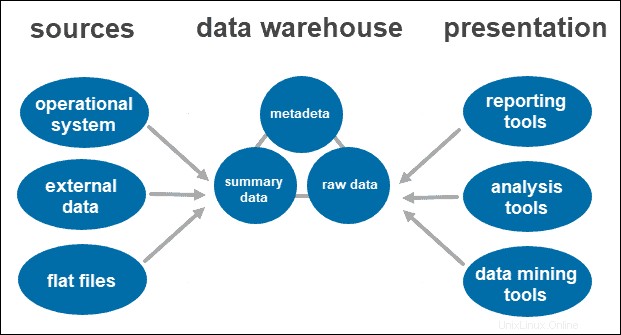
データウェアハウス(DWまたはDWH)は、予測、レポート、およびデータ分析に使用される履歴データと累積データを格納する複雑なシステムです。これには、さまざまなデータストリームからデータを収集、クレンジング、変換し、ファクト/ディメンションテーブルにロードすることが含まれます。
データウェアハウスは、サブジェクト指向の統合された時変の不揮発性データ構造を表します。
DWHは、操作ではなく主題に焦点を合わせて、複数のソースからのデータを統合し、一貫した形式で単一の情報ソースをユーザーに提供します。不揮発性であるため、以前の状態を消去することなく、すべてのデータ変更を新しいエントリとして記録します。この機能は、履歴データの記録を保持し、時間の経過に伴う変化を調べることができるため、時変であることに密接に関連しています。
これらのプロパティはすべて、企業が変化や傾向を調査するために必要な分析レポートを作成するのに役立ちます。
データウェアハウスアーキテクチャ
データウェアハウスシステムを構築する方法は3つあります。これらのアプローチは、アーキテクチャの層の数によって分類されます。したがって、次のことができます:
- 単一層アーキテクチャ
- 2層アーキテクチャ
- 3層アーキテクチャ
単一層データウェアハウスアーキテクチャ
単層アーキテクチャは、頻繁に実行されるアプローチではありません。このようなアーキテクチャを持つことの主な目標は、保存されるデータの量を最小限に抑えることで冗長性を排除することです。
その主な欠点は、分析処理とトランザクション処理を分離するコンポーネントがないことです。
2層データウェアハウスアーキテクチャ
2層アーキテクチャには、データウェアハウスレイヤーの前に、すべてのデータソースのステージング領域が含まれます。ソースとストレージリポジトリの間にステージング領域を追加することで、ウェアハウスにロードされたすべてのデータがクレンジングされ、適切な形式になっていることを確認できます。
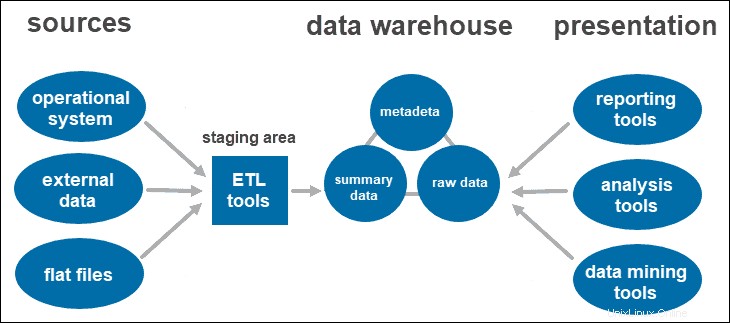
このアプローチには、特定のネットワーク制限があります。さらに、それを拡張してより多くのユーザーをサポートすることはできません。
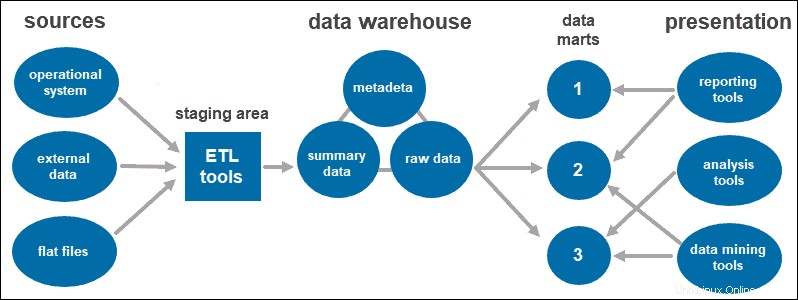
3層のデータウェアハウスアーキテクチャ
3層アプローチは、データウェアハウスシステムで最も広く使用されているアーキテクチャです。
基本的に、3つの層で構成されています:
- 最下層 クレンジングおよび変換されたデータがロードされるウェアハウスのデータベースです。
- 中間層 データベースの抽象化されたビューを提供するアプリケーション層です。データを整理して、分析により適したものにします。これは、ROLAPまたはMOLAPモデルを使用して実装されたOLAPサーバーで実行されます。
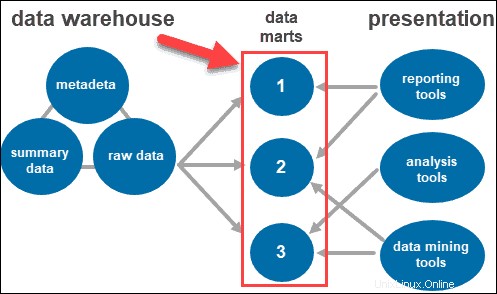
- トップティア ユーザーがデータにアクセスして操作する場所です。これは、フロントエンドクライアントレイヤーを表します。レポートツール、クエリ、分析、またはデータマイニングツールを使用できます。
データウェアハウスコンポーネント
上で概説したアーキテクチャから、一部のコンポーネントが重複しているのに対し、他のコンポーネントは層の数に固有であることがわかります。
以下に、システムにおける最も重要なデータウェアハウスコンポーネントとその役割のいくつかを示します。
ETLツール
ETLは抽出の略です 、変換 、およびロード 。ステージングレイヤーはETLツールを使用します さまざまな形式から必要なデータを抽出し、データウェアハウスにロードする前に品質をチェックします。
データソースレイヤーからのデータは、さまざまな形式で提供されます。複数のソースから収集されたすべてのデータを単一のデータベースにマージする前に、システムは情報をクリーンアップして整理する必要があります。
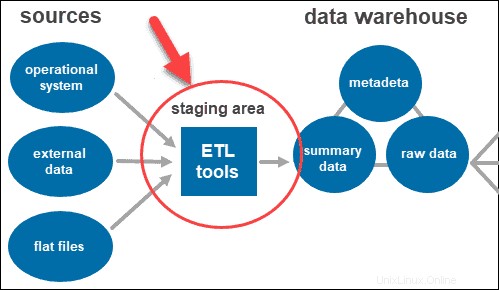
データベース
最も重要なコンポーネントであり、各アーキテクチャの中心はデータベースです。ウェアハウスは、データが保存およびアクセスされる場所です。
データウェアハウスシステムを作成するときは、最初に使用するデータベースの種類を決定する必要があります。
