はじめに
データベースの非正規化 は、データアクセスのパフォーマンスを向上させるために使用される手法です。データベースが正規化されていて、インデックス作成などの方法では不十分な場合、非正規化はデータ取得を高速化するための最後のオプションの1つとして機能します。
この記事では、データベースの非正規化とは何か、およびデータベースを高速化するために使用されるさまざまな手法について説明します。

データベースの非正規化とは何ですか?
データベースの非正規化 は、データを体系的に組み合わせて情報をすばやく取得するプロセスです。このプロセスにより、関係がより低い正規形になり、データの全体的な整合性が低下します。
一方、データ検索のパフォーマンスは向上します。データベースの正規化は、多数のテーブルに対して複数のコストのかかるJOINを実行する代わりに、一般的または論理的に組み合わされた情報をまとめるのに役立ちます。
データベースの異常は、正規形が低いために表示されます。冗長性の問題は、データベースにデータを入力するときにソフトウェアレベルの制限を追加することで解決策を見つけます。
データベースの正規化と非正規化
データベースの正規化と非正規化は、データベースの構造を変更する2つの異なる方法です。この表は、2つの方法の主な違いを示しています。
| 正規化 | 非正規化 | |
|---|---|---|
| 機能性 | 冗長な情報を削除し、データ変更速度を向上させます。 | 複数の情報を1つのユニットに結合し、データの取得速度を向上させます。 |
| フォーカス | データベースをクリーンアップして冗長性を削除します。 | クエリの実行を高速化するために導入された冗長性。 |
| メモリ | 一般的なパフォーマンスを最適化および改善しました。 | 冗長性によるメモリの非効率性。 |
| 整合性 | データベースの異常を削除すると、データベースの整合性が向上します。 | データの整合性は維持されていません。データベースの異常が存在します。 |
| ユースケース | 変更の挿入、更新、削除が頻繁に行われ、結合に費用がかからないデータベース。 | データウェアハウスなど、頻繁にクエリされるデータベース。 |
| 処理タイプ | オンライントランザクション処理-OLTP | オンライン分析処理-OLAP |
データベースの正規化では、データ構造を改善するために、正規化されていないデータベースを通常の形式で取得します。一方、非正規化は正規化されたデータベースから始まり、データを組み合わせて一般的に使用されるクエリをより高速に実行します。
データベースを非正規化する理由と時期
データベースの非正規化は、データの取得速度が重要な要素である場合に実行可能な手法です。ただし、このメソッドはデータベース構造全体を変更します。非正規化は、次のシナリオで役立ちます。
- クエリのパフォーマンスの向上。 情報をまとめると、冗長性が追加されます。ただし、JOINの数が減るため、クエリのパフォーマンスが向上します。
- 管理の利便性 。正規化されたデータベースは、粒度が高いため、管理が困難です。非正規化は、値を計算したり、必要に応じてそれらを接続したりする代わりに、すぐに利用できるデータを提供するのに役立ちます。
- 高速レポート 。分析データは、迅速に多くの計算を必要とします。レポートを生成するための非正規化データベースは、分析情報を迅速に提供するための完璧なソリューションです。
データベースのパフォーマンスが低い場合、非正規化が常に正しい方法であるとは限りません。プロセスによってデータベース構造が変更されるため、既存の機能が機能しなくなるリスクがあります。
データベース構造を変更する場合、参照ポイントを持つことは重要な概念です。最終的に、データベースの正規化は最後の手段として機能します 迅速な解決策の代わりに。
非正規化手法
ユースケースに応じて、さまざまなデータベースの非正規化手法が使用されます。それぞれの方法には、適切な使用場所、長所、短所があります。
事前結合テーブル
事前に結合されたテーブルは、頻繁に使用される情報を1つのテーブルにまとめて格納します。このプロセスは、次の場合に役立ちます。
- クエリは頻繁にテーブルで一緒に実行されます。
