はじめに
Apache Sparkは、複数のソースからの大量のストリームデータを処理するオープンソースフレームワークです。 Sparkは、機械学習アプリケーション、データ分析、グラフ並列処理を使用した分散コンピューティングで使用されます。
このガイドでは、Windows10にApacheSparkをインストールする方法について説明します。 インストールをテストします。

前提条件
- Windows10を実行しているシステム
- 管理者権限を持つユーザーアカウント(ソフトウェアのインストール、ファイルのアクセス許可の変更、およびシステムPATHの変更に必要)
- コマンドプロンプトまたはPowershell
- 7-Zipなどの.tarファイルを抽出するためのツール
WindowsにApacheSparkをインストールする
Windows10へのApacheSparkのインストールは、初心者ユーザーには複雑に思えるかもしれませんが、この簡単なチュートリアルで実行できます。すでにJava8とPython3がインストールされている場合は、最初の2つの手順をスキップできます。
ステップ1:Java8をインストールする
ApacheSparkにはJava8が必要です。コマンドプロンプトを使用して、Javaがインストールされているかどうかを確認できます。
開始をクリックしてコマンドラインを開きます>「cmd」と入力します>コマンドプロンプトをクリックします 。
コマンドプロンプトに次のコマンドを入力します。
java -versionJavaがインストールされている場合、次の出力で応答します。
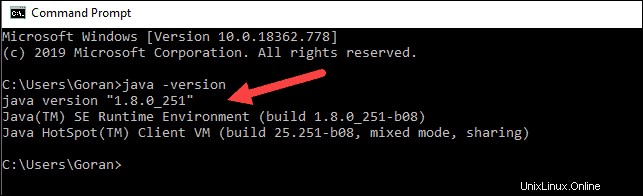
お使いのバージョンは異なる場合があります。 2桁目はJavaバージョンです。この場合はJava8です。
Javaがインストールされていない場合:
1.ブラウザウィンドウを開き、https://java.com/en/download/に移動します。
2.Javaダウンロードをクリックします ボタンを押して、ファイルを選択した場所に保存します。
3.ダウンロードが完了したら、ファイルをダブルクリックしてJavaをインストールします。
ステップ2:Pythonをインストールする
1. Pythonパッケージマネージャーをインストールするには、Webブラウザーでhttps://www.python.org/に移動します。
2.ダウンロードの上にマウスを置きます メニューオプションをクリックし、 Python 3.8.3をクリックします 。 3.8.3は、記事を書いている時点での最新バージョンです。
3.ダウンロードが完了したら、ファイルを実行します。
