はじめに
Cassandraは、NoSQLデータベースを処理するためのオープンソースの分散データベースソフトウェアです。このソフトウェアはCQLを使用します (Cassandraクエリ言語)コミュニケーションの基礎として。 CQLは、キーと値のペアを含む列を持つ行のセットに配置されたテーブルにデータを保持します。
CQLテーブルは、Cassandraではキースペースと呼ばれるデータコンテナにグループ化されています。 1つのキースペースに格納されているデータは、クラスター内の他のデータとは無関係です。したがって、クラスター内の別々のキースペースに複数の異なる目的のテーブルを置くことができ、データは一致しません。
このガイドでは、いくつかの異なる目的でCassandraテーブルを作成する方法と、Cassandraシェルを使用してテーブルを変更、削除、または切り捨てる方法を学習します。

前提条件
- システムにインストールされているCassandraデータベースソフトウェア
- cqlshをロードするためのターミナルまたはコマンドラインツールへのアクセス
- 必要な権限を持つユーザー コマンドを実行するには
Cassandraテーブルのキースペースの選択
テーブルの追加を開始する前に、テーブルを作成するキースペースを決定する必要があります。 。これを行うには2つのオプションがあります。
オプション1:USEコマンド
USEを実行します すべてのコマンドが適用されるキースペースを選択するコマンド。これを行うには、cqlshシェルで次のように入力します。
USE keyspace_name;次に、テーブルの追加を開始できます。
オプション2:クエリでキースペース名を指定する
2番目のオプションは、テーブル作成のクエリでキースペース名を指定することです。列名とオプションの前のコマンドの最初の部分は、次のようになります。
CREATE TABLE keyspace_name.table_nameこのようにして、定義したキースペースにテーブルをすぐに作成します。
Cassandraテーブルを作成するための基本的な構文
CQLを使用したテーブルの作成は、SQLクエリに似ています。このセクションでは、Cassandraでテーブルを作成するための基本的な構文を示します。
テーブルを作成するための基本的な構文は次のようになります。
CREATE TABLE tableName (
columnName1 dataType,
columnName2 dataType,
columnName2 datatype
PRIMARY KEY (columnName)
);
オプションで、 WITHを使用して追加のテーブルプロパティと値を定義できます。 :
WITH propertyName=propertyValue;たとえば、データをディスクに保存する方法や、圧縮を使用するかどうかを定義するために使用します。
Cassandraの主キータイプ
