はじめに
このチュートリアルは、Kubernetesとコンテナデプロイの概念に焦点を当てた一連の記事の最初のチュートリアルです。 Kubernetesは、コンテナ化されたアプリケーションのクラスターを管理するために使用されるツールです。コンピューティングでは、このプロセスはしばしばオーケストレーションと呼ばれます 。
音楽オーケストラとの類似性は、多くの点で適切です。指揮者と同じように、Kubernetesは多くのマイクロサービスを調整します。これらのマイクロサービスは一緒になって便利なアプリケーションを形成します。 Kubernetesはクラスターを自動的かつ永続的に監視し、そのコンポーネントを調整します。
Kubernetesアーキテクチャを理解することは、コンテナ化されたアプリケーションをデプロイおよび維持するために重要です。
Kubernetesとは何ですか?
Kubernetes、または k8s 略して、アプリケーションの展開を自動化するためのシステムです。最新のアプリケーションは、クラウド、仮想マシン、およびサーバーに分散しています。アプリを手動で管理することは、もはや実行可能なオプションではありません。
K8sは、仮想マシンと物理マシンを統合されたAPIサーフェスに変換します。その後、開発者はKubernetes APIを使用して、コンテナ化されたアプリケーションをデプロイ、スケーリング、管理できます。
そのアーキテクチャは、分散システムに柔軟なフレームワークも提供します。 K8sは、アプリケーションのスケーリングとフェイルオーバーを自動的に調整し、デプロイパターンを提供します。
これは、アプリケーションを実行するコンテナーの管理に役立ち、実稼働環境でダウンタイムが発生しないようにします。たとえば、コンテナがダウンした場合、エンドユーザーが気付くことなく自動的に別のコンテナが代わりに使用されます。
Kubernetesはオーケストレーションシステムだけではありません。これは、独立した相互接続された制御プロセスのセットです。その役割は、現在の状態を継続的に処理し、プロセスを目的の方向に移動することです。
コンテナオーケストレーションについて詳しく知りたい場合は、Kubernetesとは何かに関する記事をご覧ください。
Kubernetesのアーキテクチャとコンポーネント
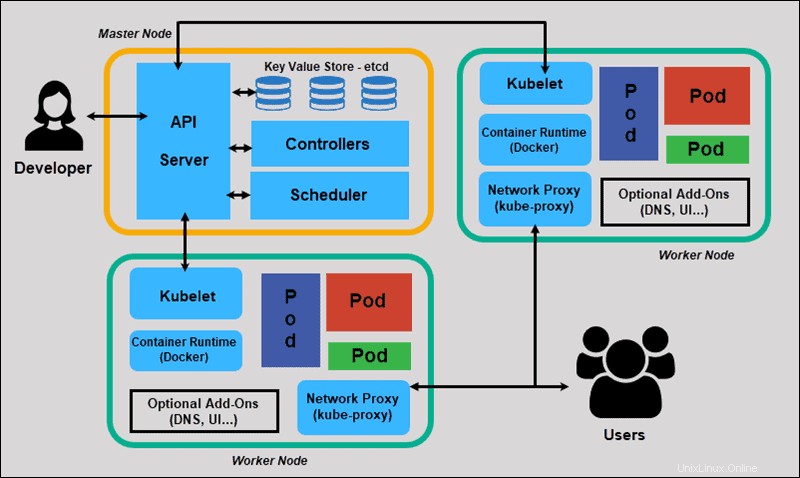
Kubernetesには、タスクを順番に処理しない分散型アーキテクチャがあります。宣言型モデルに基づいて機能し、「望ましい状態」の概念を実装します。 。」これらの手順は、Kubernetesの基本的なプロセスを示しています。
- 管理者は、アプリケーションの目的の状態を作成してマニフェストファイルに配置します。
