このチュートリアルでは、Ubuntu16.04でマルチノードHadoopクラスターをセットアップする方法を学習します。複数のデータノードを持つHadoopクラスターはマルチノードのHadoopクラスターであるため、このチュートリアルの目標は2つのデータノードを稼働させることです。
1)前提条件
- Ubuntu 16.04
- Hadoop-2.7.3
- Java 7
- SSH
このチュートリアルでは、2つの ubuntu 16.04 があります システム、私はそれらをマスターと呼んでいます およびスレーブ システムでは、各システムで1つのデータノードが実行されます。
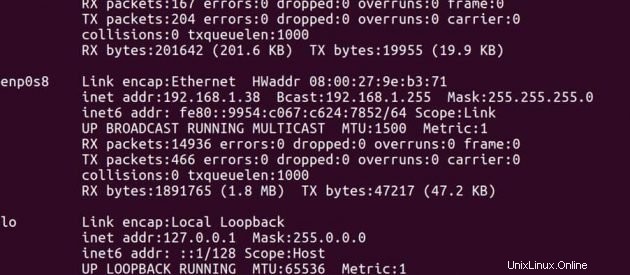
マスターのIPアドレス -> 192.168.1.37
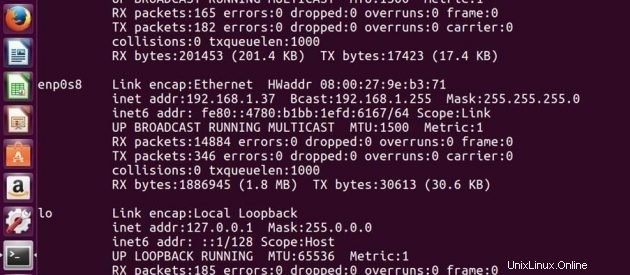
スレーブのIPアドレス -> 192.168.1.38
マスターについて
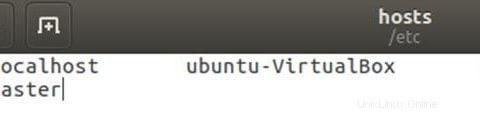
マスターとスレーブのIPアドレスを使用してhostsファイルを編集します。
sudo gedit /etc/hosts以下のようにファイルを編集します。ファイル内の他の行を削除できます。編集後、ファイルを保存して閉じます。

スレーブ上
マスターとスレーブのIPアドレスを使用してhostsファイルを編集します。
sudo gedit /etc/hosts以下のようにファイルを編集します。ファイル内の他の行を削除できます。編集後、ファイルを保存して閉じます。
2)Javaのインストール
Hadoopを設定する前に、システムにJavaをインストールする必要があります。以下のコマンドを使用して、両方のubuntuマシンにopenJDK7をインストールします。
sudo add-apt-repository ppa:openjdk-r/ppasudo apt-get updatedo apt-get install openjdk-7-jdk
以下のコマンドを実行して、Javaがシステムにインストールされているかどうかを確認します。
java -version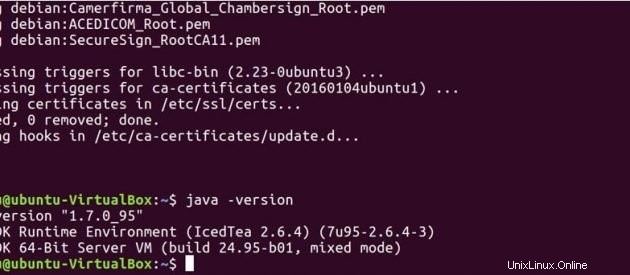
デフォルトでは、Javaは / usr / lib / jvm /に保存されます ディレクトリ。
ls /usr/lib/jvm
.bashrcでJavaパスを設定します ファイル。
sudo gedit .bashrcexport JAVA_HOME =/ usr / lib / jvm / java-7-openjdk-amd64
export PATH =$ PATH:/ usr / lib / jvm / java-7-openjdk-amd64 / bin
以下のコマンドを実行して、.bashrcファイルに加えられた変更を更新します。
source .bashrc3)SSH
Hadoopはノードを管理するためにSSHアクセスを必要とするため、マスターシステムとスレーブシステムの両方にsshをインストールする必要があります。
sudo apt-get install openssh-server</pre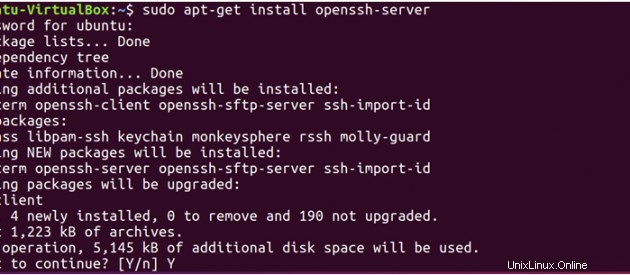
Now, we have to generate an SSH key on master machine. When it asks you to enter a file name to save the key, do not give any name, just press enter.