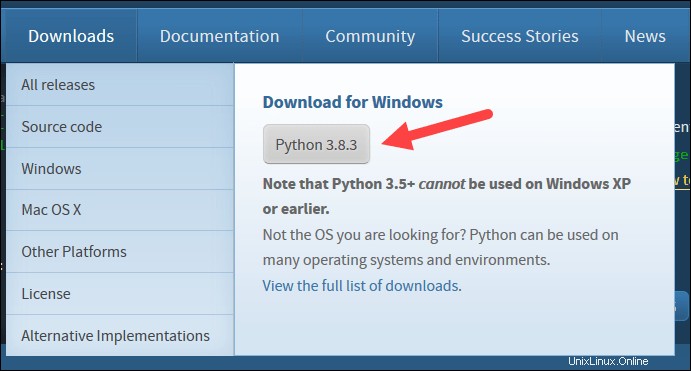
4.最初のセットアップダイアログボックスの下部にある[Python3.8をPATHに追加]をオフにします。 。もう一方のチェックボックスはオンのままにします。
5.次に、[インストールのカスタマイズ]をクリックします 。
6.このステップですべてのチェックボックスをオンのままにするか、不要なオプションのチェックを外すことができます。
7.次へをクリックします 。
8.ボックスすべてのユーザーにインストールを選択します 他のボックスはそのままにしておきます。
9.[インストール場所のカスタマイズ]で 参照をクリックします Cドライブに移動します。新しいフォルダを追加し、 Pythonという名前を付けます 。
10.そのフォルダを選択し、[ OK]をクリックします 。
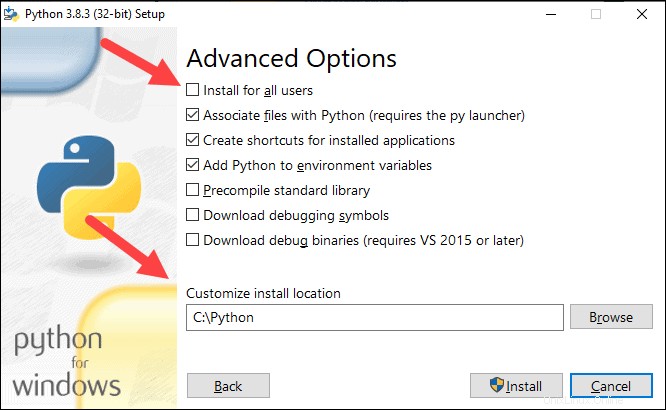
11.インストールをクリックします 、インストールを完了させます。
12.インストールが完了したら、パスの長さの制限を無効にするをクリックします。 下部にあるオプションをクリックし、[閉じる]をクリックします 。
13.コマンドプロンプトを開いている場合は、コマンドプロンプトを再起動します。 Pythonのバージョンを確認して、インストールを確認します。
python --version
出力はPython 3.8.3を出力する必要があります 。
ステップ3:ApacheSparkをダウンロードする
1.ブラウザーを開き、https://spark.apache.org/downloads.htmlに移動します。
2.ダウンロードApacheSparkの下 見出しには、2つのドロップダウンメニューがあります。現在の非プレビューバージョンを使用します。
- この場合、Sparkリリースを選択してください ドロップダウンメニューで2.4.5(2020年2月5日)を選択します 。
- 2番目のドロップダウンでパッケージタイプを選択 、 ApacheHadoop2.7用にビルド済みを選択したままにします 。
3. spark-2.4.5-bin-hadoop2.7.tgzをクリックします リンク。
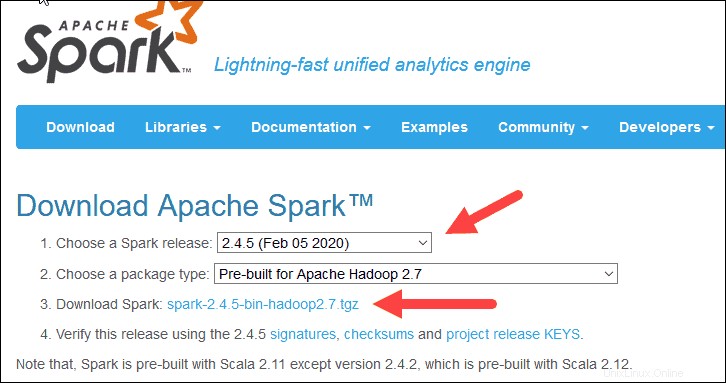
4.ミラーのリストがロードされたページで、ダウンロード元のさまざまなサーバーを確認できます。リストからいずれかを選択し、ファイルをダウンロードフォルダに保存します。
ステップ4:Sparkソフトウェアファイルを確認する
1. チェックサムをチェックして、ダウンロードの整合性を確認します ファイルの。これにより、変更されていない、破損していないソフトウェアで作業していることが保証されます。