選択できるデータベースには、次の4つのタイプがあります。
- リレーショナルデータベース (行中心のデータベース)。
- 分析データベース (分析を維持および管理するために開発されました。)
- データウェアハウスアプリケーション (データ管理用のソフトウェアとサードパーティのディーラーが提供するデータを保存するためのハードウェア)
- クラウドベースのデータベース(クラウドでホストされています)。
データ
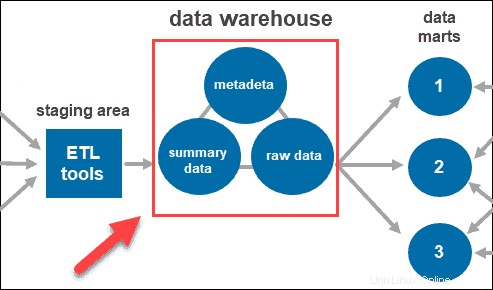
システムがデータをクリーンアップして整理すると、データウェアハウスに保存されます。データウェアハウスは、各ソースからのメタデータ、要約データ、および生データを格納する中央リポジトリを表します。
- メタデータ データを定義する情報です。その主な役割は、データインスタンスの操作を簡素化することです。これにより、データアナリストは、クエリを分類、検索し、必要なデータに転送できます。
- 要約データ 倉庫管理者によって生成されます。新しいデータがウェアハウスにロードされると更新されます。このコンポーネントには、簡単にまたは高度に要約されたデータを含めることができます。その主な役割は、クエリのパフォーマンスを高速化することです。
- 生データ は、処理されていない、リポジトリにロードされている実際のデータです。データを生の形式で保持すると、さらに処理および分析するためにデータにアクセスできるようになります。
アクセスツール
ユーザーは、さまざまなツールやテクノロジーを通じて収集された情報を操作します。データを分析し、洞察を収集し、レポートを作成できます。
使用されるツールには次のものがあります。
- レポートツール。 彼らはあなたのビジネスがどのように行われているか、そして次に何をすべきかを理解する上で重要な役割を果たします。レポートツールには、データが時間の経過とともにどのように変化するかを示すグラフやチャートなどの視覚化が含まれています。
- OLAPツール。 ユーザーが複数の視点から多次元データを分析できるようにするオンライン分析処理ツール。これらのツールは、高速処理と貴重な分析を提供します。多数のリレーショナルデータセットからデータを抽出し、それを多次元形式に再編成します。
- データマイニングツール。 データセットを調べて、ウェアハウス内のパターンとそれらの間の相関関係を見つけます。データマイニングは、多次元データを分析する際の関係の確立にも役立ちます。
データマート
データマートを使用すると、ウェアハウス内のデータをカテゴリにセグメント化することにより、システム内に複数のグループを作成できます。データを分割し、特定のユーザーグループ向けに生成します。
たとえば、データマートを使用して、社内の部門ごとに情報を分類できます。
データウェアハウスのベストプラクティス
データウェアハウスの設計は、個々のユースケースのビジネスロジックを理解することに依存しています。
要件はさまざまですが、従う必要のあるデータウェアハウスのベストプラクティスがあります。
- データモデルを作成します。 組織のビジネスロジックを特定することから始めます。組織にとって重要なデータと、データウェアハウスをどのように流れるかを理解します。
- よく知られたデータウェアハウスアーキテクチャ標準を選択します。 データモデルは、アーキテクチャの設計や問題のトラブルシューティングを行う際に従うべきフレームワークと一連のベストプラクティスを提供します。人気のあるアーキテクチャ標準には、3NF、Data Vaultモデリング、スタースキーマが含まれます。
- データフロー図を作成します。 データがシステムをどのように流れるかを文書化します。それが要件とビジネスロジックにどのように関連しているかを理解してください。
- 信頼できる唯一の情報源があります。 非常に多くのデータを処理する場合、組織は信頼できる唯一の情報源を持っている必要があります。データを単一のリポジトリに統合します。
- 自動化を使用します。 自動化ツールは、大量のデータを処理するときに役立ちます。
- メタデータの共有を許可します。 データウェアハウスコンポーネント間のメタデータ共有を容易にするアーキテクチャを設計します。
- コーディング標準を適用します。 コーディング標準はシステムの効率を保証します。