はじめに
すべての主要な業界は、ビッグデータを処理および保存するための標準フレームワークとしてApacheHadoopを実装しています。 Hadoopは、数百または数千の専用サーバーのネットワーク全体にデプロイされるように設計されています。これらのマシンはすべて連携して、大量のさまざまな受信データセットを処理します。
単一ノードにHadoopサービスをデプロイすることは、基本的なHadoopコマンドと概念を理解するための優れた方法です。
このわかりやすいガイドは、Ubuntu18.04またはUbuntu20.04にHadoopをインストールするのに役立ちます。

前提条件
- ターミナルウィンドウ/コマンドラインへのアクセス
- 須藤 またはルート ローカル/リモートマシンの特権
UbuntuにOpenJDKをインストールする
HadoopフレームワークはJavaで記述されており、そのサービスには互換性のあるJavaランタイム環境(JRE)とJava Development Kit(JDK)が必要です。新しいインストールを開始する前に、次のコマンドを使用してシステムを更新します。
sudo apt update現時点では、 ApacheHadoop3.xはJava8を完全にサポートしています 。 UbuntuのOpenJDK8パッケージには、ランタイム環境と開発キットの両方が含まれています。
ターミナルで次のコマンドを入力して、OpenJDK8をインストールします。
sudo apt install openjdk-8-jdk -yOpenJDKまたはOracleJavaバージョンは、Hadoopエコシステムの要素がどのように相互作用するかに影響を与える可能性があります。特定のJavaバージョンをインストールするには、UbuntuにJavaをインストールする方法に関する詳細なガイドを確認してください。
インストールプロセスが完了したら、現在のJavaバージョンを確認します。
java -version; javac -version出力は、どのJavaエディションが使用されているかを通知します。

Hadoop環境の非rootユーザーを設定する
特にHadoop環境では、root以外のユーザーを作成することをお勧めします。個別のユーザーはセキュリティを向上させ、クラスターをより効率的に管理するのに役立ちます。 Hadoopサービスがスムーズに機能するようにするには、ユーザーはローカルホストとのパスワードなしのSSH接続を確立できる必要があります。
UbuntuにOpenSSHをインストールする