- ファイルは、CLIまたはUIを使用してKubernetesAPIサーバーに提供されます。 Kubernetesのデフォルトのコマンドラインツールはkubectlと呼ばれます 。 kubectlコマンドの包括的なリストが必要な場合は、Kubectlチートシートを確認してください。
- Kubernetesは、ファイル(アプリケーションの目的の状態)を Key-Value Store(etcd)と呼ばれるデータベースに保存します 。
- Kubernetesは、クラスター内の関連するすべてのアプリケーションに目的の状態を実装します。
- Kubernetesはクラスターの要素を継続的に監視して、アプリケーションの現在の状態が目的の状態から変化しないことを確認します。
次に、標準のKubernetesクラスターの個々のコンポーネントを調べて、プロセスをより詳細に理解します。
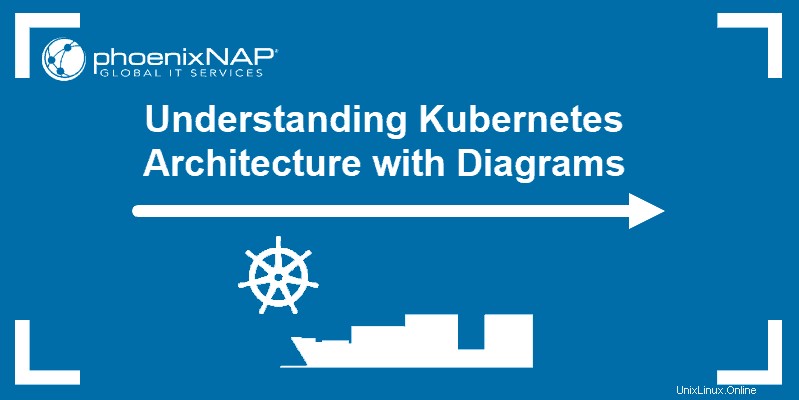
Kubernetesアーキテクチャのマスターノードとは何ですか?
Kubernetesマスター(マスターノード)は、APIを介してCLI(コマンドラインインターフェイス)またはUI(ユーザーインターフェイス)から入力を受け取ります。これらは、Kubernetesに提供するコマンドです。
Kubernetesで維持するポッド、レプリカセット、およびサービスを定義します。たとえば、使用するコンテナイメージ、公開するポート、実行するポッドレプリカの数などです。
また、そのクラスターで実行されているアプリケーションに必要な状態のパラメーターを指定します。
Kubernetesマスターノード
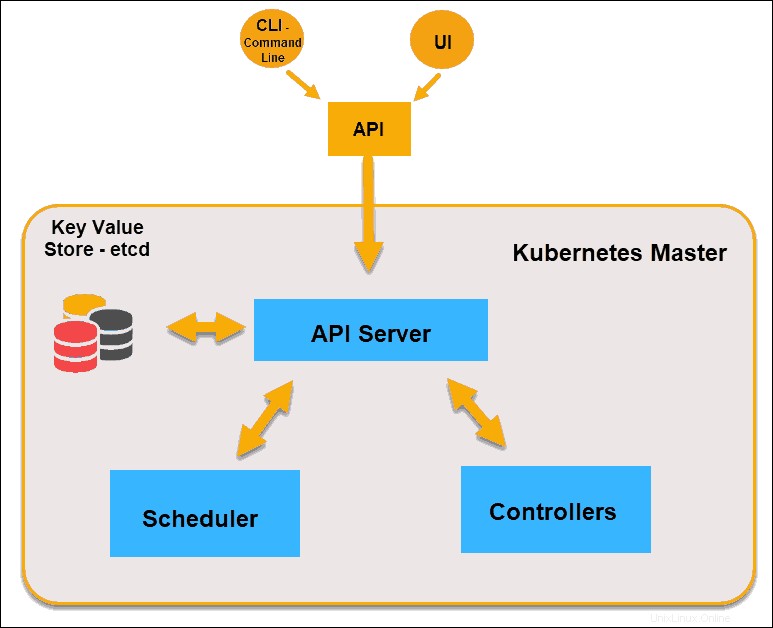
APIサーバー
APIサーバー はコントロールプレーンのフロントエンドであり、コントロールプレーン内で直接対話する唯一のコンポーネントです。内部システムコンポーネントと外部ユーザーコンポーネントはすべて、同じAPIを介して通信します。
Key-Valueストア(etcd)
etcdとも呼ばれるKey-Valueストア は、Kubernetesがすべてのクラスタデータをバックアップするために使用するデータベースです。クラスター全体の構成と状態を保管します。マスターノードはetcdにクエリを実行します ノード、ポッド、およびコンテナの状態のパラメータを取得します。
コントローラー
コントローラーの役割 APIサーバーから目的の状態を取得することです。制御するタスクのあるノードの現在の状態をチェックし、違いがあるかどうかを判断し、違いがある場合はそれを解決します。
スケジューラー
スケジューラー APIサーバーからの新しいリクエストを監視し、それらを正常なノードに割り当てます。ノードの品質をランク付けし、ポッドを最適なノードにデプロイします。適切なノードがない場合、そのようなノードが表示されるまで、ポッドは保留状態になります。
Kubernetesアーキテクチャのワーカーノードとは何ですか?