Cassandraのすべてのテーブルには、行を一意にする主キーが必要です。主キーを使用して、どのノードがデータを保存し、どのようにデータを分割するかを決定します。
主キーには次の2つのタイプがあります。
- 単純な主キー 。データを格納するノードを決定するためのパーティションキーとして、列名が1つだけ含まれています。
- 複合主キー。 1つのパーティションキーと複数のクラスタリング列を使用して、データを保存する場所とパーティションでのデータの並べ替え方法を定義します。
- 複合パーティションキー。 この場合、データを保存する場所を決定するいくつかの列があります。このようにして、データを小さな断片に分割して複数のパーティションに分散し、ホットスポットを回避できます。
Cassandraテーブルを作成する方法
次のセクションでは、さまざまなタイプの主キーを使用してテーブルを作成する方法について説明します。まず、テーブルを作成するキースペースを選択します。私たちの場合:
USE businesinfo;すべてのテーブルには、すべてのエントリの列とCassandraデータ型が含まれています。
単純な主キーを使用してテーブルを作成する
最初の例は、サプライヤーの基本的な表です。 IDはすべてのサプライヤに固有であり、主キーとして機能します。
CQLクエリは次のようになります:
CREATE TABLE suppliers (
supp_id int PRIMARY KEY,
supp_city text,
supp_email text,
supp_fee int,
supp_name text,
supp_phone int
);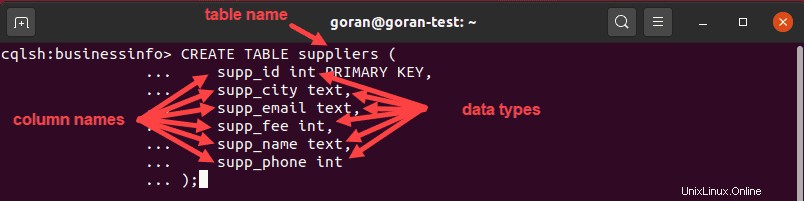
このクエリは、 supplierというテーブルを作成しました supp_idを使用 テーブルの主キーとして。列名をパーティションキーとして使用する単純な主キーを使用する場合は、クエリの先頭(主キーとして機能する列の横)に配置してから、列名を指定できます。 :
CREATE TABLE suppliers (
supp_id int,
supp_city text,
supp_email text,
supp_fee int,
supp_name text,
supp_phone int
PRIMARY KEY(supp_id)
);テーブルがキースペースにあるかどうかを確認するには、次のように入力します。
DESCRIBE TABLES;出力には、そのキースペース内のすべてのテーブルと、作成したテーブルが一覧表示されます。

テーブルの内容を表示するには、次のように入力します。
SELECT * FROM suppliers;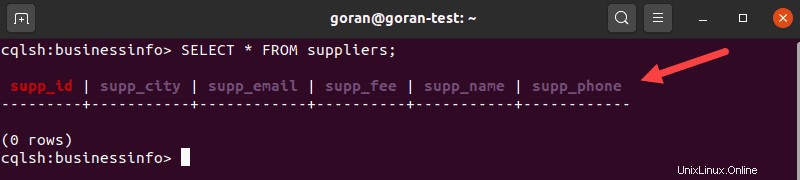
出力には、テーブルの作成中に定義されたすべての列が表示されます。
テーブルの詳細を確認するもう1つの方法は、 DESCRIBEを使用することです。 テーブル名を指定します:
DESCRIBE suppliers;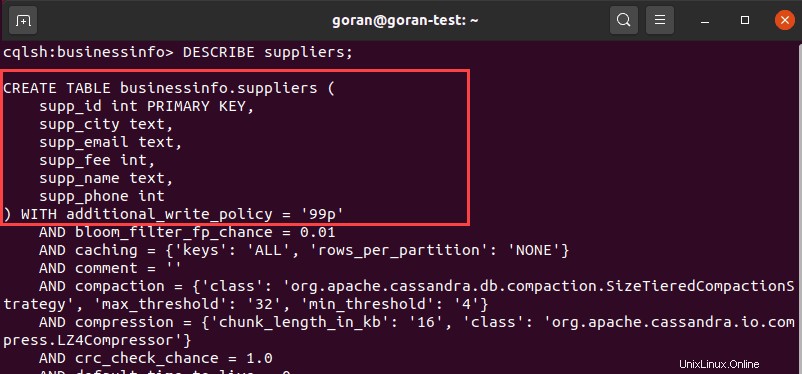