次のコマンドを使用して、OpenSSHサーバーとクライアントをインストールします。
sudo apt install openssh-server openssh-client -y以下の例では、出力は最新バージョンがすでにインストールされていることを確認します。

OpenSSHを初めてインストールした場合は、この機会を利用して、これらの重要なSSHセキュリティの推奨事項を実装してください。
Hadoopユーザーの作成
adduserを利用する 新しいHadoopユーザーを作成するコマンド:
sudo adduser hdoopこの例では、ユーザー名は hdoopです。 。適切と思われるユーザー名とパスワードを自由に使用できます。新しく作成したユーザーに切り替えて、対応するパスワードを入力します:
su - hdoopユーザーは、パスワードの入力を求められることなく、ローカルホストにSSHで接続できる必要があります。
Hadoopユーザーに対してパスワードなしのSSHを有効にする
SSHキーペアを生成し、保存する場所を定義します:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsaシステムはSSHキーペアの生成と保存に進みます。
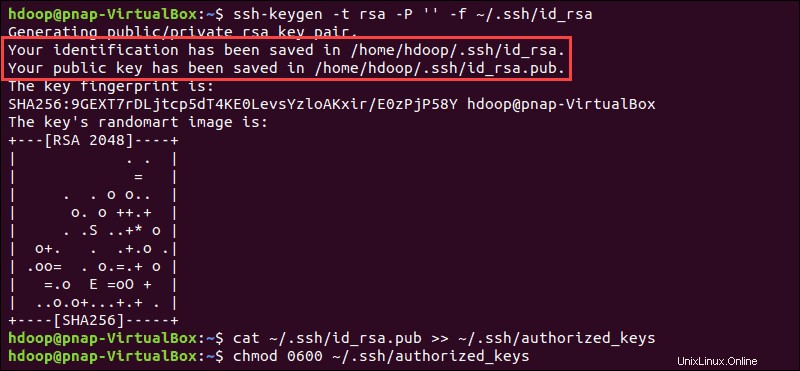
catを使用する 公開鍵をauthorized_keysとして保存するコマンド ssh ディレクトリ:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmodを使用してユーザーの権限を設定します コマンド:
chmod 0600 ~/.ssh/authorized_keysこれで、新しいユーザーは毎回パスワードを入力しなくてもSSHで接続できます。 hdoop を使用して、すべてが正しく設定されていることを確認します ユーザーからローカルホストへのSSH:
ssh localhost最初のプロンプトの後、HadoopユーザーはローカルホストへのSSH接続をシームレスに確立できるようになりました。
UbuntuにHadoopをダウンロードしてインストールする
Apache Hadoopプロジェクトの公式ページにアクセスし、実装するHadoopのバージョンを選択します。
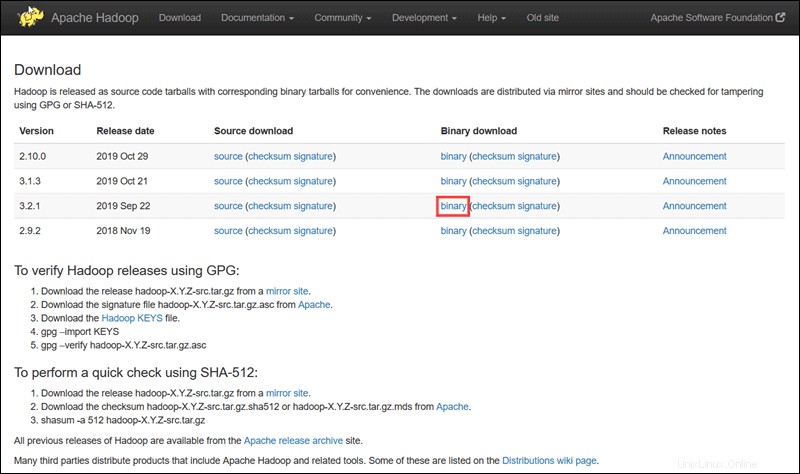
このチュートリアルで概説されている手順では、Hadoopバージョン3.2.1のバイナリダウンロードを使用します。 。
好みのオプションを選択すると、Hadooptarパッケージをダウンロードできるミラーリンクが表示されます。 。