- 結合操作にはコストがかかります。
この方法では大量の冗長性が生じるため、最小限の列数を使用して情報を定期的に更新することが不可欠です。
事前結合テーブルの例
ストアは、アイテムおよびアイテムが属するカテゴリに関する情報を保持します。外部キーは、アイテムタイプへの参照として機能します。テーブルを事前に結合すると、カテゴリ名がアイテムテーブルに追加されます。
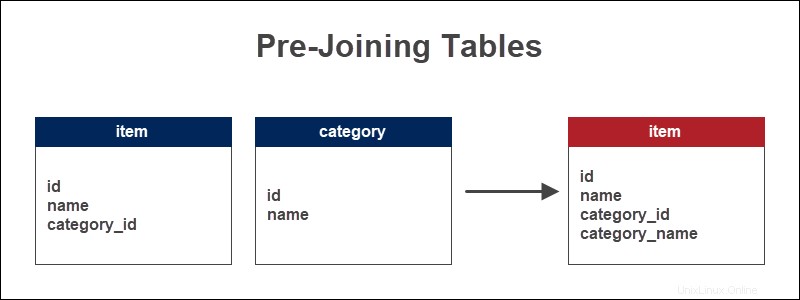
カテゴリ名をアイテムのテーブルに直接追加すると、カテゴリ別にアイテムをすばやく表示できます。長いクエリの場合、このメソッドは時間を節約し、JOINの数を減らします。
ミラーリングされたテーブル
ミラーリングされたテーブルは、既存のテーブルのコピーです。表は次のいずれかです:
- 部分的なコピー。
- 完全なコピー。
目標は、元のデータを新しいテーブルに再現することです。複製を作成することは、データベースの初期状態を保持するためのバックアップを作成するための優れた手法です。
ミラーテーブルの例
テーブルのミラーリングは、意思決定支援システムでデータを準備するためによく使用される方法です。クエリは通常、多くのデータポイントに集約されるため、このタスクはシステムパフォーマンスを大幅に低下させます。
意思決定支援システムは、ミラーリングされたテーブルを使用することで大きなメリットが得られます。元のテーブルにトランザクションを適用することは中断されず、重複するテーブルで要求の厳しいレポートが発生します。
テーブル分割
テーブル分割は、正規化されたテーブルを2つ以上のリレーションに分割することを意味します。テーブルの分割は2次元で行われます:
- 水平方向 。
UNIONを使用してテーブルを行サブセットに分割 オペレーター。 - 垂直に 。
INNER JOINを使用して、テーブルを列サブセットに分割します オペレーター。
このメソッドの目標は、テーブルをより小さな単位に分割して、より高速で便利なデータ処理を実現することです。データベースに元のテーブルも含まれている場合、このメソッドはミラーリングされたテーブルの特定のケースと見なされます。
テーブル分割の例
使用例は、テーブル分割の基準によって異なります。テーブルを分割する最も一般的な理由は次のとおりです。
- 管理 。会社全体の1つのテーブルではなく、セクターごとに1つのテーブル。
- 空間 。国全体の1つのテーブルではなく、地域ごとに1つのテーブル。
- 時間ベース 。 1年間のテーブルではなく、毎月1つのテーブル。
- 物理的 。すべてのサイトに1つのテーブルではなく、場所ごとに1つのテーブル。
- 手順 。ジョブ全体の1つのテーブルではなく、タスクのステップごとに1つのテーブル。
導出可能な値の保存
頻繁に実行される計算を保存することは、次のような状況で価値があります。
- 派生値の使用は頻繁に行われます。
- ソース値は変更されません。
派生可能なデータを直接保存することで、レポートの生成時に計算がすでに行われていることが保証され、各クエリのソース値を検索する必要がなくなります。
派生値の保存の例
人に関する情報を追跡するデータベーステーブルがある場合、人の年齢は生年月日に基づいて計算された値です。 MySQLの日付関数CURDATE()を使用して現在の日付の違いを見つけて、年齢を導き出します と生年月日。
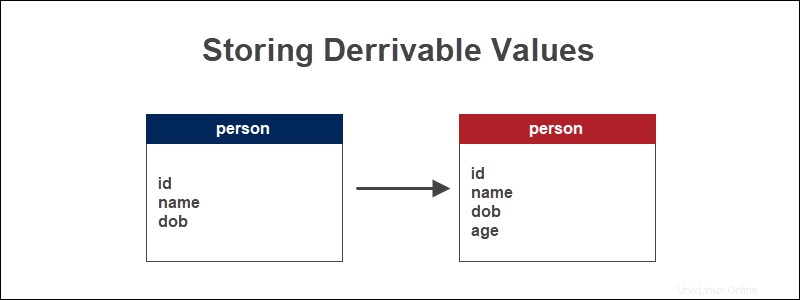
人口統計情報を分析する場合、年齢は重要な情報です。生年月日であるソース値は変更されません。
階層テーブル
階層テーブルは、1対多の関係を持つツリーのような構造です。 1つの親テーブルには多くの子があります。ただし、子には親テーブルが1つしかありません。階層テーブルは、次の場合に使用されます。
- データの構造は階層的です。
- 親テーブルは静的で不変です。
ハードコードされた値
ハードコードされた値は、一般的に使用されるエンティティへの参照を削除します。この方法は、次のような状況で使用してください。
- 値は静的と見なされます。
- 値の数が少ないです。
小さなルックアップテーブルを使用する代わりに、値はアプリケーションに直接ハードコードされます。このプロセスにより、ルックアップテーブルで結合を実行する必要もなくなります。