ワーカーノードは、APIサーバーで新しい作業の割り当てをリッスンします。作業の割り当てを実行してから、結果をKubernetesマスターノードに報告します。
Kubernetesワーカーノード
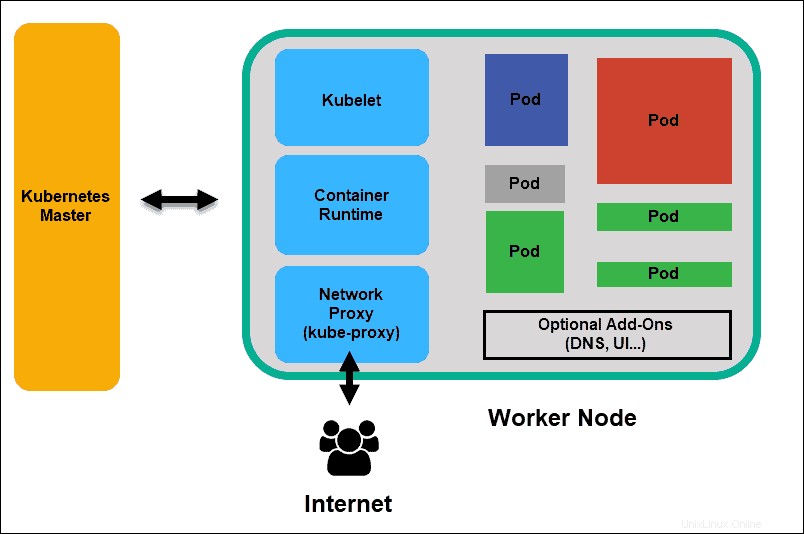
Kubelet
クベレット クラスタ内のすべてのノードで実行されます。これは、Kubernetesの主要なエージェントです。 kubeletをインストールすることで、ノードのCPU、RAM、およびストレージがより広範なクラスターの一部になります。 APIサーバーから送信されたタスクを監視し、タスクを実行して、マスターに報告します。また、ポッドを監視し、ポッドが完全に機能していない場合はコントロールパネルに報告します。その情報に基づいて、マスターはタスクとリソースを割り当てて目的の状態に到達する方法を決定できます。
コンテナランタイム
コンテナランタイム コンテナイメージレジストリからイメージをプルします コンテナを開始および停止します。 Dockerなどのサードパーティのソフトウェアまたはプラグインは通常、この機能を実行します。
Kubeプロキシ
kubeプロキシ 各ノードがそのIPアドレスを取得し、ローカルの iptablesを実装していることを確認します ルーティングとトラフィックの負荷分散を処理するためのルール。
ポッド
ポッド Kubernetesでのスケジューリングの最小要素です。これがないと、コンテナーをクラスターの一部にすることはできません。アプリをスケーリングする必要がある場合は、ポッドを追加または削除することによってのみスケーリングできます。
ポッドは、アプリケーションコードを含む単一のコンテナの「ラッパー」として機能します。リソースの可用性に基づいて、マスターは特定のノードでポッドをスケジュールし、コンテナーランタイムと調整してコンテナーを起動します。
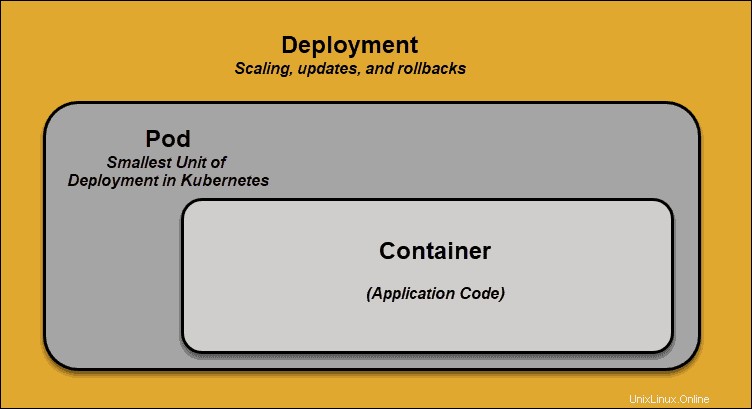
ポッドが予期せずタスクの実行に失敗した場合、Kubernetesはポッドの修正を試みません。代わりに、代わりに新しいポッドを作成して開始します。この新しいポッドは、DNSとIPアドレスを除いてレプリカです。この機能は、開発者がアプリケーションを設計する方法に大きな影響を与えました。