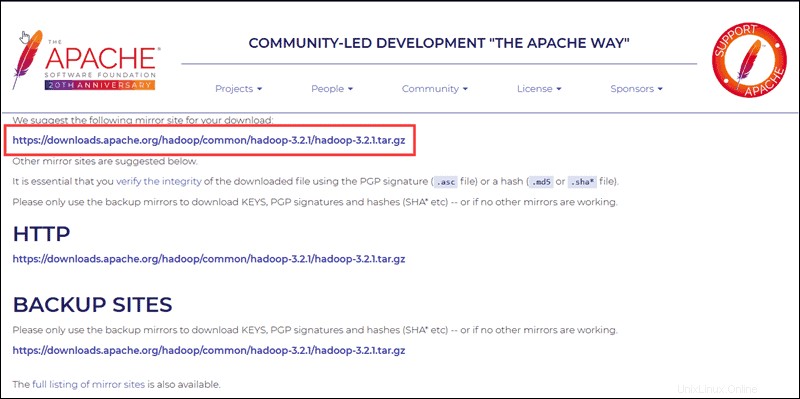
提供されているミラーリンクを使用して、 wgetを含むHadoopパッケージをダウンロードします コマンド:
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
ダウンロードが完了したら、ファイルを抽出してHadoopのインストールを開始します。
tar xzf hadoop-3.2.1.tar.gzこれで、Hadoopバイナリファイルは hadoop-3.2.1内に配置されます。 ディレクトリ。
シングルノードHadoopデプロイメント(疑似分散モード)
Hadoopは、完全分散モードでデプロイすると優れています ネットワークサーバーの大規模なクラスター上。 ただし、Hadoopを初めて使用し、基本的なコマンドやテストアプリケーションを調べたい場合は、単一のノードでHadoopを構成できます。
この設定は、疑似分散モードとも呼ばれます 、各Hadoopデーモンを単一のJavaプロセスとして実行できるようにします。 Hadoop環境は、一連の構成ファイルを編集することで構成されます。
- bashrc
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site-xml
- yarn-site.xml
Hadoop環境変数の構成(bashrc)
.bashrcを編集します 選択したテキストエディタを使用したシェル構成ファイル(nanoを使用します):
sudo nano .bashrcファイルの最後に次のコンテンツを追加して、Hadoop環境変数を定義します。
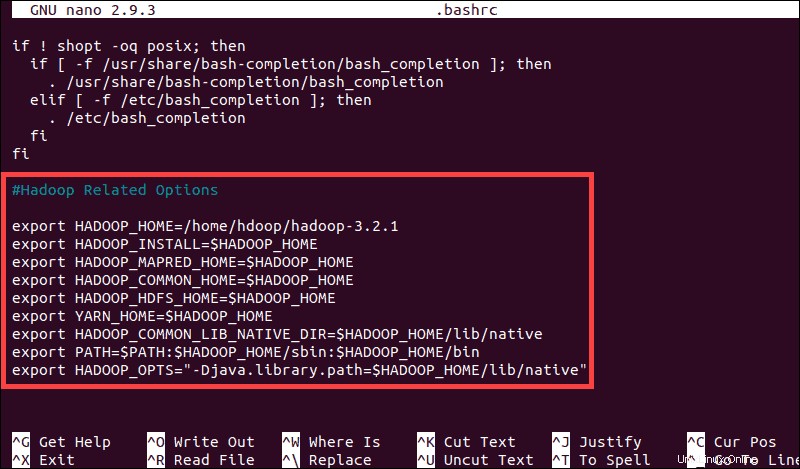
#Hadoop Related Options
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS"-Djava.library.path=$HADOOP_HOME/lib/nativ"
変数を追加したら、 .bashrcを保存して終了します。 ファイル。
次のコマンドを使用して、現在の実行環境に変更を適用することが重要です。
source ~/.bashrchadoop-env.shファイルを編集
hadoop-env.sh ファイルは、YARN、HDFS、MapReduce、およびHadoop関連のプロジェクト設定を構成するためのマスターファイルとして機能します。