ssh-keygen -t rsa -P ""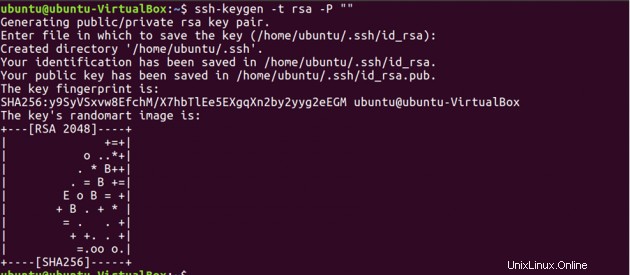
次に、この新しく作成されたキーを使用して、マスターマシンへのSSHアクセスを有効にする必要があります。
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
次に、ローカルマシンに接続してSSHセットアップをテストします。
ssh localhost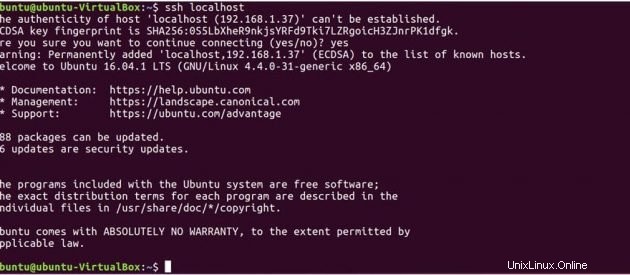
次に、以下のコマンドを実行して、マスターで生成された公開鍵をスレーブに送信します。
ssh-copy-id -i $HOME/.ssh/id_rsa.pub ubuntu@slave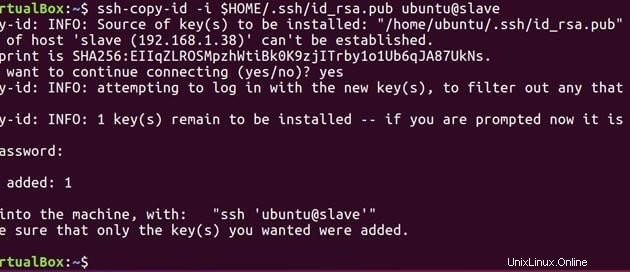
マスターとスレーブの両方に公開鍵があるので、マスターをマスターに接続し、マスターをスレーブに接続することもできます。
ssh master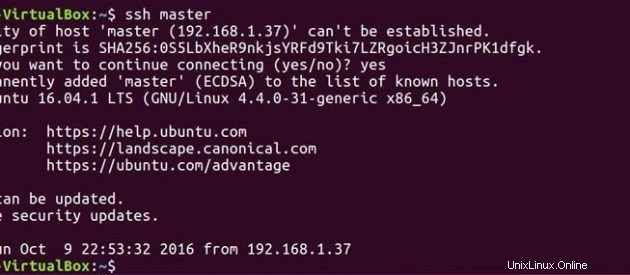
ssh slave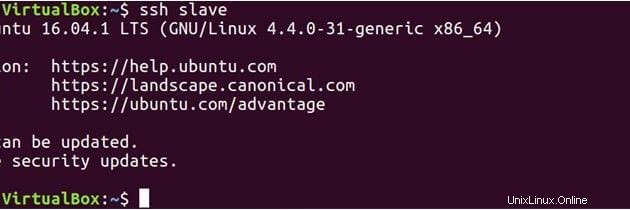
マスターについて
以下のようにマスターファイルを編集します。
sudo gedit hadoop-2.7.3/etc/hadoop/masters
以下のようにスレーブファイルを編集します。
sudo gedit hadoop-2.7.3/etc/hadoop/slaves
スレーブ上
以下のようにマスターファイルを編集します。
sudo gedit hadoop-2.7.3/etc/hadoop/masters4)Hadoopのインストール
これで、javaとsshのセットアップの準備が整いました。両方のシステムにHadoopをインストールするのは良いことです。以下のリンクを使用して、hadoopパッケージをダウンロードします。最新の安定バージョンhadoop2.7.3を使用しています
http://hadoop.apache.org/releases.html
マスターについて
以下のコマンドはhadoop-2.7.3をダウンロードします tarファイル。
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz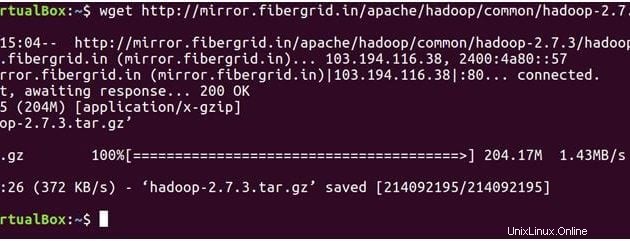