出力には、テーブルの列とデフォルト設定が表示されます。
複合主キーを使用してテーブルを作成する
クエリを実行して結果を特定の順序で並べ替えるには、複合主キーを使用してテーブルを作成します。
たとえば、サプライヤとサプライヤが提供するすべての製品のテーブルを作成します。製品はサプライヤごとに一意ではない可能性があるため、一意にするために主キーに1つ以上のクラスタリング列を追加する必要があります。
テーブルスキーマは次のようになります:
CREATE TABLE suppliers_by_product (
supp_product text,
supp_id int,
supp_product_quantity text,
PRIMARY KEY(supp_product, supp_id)
);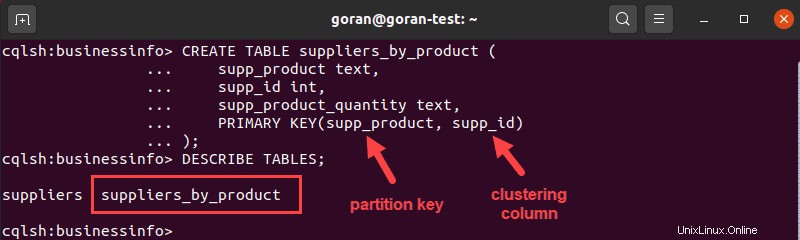
この場合、 supp_productを使用しました およびsupp_id 一意の複合キーを作成します。ここで、brackets supp_productの最初のエントリ パーティションキーです。データを保存する場所、つまりシステムがデータを分割する方法を決定します。
次のエントリは、Cassandraがデータを並べ替える方法を決定するクラスタリング列です。この場合、これは supp_idによるものです。 。
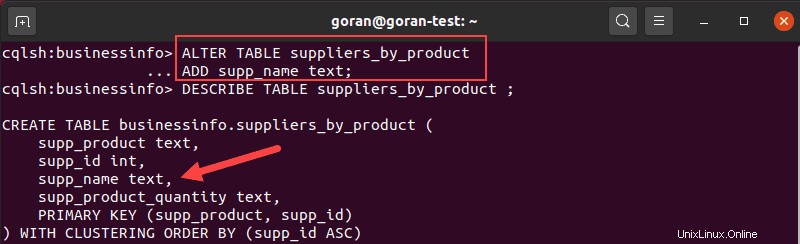
上の画像は、テーブルが正常に作成されたことを示しています。テーブルの詳細を確認するには、 DESCRIBE TABLEを実行します 新しいテーブルのクエリ:
DESCRIBE TABLE suppliers_by_product;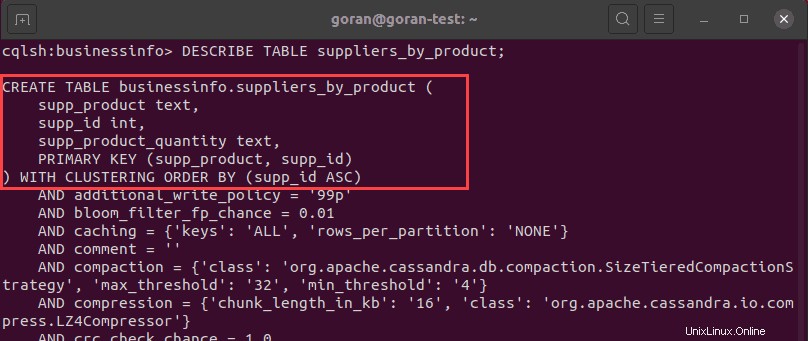
クラスタリング順序のデフォルト設定は昇順(ASC)です。主キーの後に次のステートメントを追加することで、降順(DESC)に変更できます。
WITH CLUSTERING ORDER BY (supp_id DESC);パーティションキーの後に1つのクラスタリング列を指定しました。 2つの列を使用してデータを並べ替える必要がある場合は、主キーブラケット内に別の列を追加します。
複合パーティションキーを使用してテーブルを作成する
複合パーティションキーを使用してテーブルを作成すると、1つのノードに大量のデータが格納され、複数のノードの負荷を分割する場合に役立ちます。
この場合、複数の列で構成されるパーティションキーを使用して主キーを定義します。二重角かっこを使用する必要があります。次に、以前と同じようにクラスタリング列を追加して、一意の主キーを作成します。
例:
CREATE TABLE suppliers_by_product_type (
supp_product_consume text,
supp_product_stock text,
supp_id int,
supp_name text,