シングルノードHadoopクラスターをセットアップする場合 、使用するJava実装を定義する必要があります。以前に作成した$HADOOP_HOMEを使用します hadoop-env.shにアクセスするための変数 ファイル:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
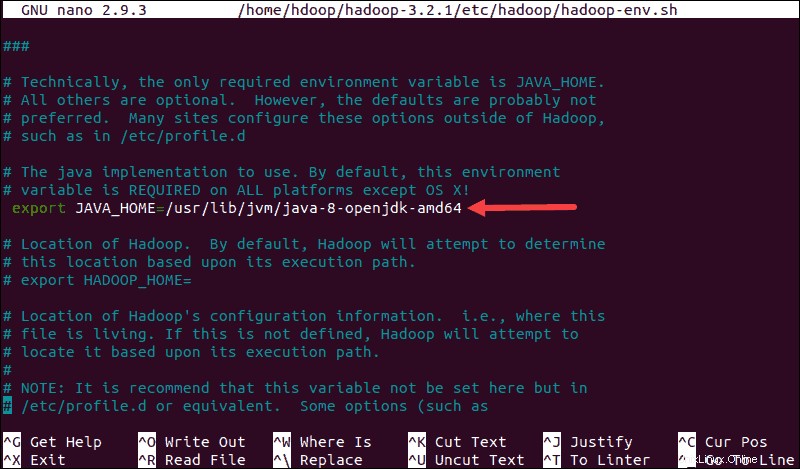
$JAVA_HOMEのコメントを解除します 変数(つまり、 #を削除します 署名)そして、システム上のOpenJDKインストールへのフルパスを追加します。このチュートリアルの最初の部分で示したものと同じバージョンをインストールした場合は、次の行を追加します。
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64パスは、システム上のJavaインストールの場所と一致する必要があります。
正しいJavaパスを見つけるためのヘルプが必要な場合は、ターミナルウィンドウで次のコマンドを実行します。
which javac結果の出力は、Javaバイナリディレクトリへのパスを提供します。

提供されたパスを使用して、次のコマンドでOpenJDKディレクトリを検索します。
readlink -f /usr/bin/javac
/ bin / javacの直前のパスのセクション ディレクトリは$JAVA_HOMEに割り当てる必要があります 変数。

core-site.xmlファイルの編集
core-site.xml ファイルはHDFSとHadoopのコアプロパティを定義します。
疑似分散モードでHadoopを設定するには、URLを指定する必要があります NameNodeの場合、およびHadoopがマップおよびリデュースプロセスに使用する一時ディレクトリ。
core-site.xmlを開きます テキストエディタのファイル:
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml次の構成を追加して一時ディレクトリのデフォルト値を上書きし、HDFSURLを追加してデフォルトのローカルファイルシステム設定を置き換えます。
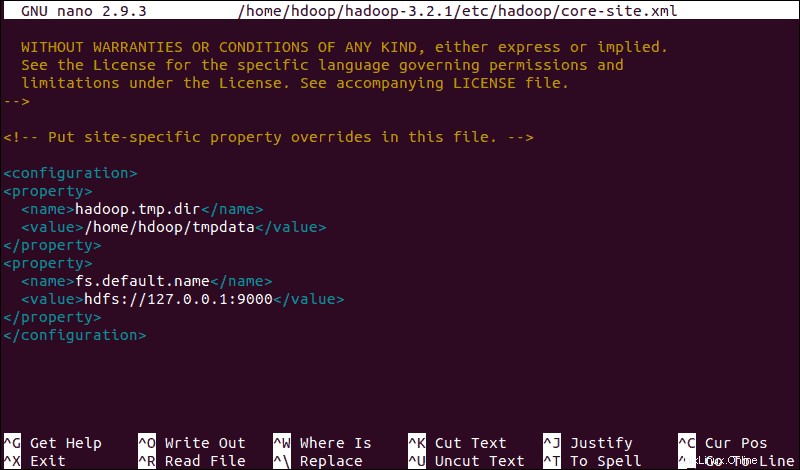
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdoop/tmpdata</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>この例では、ローカルシステムに固有の値を使用しています。システム要件に一致する値を使用する必要があります。データは、構成プロセス全体で一貫している必要があります。
