Apache Sparkは、より高速な計算結果を提供するために作成された、無料のオープンソースの汎用分散コンピューティングフレームワークです。 Java、Python、Scala、Rなど、ストリーミング、グラフ処理用のいくつかのAPIをサポートしています。通常、Apache SparkはHadoopクラスターで使用できますが、スタンドアロンモードでインストールすることもできます。
このチュートリアルでは、Debian11にApacheSparkフレームワークをインストールする方法を紹介します。
- Debian11を実行しているサーバー。
- ルートパスワードはサーバーで構成されています。
Javaのインストール
ApacheSparkはJavaで書かれています。したがって、Javaをシステムにインストールする必要があります。インストールされていない場合は、次のコマンドを使用してインストールできます。
apt-get install default-jdk curl -y
Javaがインストールされたら、次のコマンドを使用してJavaのバージョンを確認します。
java --version
次の出力が得られるはずです:
openjdk 11.0.12 2021-07-20 OpenJDK Runtime Environment (build 11.0.12+7-post-Debian-2) OpenJDK 64-Bit Server VM (build 11.0.12+7-post-Debian-2, mixed mode, sharing)
ApacheSparkをインストールします
このチュートリアルを書いている時点では、ApacheSparkの最新バージョンは3.1.2です。次のコマンドを使用してダウンロードできます:
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
ダウンロードが完了したら、次のコマンドを使用してダウンロードしたファイルを抽出します。
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz
次に、次のコマンドを使用して、抽出したディレクトリを/optに移動します。
mv spark-3.1.2-bin-hadoop3.2/ /opt/spark
次に、〜/ .bashrcファイルを編集し、Sparkパス変数を追加します。
nano ~/.bashrc
次の行を追加します:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
ファイルを保存して閉じ、次のコマンドを使用してSpark環境変数をアクティブにします。
source ~/.bashrc
ApacheSparkを起動します
これで、次のコマンドを実行してSparkマスターサービスを開始できます。
start-master.sh
次の出力が得られるはずです:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian11.outにログを記録します。
デフォルトでは、Apache Sparkはポート8080でリッスンします。次のコマンドを使用して確認できます:
ss -tunelp | grep 8080
次の出力が得られます:
tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=24356,fd=296)) ino:47523 sk:b cgroup:/user.slice/user-0.slice/session-1.scope v6only:0 <->
次に、次のコマンドを使用してApacheSparkワーカープロセスを開始します。
start-slave.sh spark://your-server-ip:7077
Apache SparkWebUIにアクセスする
これで、URL http:// your-server-ip:8080を使用してApacheSparkWebインターフェースにアクセスできます。 。次の画面にApacheSparkマスターおよびスレーブサービスが表示されます。
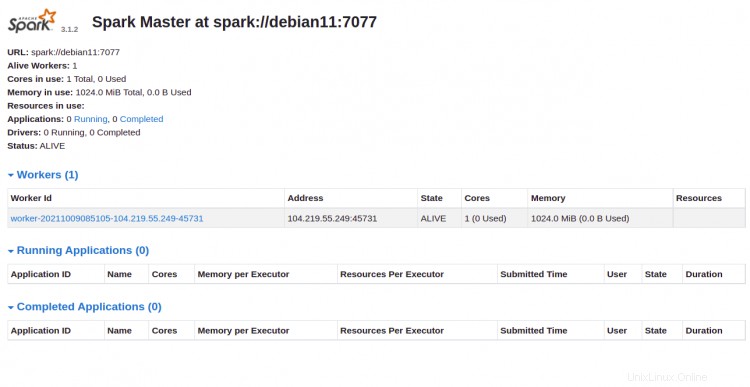
ワーカーをクリックします id。次の画面にワーカーの詳細情報が表示されます。
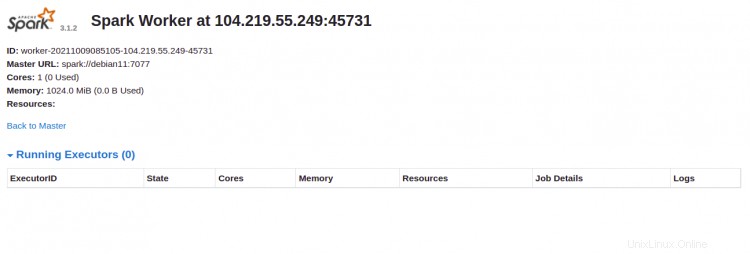
コマンドシェルを介してSparkに接続する場合は、以下のコマンドを実行します。
spark-shell
接続すると、次のインターフェイスが表示されます。
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
SparkでPythonを使用したい場合。 pysparkコマンドラインユーティリティを使用できます。
まず、次のコマンドを使用してPythonバージョン2をインストールします。
apt-get install python -y
インストールしたら、次のコマンドでSparkを接続できます。
pyspark
接続すると、次の出力が得られます。
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.9.2 (default, Feb 28 2021 17:03:44)
Spark context Web UI available at http://debian11:4040
Spark context available as 'sc' (master = local[*], app id = local-1633769632964).
SparkSession available as 'spark'.
>>>
まず、次のコマンドを使用してスレーブプロセスを停止します。
stop-slave.sh
次の出力が得られます:
stopping org.apache.spark.deploy.worker.Worker
次に、次のコマンドを使用してマスタープロセスを停止します。
stop-master.sh
次の出力が得られます:
stopping org.apache.spark.deploy.master.Master
おめでとう!これで、Debian11にApacheSparkが正常にインストールされました。組織でApacheSparkを使用して、大規模なデータセットを処理できるようになりました