2.スパークダウンロードに戻ります ページを開き、チェックサムを開きます リンク、できれば新しいタブで。
3.次に、コマンドラインを開き、次のコマンドを入力します。
certutil -hashfile c:\users\username\Downloads\spark-2.4.5-bin-hadoop2.7.tgz SHA512
4。 ユーザー名を自分のユーザー名に変更します。 Certutil: -hashfile completed successfullyというメッセージとともに、長い英数字のコードが表示されます。 。
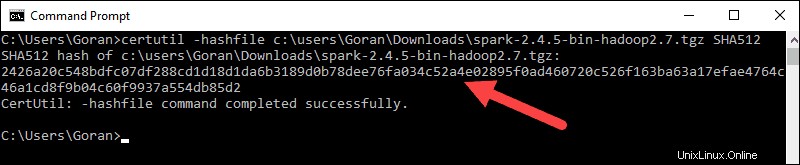
5.コードを新しいブラウザタブで開いたコードと比較します。それらが一致する場合、ダウンロードファイルは破損していません。
ステップ5:ApacheSparkをインストールする
Apache Sparkのインストールには、ダウンロードしたファイルの抽出が含まれます。 目的の場所に移動します。
1. Sparkという名前の新しいフォルダを作成します C:ドライブのルートにあります。コマンドラインから、次のように入力します。
cd \
mkdir Spark2.エクスプローラーで、ダウンロードしたSparkファイルを見つけます。
3.ファイルを右クリックして、 C:\ Sparkに解凍します。 システムにあるツール(7-Zipなど)を使用します。
4.これで、 C:\ Spark フォルダに新しいフォルダがありますspark-2.4.5-bin-hadoop2.7 必要なファイルが入っています。
ステップ6:winutils.exeファイルを追加する
winutils.exeをダウンロードします ダウンロードしたSparkインストールの基盤となるHadoopバージョンのファイル。
1.このURLhttps://github.com/cdarlint/winutilsおよびbin内に移動します フォルダで、 winutils.exeを見つけます 、クリックします。
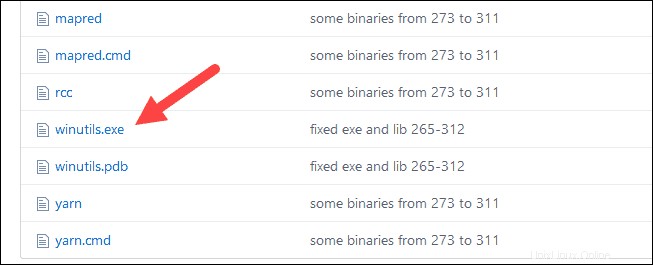
2.ダウンロードを見つけます 右側のボタンをクリックしてファイルをダウンロードします。
3.次に、新しいフォルダーを作成します Hadoop およびビン Cの場合:Windowsエクスプローラーまたはコマンドプロンプトを使用します。
4.winutils.exeファイルをダウンロードフォルダーからC:\ hadoop \ binにコピーします 。
ステップ7:環境変数を構成する
Windowsで環境変数を構成すると、SparkとHadoopの場所がシステムのPATHに追加されます。コマンドプロンプトウィンドウから直接Sparkシェルを実行できます。