一時データ用に指定した場所にLinuxディレクトリを作成することを忘れないでください。
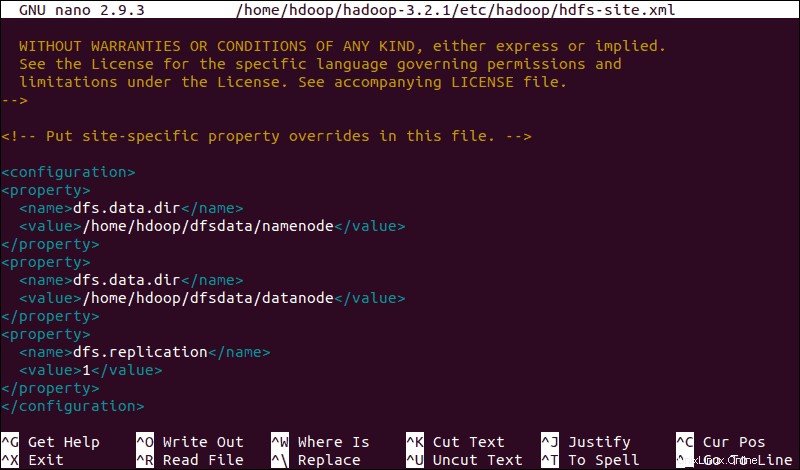
hdfs-site.xmlファイルを編集
hdfs-site.xmlのプロパティ fileは、ノードメタデータ、fsimageファイル、および編集ログファイルを保存する場所を管理します。 NameNodeを定義してファイルを構成します およびDataNodeストレージディレクトリ 。
さらに、デフォルトの dfs.replication 3の値 1に変更する必要があります 単一ノードの設定に一致します。
次のコマンドを使用して、 hdfs-site.xmlを開きます。 編集用ファイル:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml次の構成をファイルに追加し、必要に応じて、NameNodeおよびDataNodeディレクトリをカスタムの場所に調整します。
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
必要に応じて、 dfs.data.dir用に定義した特定のディレクトリを作成します 値。
mapred-site.xmlファイルを編集
次のコマンドを使用して、 mapred-site.xmlにアクセスします。 ファイルとMapReduce値の定義 :
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
次の構成を追加して、デフォルトのMapReduceフレームワーク名の値を yarnに変更します :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>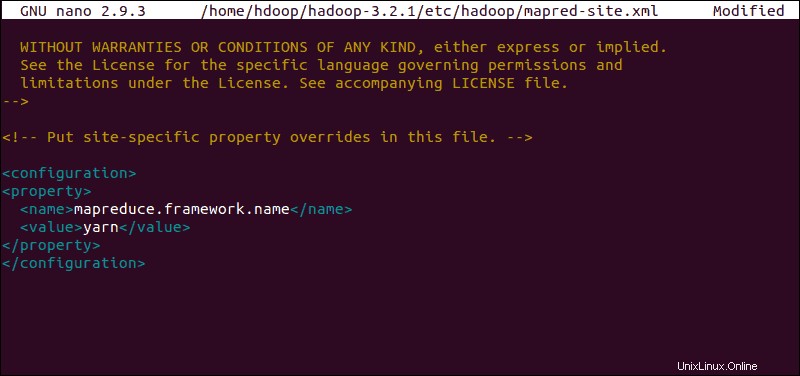
yarn-site.xmlファイルを編集
yarn-site.xml ファイルは、 YARNに関連する設定を定義するために使用されます 。 ノードマネージャー、リソースマネージャー、コンテナーの構成が含まれています およびアプリケーションマスター 。
yarn-site.xmlを開きます テキストエディタのファイル:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml次の構成をファイルに追加します。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>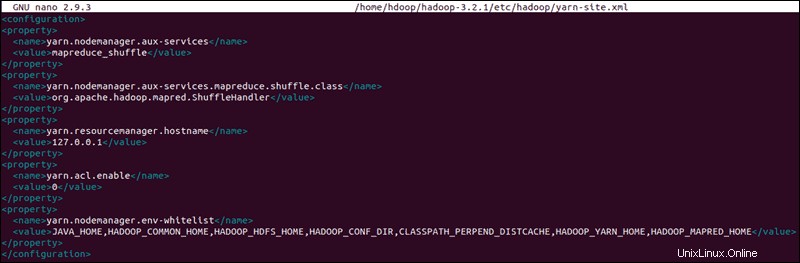