PRIMARY KEY((supp_product_consume, supp_product_stock), supp_id)
);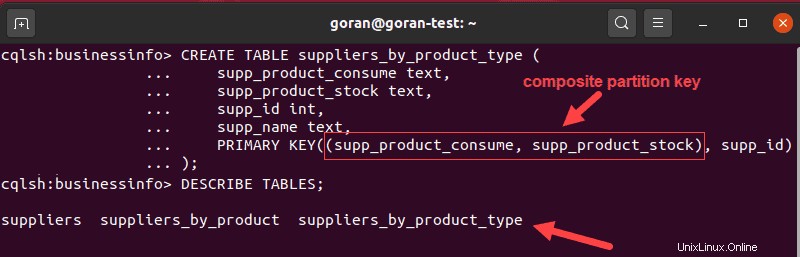
上記の例では、データをサプライヤの消耗品と在庫のある製品の2つのカテゴリに分類し、複合パーティションキーを使用してデータを配布しました。
代わりに、単純なパーティションキーと複数のクラスタリング列を持つ複合主キーを使用する場合、1つのノードが複数の列で並べ替えられたすべてのデータを処理します。
Cassandraドロップテーブル
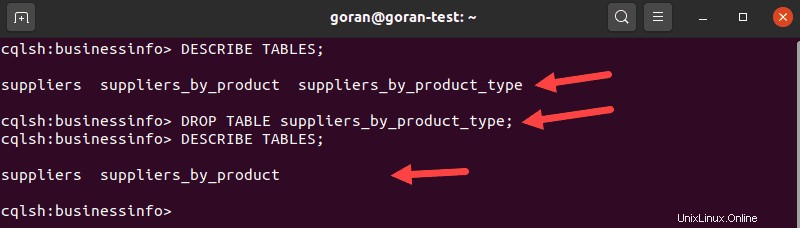
Cassandraのテーブルを削除するには、 DROP TABLEを使用します 声明。削除するテーブルを選択するには、次のように入力します。
DESCRIBE TABLES;ドロップしたいテーブルを見つけます。テーブルの名前を使用して削除します:
DROP TABLE suppliers_by_product_type;
DESCRIBE TABLESを実行します もう一度クエリを実行して、テーブルが正常に削除されたことを確認します。
Cassandra Alter Table
Cassandra CQLを使用すると、テーブルに列を追加したり、テーブルから列を削除したりできます。 ALTER TABLEを使用します テーブルに変更を加えるコマンド。
テーブルに列を追加する
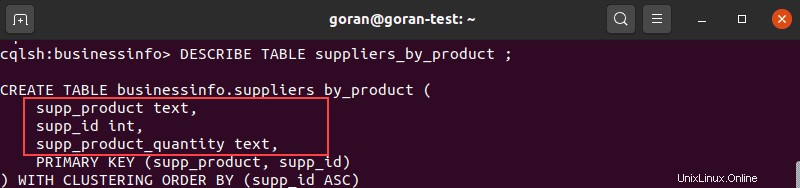
テーブルに列を追加する前に、テーブルの内容を表示して、列名がまだ存在しないことを確認することをお勧めします。
確認したら、 ALTER TABLEを使用します この形式でクエリを実行して列を追加します:
ALTER TABLE suppliers_by_product
ADD supp_name text;表を説明して、列がリストに表示されることを確認します。
テーブルから列を削除する
列を追加するのと同様に、テーブルから列を削除できます。 DESCRIBE TABLESを使用して、削除する列を見つけます クエリ。
次に、次のように入力します:
ALTER TABLE suppliers_by_product
DROP supp_product_quantity;Cassandra Truncate Table
テーブル全体を削除したくないが、すべての行を削除する必要がある場合は、 TRUNCATEを使用します コマンド。
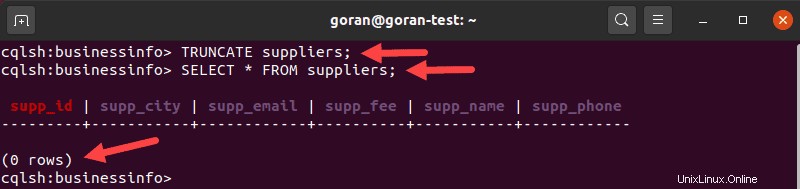
たとえば、テーブルからすべての行を削除するには suppliers 、次のように入力します:
TRUNCATE suppliers;
テーブルに行がもうないことを確認するには、 SELECTを使用します ステートメント。
テーブルを切り捨てると、変更は永続的になるため、このクエリを使用するときは注意してください。