1.開始をクリックします 環境と入力します 。
2.システム環境変数の編集というラベルの付いた結果を選択します 。
3.[システムのプロパティ]ダイアログボックスが表示されます。右下隅にある[環境変数]をクリックします 次に、[新規]をクリックします 次のウィンドウで。
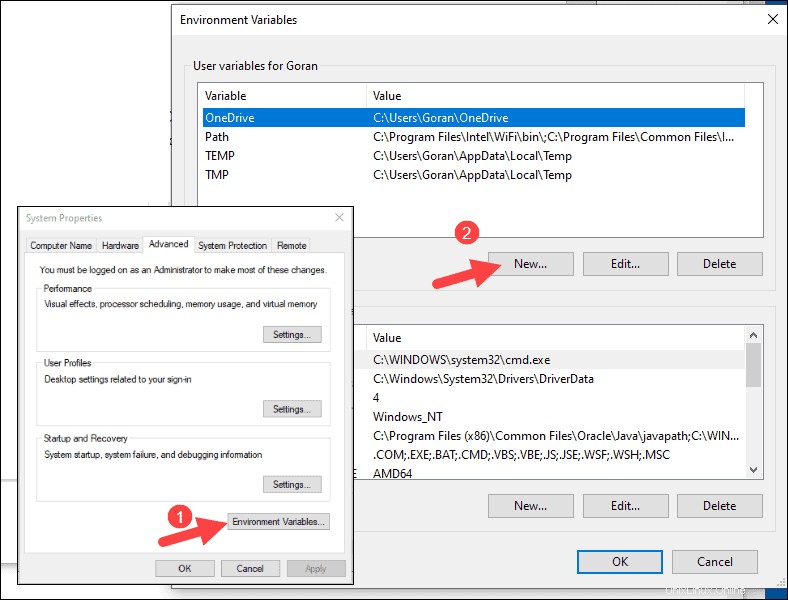
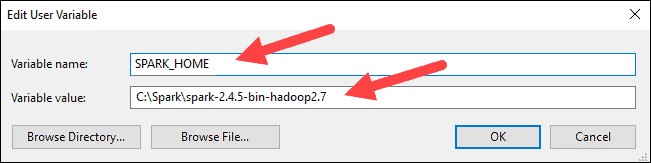
4.変数名の場合 SPARK_HOMEと入力します 。
5.変数値の場合 C:\ Spark \ spark-2.4.5-bin-hadoop2.7と入力します [OK]をクリックします。フォルダパスを変更した場合は、代わりにそのパスを使用してください。
6.上部のボックスで、[パス]をクリックします エントリをクリックし、編集をクリックします 。システムパスの編集には注意してください。すでにリストにあるエントリは削除しないでください。
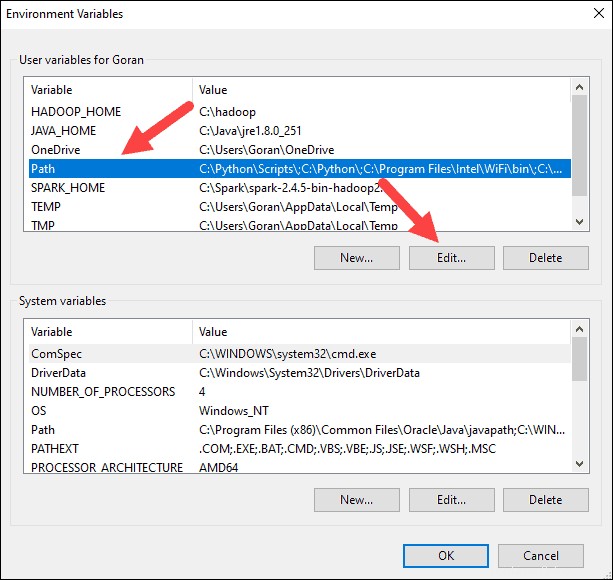
7.左側にエントリのあるボックスが表示されます。右側で、[新規]をクリックします 。
8.システムは新しい行を強調表示します。 Sparkフォルダへのパスを入力しますC:\ Spark \ spark-2.4.5-bin-hadoop2.7 \ bin 。 %SPARK_HOME%\ binの使用をお勧めします パスで発生する可能性のある問題を回避するため。
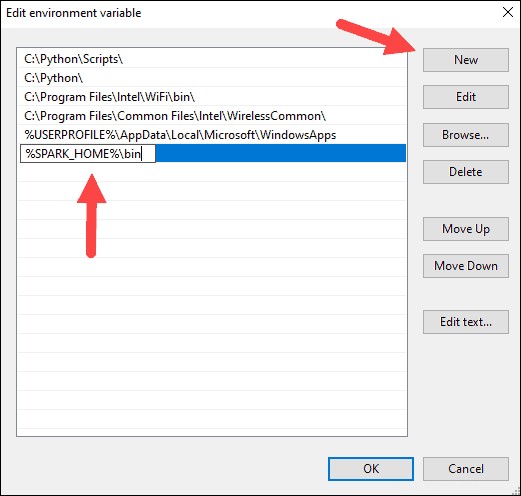
9.HadoopとJavaに対してこのプロセスを繰り返します。
- Hadoopの場合、変数名は HADOOP_HOMEです。 値には、前に作成したフォルダーのパス C:\hadoopを使用します。 C:\ hadoop \ binを追加します パス変数へ フィールドですが、%HADOOP_HOME%\ binを使用することをお勧めします 。
- Javaの場合、変数名は JAVA_HOME 値には、Java JDKディレクトリへのパスを使用します(この場合は、 C:\ Program Files \ Java \ jdk1.8.0_251 。
10. OKをクリックします 開いているすべてのウィンドウを閉じます。
ステップ8:Sparkを起動する
1.右クリックして管理者として実行を使用して、新しいコマンドプロンプトウィンドウを開きます :
2. Sparkを起動するには、次のように入力します。
C:\Spark\spark-2.4.5-bin-hadoop2.7\bin\spark-shell