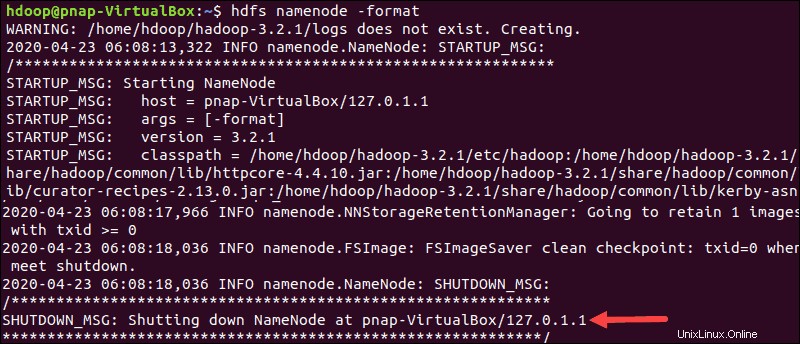
HDFSNameNodeのフォーマット
NameNodeをフォーマットすることが重要です Hadoopサービスを初めて開始する前に:
hdfs namenode -formatシャットダウン通知は、NameNodeフォーマットプロセスの終了を示します。
Hadoopクラスターを開始する
hadoop-3.2.1 / sbinに移動します ディレクトリを作成し、次のコマンドを実行してNameNodeとDataNodeを起動します。
./start-dfs.shシステムは、必要なノードを開始するのに少し時間がかかります。

namenode、datanodes、およびsecondary namenodeが稼働状態になったら、次のように入力してYARNリソースとノードマネージャーを起動します。
./start-yarn.sh前のコマンドと同様に、出力はプロセスが開始されていることを通知します。

次の簡単なコマンドを入力して、すべてのデーモンがアクティブであり、Javaプロセスとして実行されているかどうかを確認します。
jpsすべてが意図したとおりに機能している場合、実行中のJavaプロセスの結果リストには、すべてのHDFSデーモンとYARNデーモンが含まれます。

ブラウザからHadoopUIにアクセスする
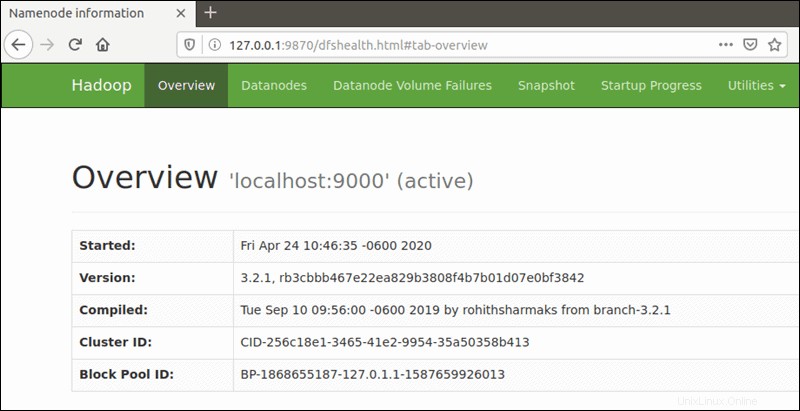
好みのブラウザを使用して、ローカルホストのURLまたはIPに移動します。デフォルトのポート番号9870 Hadoop NameNode UIへのアクセスを提供します:
http://localhost:9870NameNodeのユーザーインターフェイスは、クラスター全体の包括的な概要を提供します。
デフォルトのポート9864 ブラウザから直接個々のDataNodeにアクセスするために使用されます:
http://localhost:9864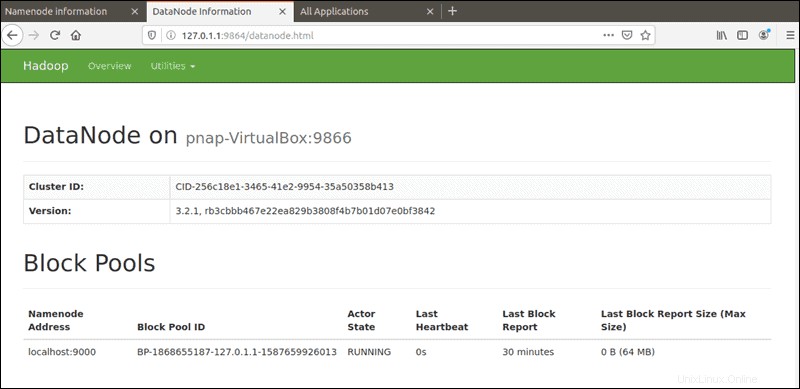
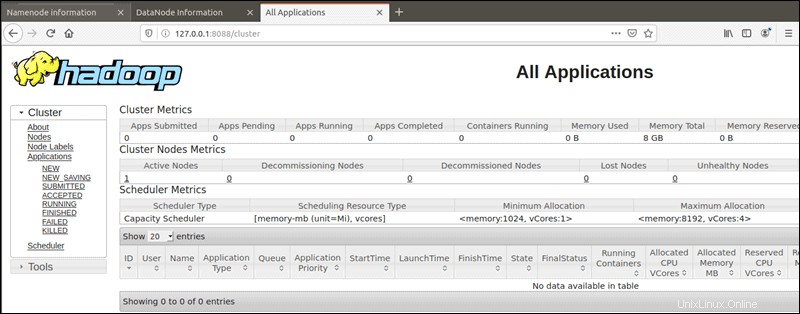
YARN Resource Managerは、ポート 8088からアクセスできます。 :
http://localhost:8088Resource Managerは、Hadoopクラスターで実行中のすべてのプロセスを監視できる非常に貴重なツールです。