Apache Sparkは、大量のデータの分析、機械学習、グラフ処理に使用される無料のオープンソースクラスターコンピューティングフレームワークです。 Sparkには80以上の高レベルの演算子が付属しており、並列アプリを構築して、Scala、Python、R、SQLシェルからインタラクティブに使用できます。これは、データサイエンス用に特別に設計された超高速のメモリ内データ処理エンジンです。速度、フォールトトレランス、リアルタイムストリーム処理、インメモリコンピューティング、高度な分析など、豊富な機能セットを提供します。
このチュートリアルでは、Debian10サーバーにApacheSparkをインストールする方法を紹介します。
- 2GBのRAMを搭載したDebian10を実行しているサーバー。
- ルートパスワードはサーバーで構成されています。
開始する前に、サーバーを最新バージョンに更新することをお勧めします。次のコマンドを使用して更新できます:
apt-get update -y
apt-get upgrade -y
サーバーが更新されたら、サーバーを再起動して変更を実装します。
Javaのインストール
ApacheSparkはJava言語で書かれています。したがって、システムにJavaをインストールする必要があります。デフォルトでは、最新バージョンのJavaがDebian10デフォルトリポジトリで利用可能です。次のコマンドを使用してインストールできます:
apt-get install default-jdk -y
Javaをインストールした後、次のコマンドを使用して、インストールされているJavaのバージョンを確認します。
java --version
次の出力が得られるはずです:
openjdk 11.0.5 2019-10-15 OpenJDK Runtime Environment (build 11.0.5+10-post-Debian-1deb10u1) OpenJDK 64-Bit Server VM (build 11.0.5+10-post-Debian-1deb10u1, mixed mode, sharing)
ApacheSparkをダウンロード
まず、ApacheSparkの最新バージョンを公式Webサイトからダウンロードする必要があります。この記事を書いている時点では、ApacheSparkの最新バージョンは3.0です。次のコマンドを使用して、/optディレクトリにダウンロードできます。
cd /opt
wget http://apachemirror.wuchna.com/spark/spark-3.0.0-preview2/spark-3.0.0-preview2-bin-hadoop2.7.tgz
ダウンロードが完了したら、次のコマンドを使用してダウンロードしたファイルを抽出します。
tar -xvzf spark-3.0.0-preview2-bin-hadoop2.7.tgz
次に、以下に示すように、抽出したディレクトリの名前をsparkに変更します。
mv spark-3.0.0-preview2-bin-hadoop2.7 spark
次に、Sparkの環境を設定する必要があります。 〜/ .bashrcファイルを編集することでそれを行うことができます:
nano ~/.bashrc
ファイルの最後に次の行を追加します。
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
終了したら、ファイルを保存して閉じます。次に、次のコマンドを使用して環境をアクティブ化します。
source ~/.bashrc
これで、次のコマンドを使用してマスターサーバーを起動できます。
start-master.sh
次の出力が得られるはずです:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian10.outにログを記録します。
デフォルトでは、Apache Sparkはポート8080でリッスンしています。次のコマンドで確認できます:
netstat -ant | grep 8080
出力:
tcp6 0 0 :::8080 :::* LISTEN
次に、Webブラウザーを開き、URL http:// server-ip-address:8080を入力します。次のページが表示されます:
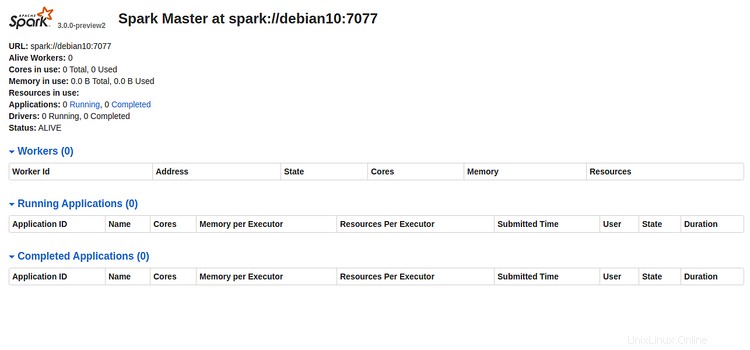
SparkのURL「spark:// debian10:7077」を書き留めてください "上の画像から。これはSparkワーカープロセスを開始するために使用されます。
Sparkワーカープロセスを開始
これで、次のコマンドを使用してSparkワーカープロセスを開始できます。
start-slave.sh spark://debian10:7077
次の出力が得られるはずです:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-debian10.out
Spark Shellは、APIを学習し、データをインタラクティブに分析するための簡単な方法を提供するインタラクティブな環境です。次のコマンドでSparkシェルにアクセスできます:
spark-shell
次の出力が表示されます。
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.0.0-preview2.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
19/12/29 15:53:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://debian10:4040
Spark context available as 'sc' (master = local[*], app id = local-1577634806690).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-preview2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.5)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
ここから、ApacheSparkをすばやく便利に最大限に活用する方法を学ぶことができます。
Sparkマスターおよびスレーブサーバーを停止する場合は、次のコマンドを実行します。
stop-slave.sh
stop-master.sh
これで、Debian10サーバーにApacheSparkが正常にインストールされました。詳細については、SparkDocのSpark公式ドキュメントを参照してください。