Kubernetesアーキテクチャの柔軟性により、アプリケーションをポッドの特定のインスタンスに関連付ける必要がなくなりました。代わりに、クラスター内のどこにでも作成されたまったく新しいポッドがシームレスに配置されるように、アプリケーションを設計する必要があります。このプロセスを支援するために、Kubernetesはサービスを使用します 。
Kubernetesサービス
ポッドは一定ではありません。 Kubernetesが提供する最高の機能の1つは、機能していないポッドが自動的に新しいポッドに置き換えられることです。
ただし、これらの新しいポッドには異なるIPのセットがあります。処理の問題が発生する可能性があり、IPが一致しなくなるとIPチャーンが発生します。放置すると、このプロパティによりポッドの信頼性が大幅に低下します。
安定したIPアドレスとDNS名を不安定なポッドの世界にもたらすことで、信頼性の高いネットワークを提供するサービスが導入されました。
ポッドに出入りするトラフィックを制御することで、Kubernetesサービスは安定したネットワークエンドポイント(固定IP、DNS、ポート)を提供します。サービスを通じて、基本的なネットワーク情報が何らかの形で変更されることを恐れることなく、任意のポッドを追加または削除できます。
Kubernetesサービスはどのように機能しますか?
ポッドは、ラベルと呼ばれるキーと値のペアを介してサービスに関連付けられます およびセレクター 。サービスは、セレクターと一致するラベルを持つ新しいポッドを自動的に検出します。
このプロセスにより、新しいポッドがサービスにシームレスに追加されると同時に、終了したポッドがクラスターから削除されます。
たとえば、目的の状態にポッドの3つのレプリカが含まれている場合 1つのレプリカが失敗するノード 、現在の状態は2つのポッドに縮小されます。 Kubernetesのオブザーバーは、目的の状態が3つのポッドであることを確認しています。次に、1つの新しいレプリカをスケジュールします 障害が発生したポッドの代わりに、クラスター内の別のノードに割り当てます。
ポッドを追加または削除してアプリケーションを更新またはスケーリングする場合も、同じことが当てはまります。目的の状態を更新すると、Kubernetesは不一致に気づき、マニフェストファイルと一致するようにポッドを追加または削除します。 Kubernetesコントロールパネルは、環境がユーザー定義の要件に一致するかどうかを継続的にチェックするバックグラウンド調整ループを記録、実装、実行します。
コンテナデプロイメントとは何ですか?
