はじめに
Apache StormとSparkは、リアルタイムデータストリームで動作するビッグデータ処理用のプラットフォームです。 2つのテクノロジーの主な違いは、データ処理の処理方法にあります。 Stormはタスクの計算を並列化し、Sparkはデータの計算を並列化します。ただし、API間には他にも基本的な違いがあります。
この記事では、ApacheStormとSparkStreamingの詳細な比較を提供します。

ストームvs.スパーク:定義
アパッチストーム リアルタイムストリーム処理フレームワークです。 トライデント 抽象化レイヤーは、Stormに代替インターフェースを提供し、リアルタイムの分析操作を追加します。
一方、 Apache Spark は、大規模データ用の汎用分析フレームワークです。 Spark Streaming APIは、フレームワーク内の他の分析ツールとともに、ほぼリアルタイムでデータをストリーミングするために利用できます。
ストームとスパーク:比較
StormとSparkはどちらも、同様の目的で自由に使用できるオープンソースのApacheプロジェクトです。次の表に、2つのテクノロジーの主な違いの概要を示します。
| ストーム | スパーク | |
|---|---|---|
| プログラミング言語 | 多言語統合 | Python、R、Java、Scalaのサポート |
| 処理モデル | トライデントを通じて利用可能なマイクロバッチ処理を使用したストリーム処理 | ストリーミングを通じて利用可能なマイクロバッチ処理によるバッチ処理 |
| プリミティブ | タプルストリーム タプルバッチ パーティション | DStream |
| 信頼性 | 1回だけ(Trident) 少なくとも一度は せいぜい一度 | 正確に1回 |
| フォールトトレランス | スーパーバイザープロセスによる自動再起動 | リソースマネージャーを介したワーカーの再起動 |
| 状態管理 | トライデントでサポート | ストリーミングでサポート |
| 使いやすさ | 操作と展開が難しい | 管理と展開が簡単 |
プログラミング言語
他のプログラミング言語との統合の可用性は、StormとSparkのどちらかを選択する際の最大の要因の1つであり、2つのテクノロジーの主な違いの1つです。
嵐
Stormには多言語があります この機能により、事実上すべてのプログラミング言語で利用できるようになります。ストリーミングと処理のためのTridentAPIは、以下と互換性があります:
- Java
- Clojure
- Scala
スパーク
Sparkは、次の言語向けの高レベルのストリーミングAPIを提供します。
- Java
- Scala
- Python
カスタムソースからのストリーミングなど、一部の高度な機能はPythonでは使用できません。ただし、KafkaやKinesisなどの高度な外部ソースからのストリーミングは、3つの言語すべてで利用できます。
処理モデル
処理モデルは、データストリーミングの実現方法を定義します。情報は、次のいずれかの方法で処理されます。
- 一度に1つのレコード。
- 離散化されたバッチで。
嵐
コアStormの処理モデルは、タプルストリームを直接操作します。一度に1つのレコード 、それを適切なリアルタイムストリーミングテクノロジーにします。 Trident APIは、マイクロバッチを使用するオプションを追加します 。
スパーク
Spark処理モデルは、データをバッチに分割します 、さらに処理する前にレコードをグループ化します。 Spark Streaming APIは、データをマイクロバッチに分割するオプションを提供します 。
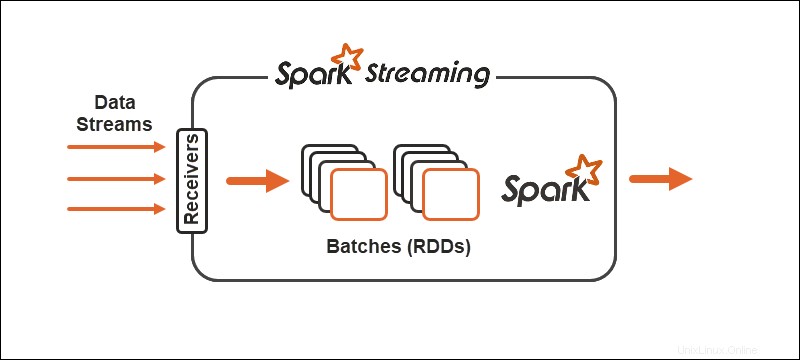
プリミティブ
プリミティブは、両方のテクノロジーの基本的な構成要素と、データに対して変換操作を実行する方法を表します。
嵐