lsファイルを解凍する
tar -xvf hadoop-2.7.3.tar.gz
ls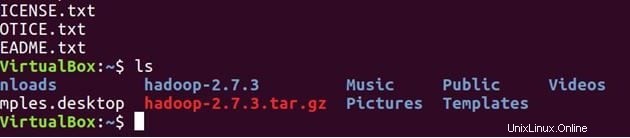
システムにHadoopがインストールされていることを確認します。
cd hadoop-2.7.3/
bin/hadoop-2.7.3/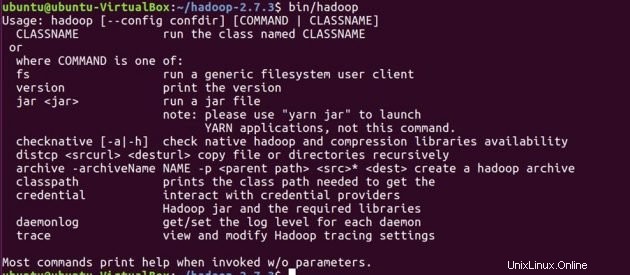
hadoopの構成を設定する前に、以下の環境変数を.bashrcファイルに設定します。
cd
sudo gedit .bashrcHadoop環境変数
# Set Hadoop-related environment variables
export HADOOP_HOME=$HOME/hadoop-2.7.3
export HADOOP_CONF_DIR=$HOME/hadoop-2.7.3/etc/hadoop
export HADOOP_MAPRED_HOME=$HOME/hadoop-2.7.3
export HADOOP_COMMON_HOME=$HOME/hadoop-2.7.3
export HADOOP_HDFS_HOME=$HOME/hadoop-2.7.3
export YARN_HOME=$HOME/hadoop-2.7.3
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HOME/hadoop-2.7.3/bin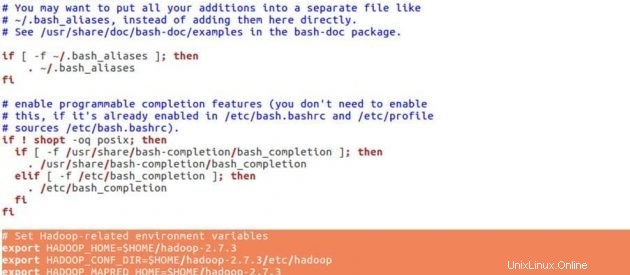
.bashrcの最後に下の行を入力します ファイル、ファイルを保存して閉じます。
source .bashrc「hadoop-env.sh」でJAVA_HOMEを構成します 。このファイルは、Hadoop起動スクリプトによって開始されるApacheHadoop2.7.3デーモンによって使用されるJDKに影響を与える環境変数を指定します。
cd hadoop-2.7.3/etc/hadoop/sudo gedit hadoop-env.sh
export JAVA_HOME =/ usr / lib / jvm / java-7-openjdk-amd64

上記のようにJavaパスを設定し、ファイルを保存して閉じます。
次に、 NameNodeを作成します およびDataNode ディレクトリ。
cd
mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/namenode
mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/datanode
Hadoopには多くの構成ファイルがあり、Hadoopインフラストラクチャの要件に従って構成する必要があります。 Hadoop構成ファイルを1つずつ構成しましょう。
cd hadoop-2.7.3/etc/hadoop/
sudo gedit core-site.xmlCore-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>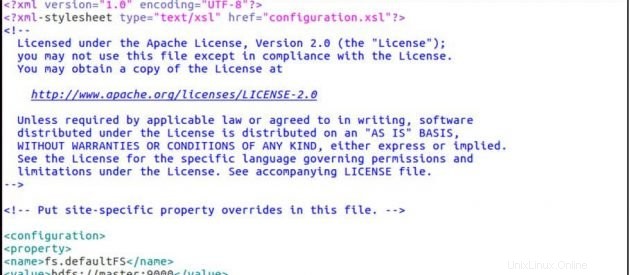
sudo gedit hdfs-site.xmlhdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/datanode</value>
</property>
</configuration>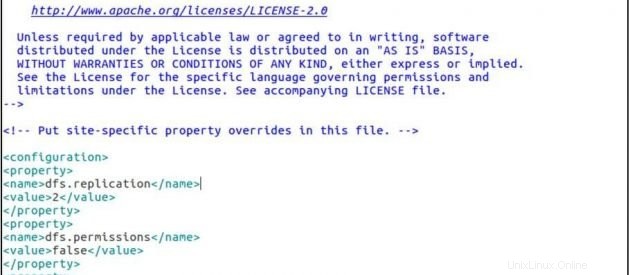
sudo gedit yarn-site.xmlyarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
cp mapred-site.xml.template mapred-site.xml
sudo gedit mapred-site.xmlmapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>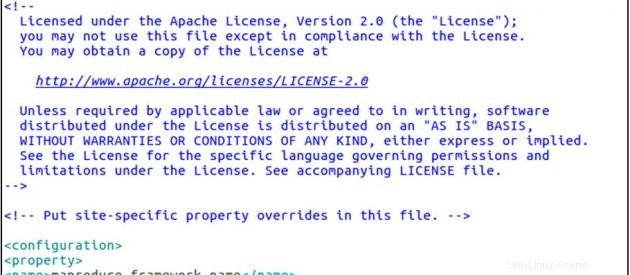
次に、スレーブマシンでも同じhadoopのインストールと構成の手順に従います。両方のシステムにHadoopをインストールして構成した後、Hadoopクラスターを起動する最初のことはフォーマットです。 hadoopファイルシステム 、クラスターのローカルファイルシステムの上に実装されます。これは、Hadoopの初回インストール時に必要です。実行中のhadoopファイルシステムをフォーマットしないでください。フォーマットするとすべてのHDFSデータが消去されます。
マスターについて
cd
cd hadoop-2.7.3/bin