Kubernetesがどのように、何を調整するかを完全に理解するには、コンテナのデプロイの概念を探る必要があります。 。
従来の展開
当初、開発者はアプリケーションを個々の物理サーバーにデプロイしました。このタイプの展開には、いくつかの課題がありました。物理リソースの共有は、1つのアプリケーションが処理能力の大部分を占める可能性があり、同じマシン上の他のアプリケーションのパフォーマンスを制限することを意味しました。
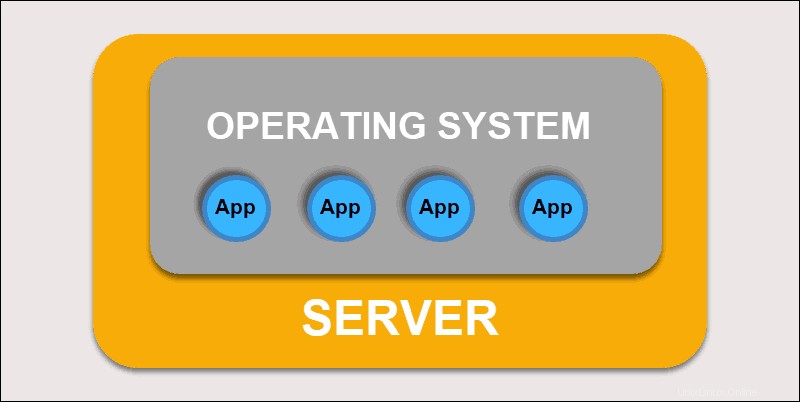
従来の導入
ハードウェアの容量を拡張するには長い時間がかかり、その結果、コストが増加します。ハードウェアの制限を解決するために、組織は物理マシンの仮想化を開始しました。
仮想化された展開
仮想化された展開により、分離された仮想環境、仮想マシン(VM)を作成できます 、単一の物理サーバー上。このソリューションは、VM内のアプリケーションを分離し、リソースの使用を制限し、セキュリティを強化します。アプリケーションは、別のアプリケーションによって処理された情報に自由にアクセスできなくなります。
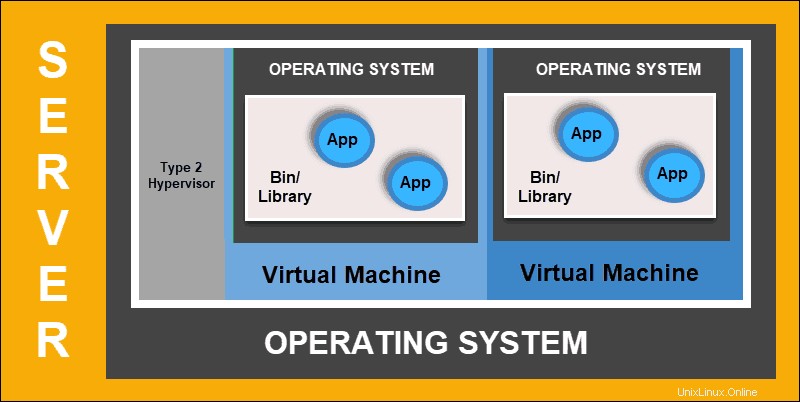
仮想化された導入
仮想化された展開により、単一の物理サーバーのリソースを迅速に拡張して分散し、自由に更新し、ハードウェアコストを抑えることができます。各VMにはオペレーティングシステムがあり、仮想化されたハードウェア上で必要なすべてのシステムを実行できます。
コンテナの導入
コンテナのデプロイは、より柔軟で効率的なモデルを作成するためのドライブの次のステップです。 VMと同様に、コンテナには個別のメモリ、システムファイル、および処理スペースがあります。ただし、厳密な分離はもはや制限要因ではありません。
複数のアプリケーションが同じ基盤となるオペレーティングシステムを共有できるようになりました。この機能により、コンテナーは本格的なVMよりもはるかに効率的になります。これらは、クラウド、さまざまなデバイス、およびほぼすべてのOSディストリビューション間で移植可能です。
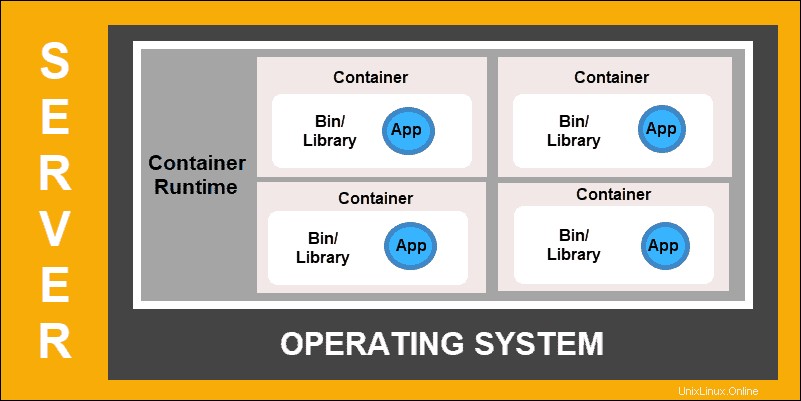
コンテナの導入
コンテナ構造により、アプリケーションをより小さな独立したパーツとして実行することもできます。これらのパーツは、複数のマシンに動的に展開および管理できます。複雑な構造とタスクのセグメンテーションは複雑すぎて手動で管理できません。
このプロセスに関係するすべての可動部分を効果的に管理するには、Kubernetesなどの自動化ソリューションが必要です。