CoreStormはタプルストリームで動作します 、Tridentはタプルバッチで動作します およびパーティション 。 Trident APIは、Hadoopの高レベルの抽象化に匹敵する方法でコレクションを処理します。 Stormの主なプリミティブは次のとおりです。
- 注ぎ口 ソースからリアルタイムストリームを生成します。
- ボルト データ処理を実行し、永続性を保持します。
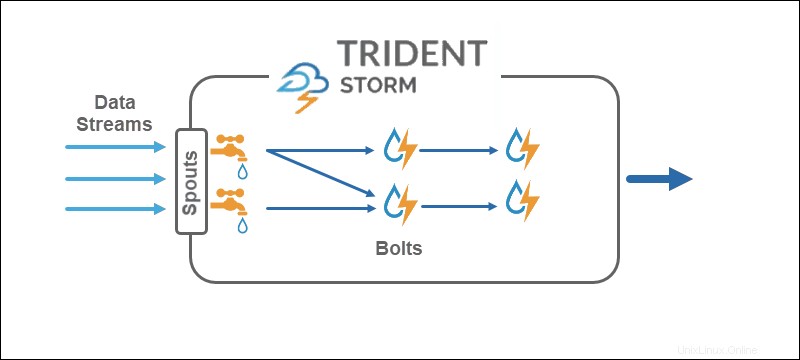
トライデントトポロジでは、操作はボルトにグループ化されます。グループ化、結合、集計、実行関数、およびフィルターは、分離されたバッチおよびさまざまなコレクションで使用できます。アグリゲーションは、HDFSまたはCassandraなどの他のストアにバックアップされたメモリ内に永続的に保存されます。
スパーク
Spark Streamingを使用すると、データの連続ストリームが個別のストリームに分割されます。 (DStreams)、一連の復元力のある分散データベース (RDD)。
Sparkでは、プリミティブに対して2つの一般的なタイプの演算子を使用できます。
1.ストリーム変換演算子 ここで、1つのDStreamが別のDStreamに変換されます。
2.出力演算子 外部システムへの情報の書き込みを支援します。
信頼性
信頼性とは、データ配信の保証を指します。 3つがあります データストリーミングの信頼性を処理する際の可能な保証:
- 少なくとも1回 。データは1回配信され、複数回配信される可能性もあります。
- 最大1回 。データは1回だけ配信され、重複はすべて削除されます。データが到着しない可能性があります。
- 1回だけ 。データは、損失や重複なしに1回配信されます。保証オプションは、達成するのは難しいですが、データストリーミングに最適です。
嵐
Stormは、データストリーミングの信頼性に関しては柔軟性があります。基本的に、少なくとも1回 および最大で1回 オプションが可能です。 Trident APIと一緒に、3つの構成すべてが利用可能です 。
スパーク
Sparkは、正確に1回に焦点を当てることにより、最適なルートをとろうとします。 データストリーミング構成。ワーカーまたはドライバーが失敗した場合、少なくとも1回 セマンティクスが適用されます。
フォールトトレランス
フォールトトレランスは、障害が発生した場合のストリーミングテクノロジーの動作を定義します。 SparkとStormはどちらも、同様のレベルでフォールトトレラントです。
スパーク
ワーカーに障害が発生した場合、SparkはYARNなどのリソースマネージャーを介してワーカーを再起動します。ドライバーの障害は、回復のためにデータチェックポイントを使用します。
嵐
StormまたはTridentでプロセスが失敗した場合、監視プロセスが自動的に再起動を処理します。 ZooKeeperは、状態の回復と管理において重要な役割を果たします。
状態管理
SparkStreamingとStormTridentの両方に、状態管理テクノロジーが組み込まれています。状態の追跡は、フォールトトレランスと1回限りの配信保証を実現するのに役立ちます。
使いやすさと開発
使いやすさと開発のしやすさは、テクノロジーがどれだけ文書化されているか、そしてストリームの操作がどれほど簡単かによって異なります。
スパーク
Sparkは、2つのテクノロジーからの展開と開発が容易です。ストリーミングは十分に文書化されており、Sparkクラスターにデプロイされます。ストリームジョブはバッチジョブと交換可能です。
嵐
Stormには、ZooKeeperクラスターへの依存関係が含まれているため、構成と開発が少し難しくなります。 Stormを使用する場合の利点は、多言語機能によるものです。
ストームvs.スパーク:選択方法
StormとSparkのどちらを選択するかは、プロジェクトと利用可能なテクノロジーによって異なります。主な要因の1つは、プログラミング言語とデータ配信の信頼性の保証です。
2つのデータストリーミングと処理には違いがありますが、最善の方法は、両方のテクノロジーをテストして、自分と手元のデータストリームに最適なものを確認することです。