
このチュートリアルでは、Ubuntu14.04にApacheHadoopをインストールする方法を示します。知らない人のために、ApacheHadoopはJavaで記述されたオープンソースのソフトウェアフレームワークです。分散ストレージおよび分散プロセスでは、コンピュータークラスター全体に分散することで、非常に大きなサイズのデータセットを処理します。ライブラリ自体は、ハードウェアに依存して高可用性を提供するのではなく、アプリケーションレイヤーで障害を検出して処理するように設計されているため、それぞれが障害を起こしやすい可能性のあるコンピューターのクラスター上での可用性の高いサービス。
この記事は、少なくともLinuxの基本的な知識があり、シェルの使用方法を知っていること、そして最も重要なこととして、サイトを独自のVPSでホストしていることを前提としています。インストールは非常に簡単で、ルートアカウントで実行されていますが、そうでない場合は、'sudoを追加する必要があります。 ‘ルート権限を取得するコマンドに。 Ubuntu14.04にApacheHadoopを段階的にインストールする方法を紹介します。 LinuxMintのような他のDebianベースのディストリビューションでも同じ手順に従うことができます。
前提条件
- 次のオペレーティングシステムのいずれかを実行しているサーバー:Ubuntu14.04。
- 潜在的な問題を防ぐために、OSの新規インストールを使用することをお勧めします。
- サーバーへのSSHアクセス(またはデスクトップを使用している場合はターミナルを開く)。
non-root sudo userまたはroot userへのアクセス 。non-root sudo userとして行動することをお勧めします ただし、ルートとして機能するときに注意しないと、システムに害を及ぼす可能性があるためです。
Ubuntu14.04にApacheHadoopをインストールする
ステップ1. Java(OpenJDK)をインストールします。
HadoopはJavaに基づいているため、システムにJava JDKがインストールされていることを確認してください。システムにJavaがインストールされていない場合は、次のリンクを使用してください。最初にインストールします。
- Ubuntu14.04にJavaJDK8をインストールします
root@idroot.us ~# java -version java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
手順2.IPv6を無効にします。
現在、HadoopはIPv6をサポートしておらず、IPv4ネットワークでのみ機能するようにテストされています。IPv6を使用している場合は、HadoopホストマシンをIPv4を使用するように切り替える必要があります。 :
nano /etc/sysctl.conf
ファイルの最後に次の3行を追加します:
#disable ipv6; net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1 net.ipv6.conf.lo.disable_ipv6 = 1
手順3.ApacheHadoopをインストールします。
セキュリティの問題を回避するために、次のコマンドに従って、新しいHadoopユーザーグループとユーザーアカウントを設定して、Hadoop関連のすべてのアクティビティを処理することをお勧めします。
sudo addgroup hadoopgroup sudo adduser —ingroup hadoopgroup hadoopuser
ユーザーを作成した後、独自のアカウントにキーベースのsshを設定する必要もあります。これを行うには、次のコマンドを実行します。
su - hadoopuser ssh-keygen -t rsa -P "" cat /home/hadoopuser/.ssh/id_rsa.pub >> /home/hadoopuser/.ssh/authorized_keys chmod 600 authorized_keys ssh-copy-id -i ~/.ssh/id_rsa.pub slave-1 ssh slave-1
Apache Hadoopの最新の安定バージョンをダウンロードします。この記事を書いている時点では、バージョン2.7.0です:
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz tar xzf hadoop-2.7.0.tar.gz mv hadoop-2.7.0 hadoop
Hadoop環境変数を設定します。~/.bashrcを編集します ファイルを作成し、ファイルの最後に次の値を追加します。
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
現在実行中のセッションに環境変数を適用します:
source ~/.bashrc
ここで、$HADOOP_HOME/etc/hadoop/hadoop-env.shを編集します。 ファイルを作成し、JAVA_HOME環境変数を設定します:
export JAVA_HOME=/usr/jdk1.8.0_45/
Hadoopには多くの構成ファイルがあり、Hadoopインフラストラクチャの要件に従って構成する必要があります。基本的なHadoopシングルノードクラスターのセットアップから始めましょう。
cd $HADOOP_HOME/etc/hadoop
core-site.xmlを編集します :
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration> hdfs-site.xmlを編集します :
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration> mapred-site.xmlを編集します :
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
yarn-site.xmlを編集します :
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> 次のコマンドを使用してnamenodeをフォーマットします。ストレージディレクトリを確認することを忘れないでください:
hdfs namenode -format
すべてのHadoopサービスを開始するには、次のコマンドを使用します:
cd $HADOOP_HOME/sbin/ start-dfs.sh start-yarn.sh
出力を観察して、スレーブノードのデータノードを1つずつ開始しようとしていることを確認する必要があります。すべてのサービスが正常に開始されているかどうかを確認するには、'jps ‘コマンド:
jps
ステップ5.ApacheHadoopへのアクセス。
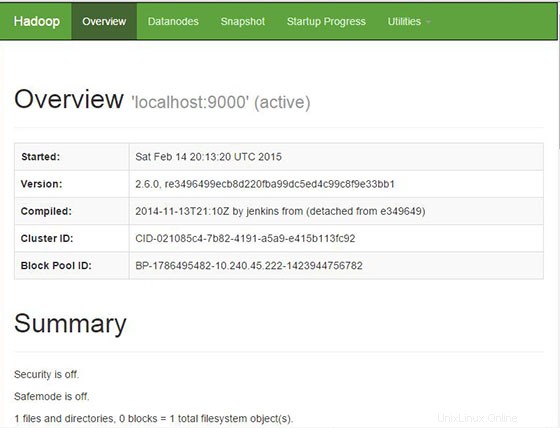
Apache Hadoopは、デフォルトでHTTPポート8088およびポート50070で使用できます。お気に入りのブラウザーを開き、http://your-domain.com:50070 またはhttp://server-ip:50070 。ファイアウォールを使用している場合は、ポート8088と50070を開いて、コントロールパネルにアクセスできるようにしてください。
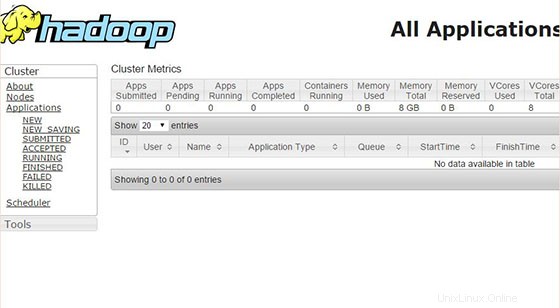
デフォルトでResourceManagerのWebインターフェイスを参照し、http://your-domain.com:8088で入手できます。 またはhttp://server-ip:8088 :
おめでとうございます。ApacheHadoopが正常にインストールされました。Ubuntu14.04システムにApache Hadoopをインストールするためにこのチュートリアルを使用していただき、ありがとうございます。追加のヘルプや役立つ情報については、ApacheHadoopの公式Webサイトを確認することをお勧めします。