環境パスを設定した場合 正しくは、 spark-shellと入力できます Sparkを起動します。
3.システムは、アプリケーションのステータスを示すいくつかの行を表示する必要があります。 Javaポップアップが表示される場合があります。 アクセスを許可を選択します 続行します。
最後に、Sparkのロゴが表示され、プロンプトにScalaシェルが表示されます。 。
4.、Webブラウザーを開き、 http:// localhost:4040 /に移動します。 。
5. localhostを置き換えることができます システムの名前で。
6.ApacheSparkシェルのWebUIが表示されます。以下の例は、エグゼキュータを示しています。 ページ。
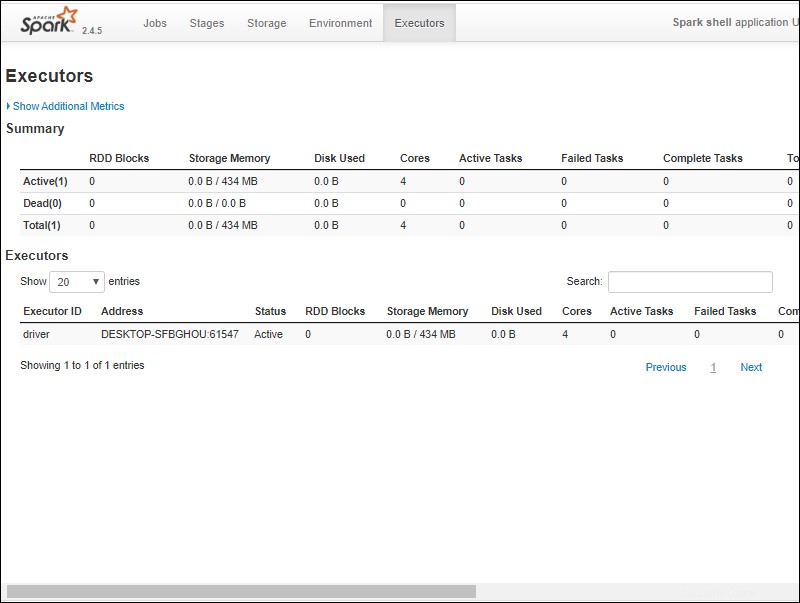
7. Sparkを終了してScalaシェルを閉じるには、 ctrl-dを押します。 コマンドプロンプトウィンドウで。
テストスパーク
この例では、Sparkシェルを起動し、Scalaを使用してファイルの内容を読み取ります。 READMEなどの既存のファイルを使用できます Sparkディレクトリのファイル、または独自のファイルを作成できます。 pnaptestを作成しました テキスト付き。
1.コマンドプロンプトウィンドウを開き、使用するファイルのあるフォルダーに移動して、Sparkシェルを起動します。
2.最初に、Sparkコンテキストで使用する変数をファイルの名前で記述します。ファイル拡張子がある場合は、忘れずに追加してください。
val x =sc.textFile("pnaptest")3.出力は、RDDが作成されたことを示しています。次に、次のコマンドを使用してアクションを呼び出すことにより、ファイルの内容を表示できます。
x.take(11).foreach(println)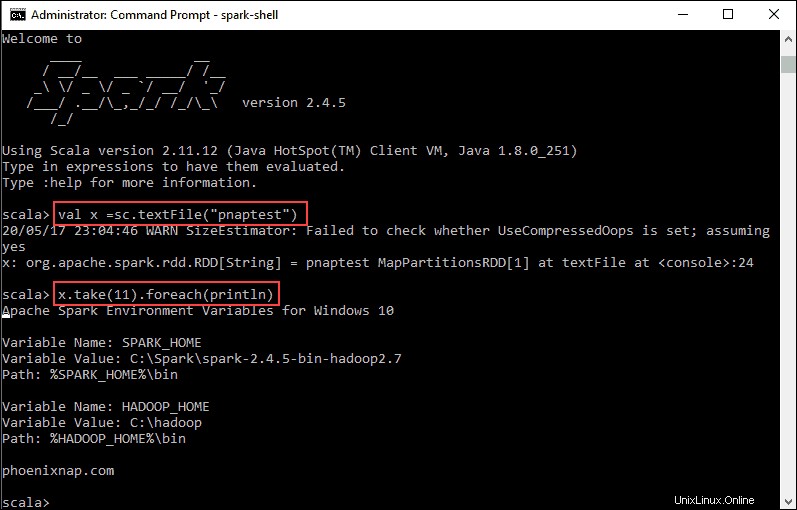
このコマンドは、指定したファイルから11行を印刷するようにSparkに指示します。このファイルに対してアクションを実行するには(値x )、別の値を追加します y 、およびマップ変換を実行します。
4.たとえば、次のコマンドを使用して文字を逆に印刷できます。
val y = x.map(_.reverse)5.システムは、最初のRDDに関連して子RDDを作成します。次に、値 yから印刷する行数を指定します :
y.take(11).foreach(println)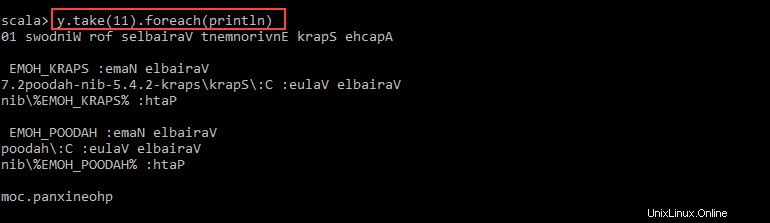
出力には、11行の pnaptestが出力されます。 逆の順序でファイルします。
完了したら、 ctrl-dを使用してシェルを終了します 。