hadoop namenode -format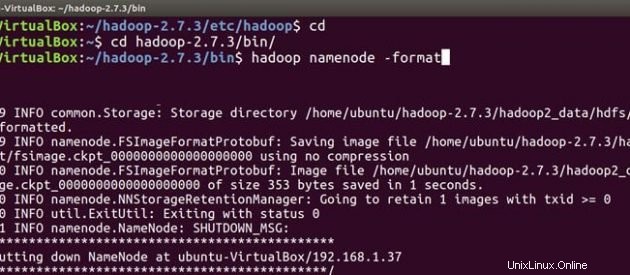
これで、Hadoopデーモン( NameNode、DataNode、ResourceManager )を起動する準備が整いました。 およびNodeManager ApacheHadoopクラスターで。
cd ..次に、以下のコマンドを実行して、マスターマシンでNameNodeを起動し、マスターとスレーブでDataNodeを起動します。
sbin/start-dfs.sh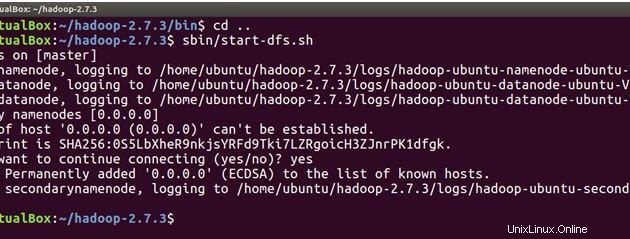
以下のコマンドはYARNデーモンを起動し、ResourceManagerはマスターで実行され、NodeManagerはマスターとスレーブで実行されます。
sbin/start-yarn.sh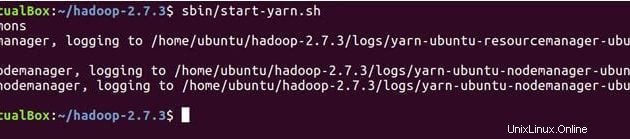
JPS(Java Process Monitoring Tool)を使用して、すべてのサービスが正しく開始されていることをクロスチェックします。マスターマシンとスレーブマシンの両方で。
以下は、マスターマシンで実行されているデーモンです。
jps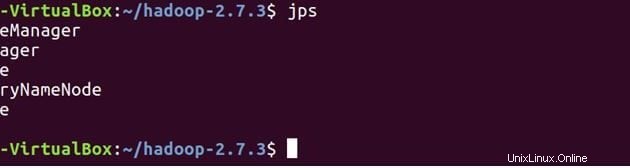
スレーブ上
DataNodeとNodeManagerがスレーブマシンでも実行されていることがわかります。
jps
次に、マスターマシンでMozillaブラウザーを開き、以下のURLに移動します
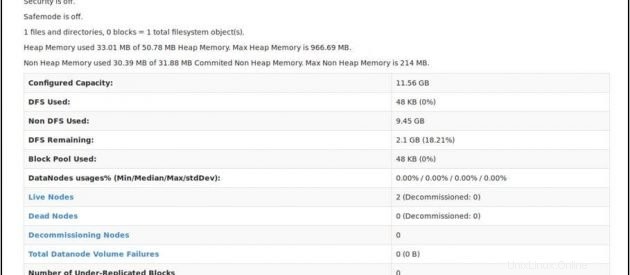
NameNodeのステータスを確認します: http:// master:50070 / dfshealth.html
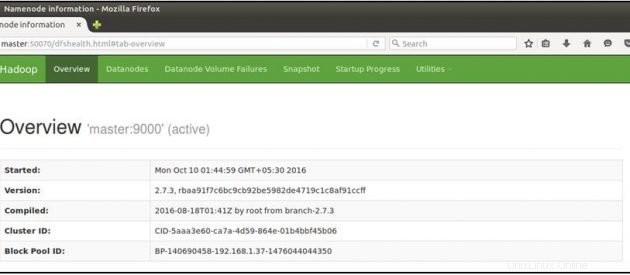
'2'が表示された場合 ライブノード 、つまり2つのDataNode が稼働していて、マルチノードのHadoopカルスターを正常にセットアップできました。
結論
Hadoopクラスターにノードを追加できます。必要なのは、新しいスレーブノードIPをマスターのスレーブファイルに追加し、sshキーを新しいスレーブノードにコピーし、マスターIPを新しいスレーブノードのマスターファイルに入れてから再起動することです。 hadoopサービス。おめでとう!!これで、マルチノードのHadoopクラスターが正常にセットアップされました。