ハードコードされた値の例
人々に関する情報を含むテーブルは、小さなルックアップテーブルを使用して、個人の性別に関する情報を格納できます。ルックアップテーブルの情報には限られた数の値があるため、データを人のテーブルに直接ハードコーディングすることを検討してください。
ハードコードされた値により、ルックアップテーブルとそのテーブルとのJOIN操作が不要になります。ルックアップテーブルに変更を加えたり、新しい値を記録したりするには、チェック制約を追加する必要があります。
マスターとの詳細の保存
マスターテーブルには情報のメインテーブルが含まれていますが、他のテーブルには特定の詳細が含まれています。次の場合に、マスターテーブルに詳細を保存します。
- マスターテーブルの詳細な概要が不可欠です。
- マスターテーブルに関する分析レポートは頻繁にあります。
マスターテーブルですべての詳細を保持することは、データを選択するときに便利です。この方法は、詳細が少ない場合に最適に機能します。そうしないと、データ取得プロセスが大幅に遅くなります。
マスターで詳細を保存する例
顧客情報を含むマスターテーブルは、通常、個人に関する特定の詳細を別のテーブルに格納します。たとえば、特定の場所に関する情報は、通常、一連の小さなテーブルにあります。
顧客の場所を考慮したレポートは、場所の詳細をマスターテーブルに追加することでメリットがあります。
マスターで単一の詳細を繰り返す
多くの場合、クエリでは、複数の値を事前に結合するのではなく、マスターテーブルに1つの詳細を追加するだけで済みます。この方法は、次の場合に使用します。
- 結合は、単一の詳細に対してコストがかかります。
- マスターテーブルには頻繁に情報が必要です。
データベースに履歴データが含まれている場合、マスターテーブルに単一の詳細を追加するのが最も一般的です。繰り返されるエンティティは通常、最新の情報です。
マスターを使用した単一の詳細の例
ストアデータベースには通常、販売するアイテムに関する情報のマスターテーブルがあります。過去の価格変更に関する詳細が記載された別の表には、現在の価格に関する情報も含まれています。
この単一の詳細は現在のアイテムの価格を分析するのに役立つため、価格に関する最新の情報をマスターテーブルで繰り返すと便利です。
一貫性を保つために、コストの変更に対処し、マスターテーブルに更新する必要があります。
短絡キー
関連情報のテーブルが3つ以上あるデータベースでは、短絡キー方式は中央のテーブルをスキップし、祖父母と孫のテーブルを「短絡」します。
次のような状況では、短絡技術を使用してください。
- データベースには、3つ以上のレベルのマスター/詳細があります。
- 祖父母と孫からの価値観が必要になることが多く、親の情報はそれほど価値がありません。
2つのリレーションが中央のテーブルを介して関連している場合は、中間のリレーションのJOINを省略し、最初と最後のテーブルを直接接続します。
短絡キーの例
情報システムは、あるテーブルに人、別の場所に住所、3番目のテーブルにその住所の地理的領域に関する情報を保持できます。人口統計レポートの場合、正確な住所は重要な情報ではありません。
ただし、分析には人の位置が不可欠です。エリアを持つ人々のテーブルを短絡すると、中央のテーブルのJOINが省略されます。
非正規化の利点
利点 データベースの非正規化の例は次のとおりです。
- 速度 。正規化されたデータベースではJOINクエリにコストがかかるため、データの取得が高速になります。
- シンプルさ 。テーブルの数が少ないため、データの取得はより簡単です。
- エラーが少ない 。少数のテーブルで作業することは、データベースから情報を取得する際のバグが少ないことを意味します。
非正規化のデメリット
短所 データベースを非正規化するときに考慮すべき点は次のとおりです。
- 複雑さ 。データベースの更新と挿入は、より複雑でコストがかかります。
- 不整合 。データを更新するのは難しいため、情報の正しい値を見つけるのはより困難です。
- ストレージ 。冗長性が導入されているため、より多くのストレージスペースが必要です。