はじめに
PostgreSQLは、その堅牢性と拡張性で知られるオープンソースのリレーショナルデータベース管理システムです。これは、PostgreSQLがユーザーにさまざまなデータ型を提供することも意味します。
このチュートリアルでは、PostgreSQLで使用できるさまざまな組み込みデータ型について説明します。

PostgreSQLデータ型
PostgreSQLでテーブルを作成するときに、各列のデータ型を指定できます。 PostgreSQLは、さまざまな組み込みデータ型をサポートしています。
キャラクター
PostgreSQLは文字データ型を使用します テキスト値を格納するため。 PostgreSQLには3つの文字データ型があります:
| 名前 | 説明 |
| character(n)、char(n) | 固定長の文字列。n 文字数です。 nに等しくなるように右側に空白が埋め込まれています 。 |
| 文字の変化(n)、varchar(n) | 文字数制限のある可変長文字列。n は文字数です。 |
| テキスト | 可変長、無制限の文字列。 |
数値タイプ
数値データ型 含める:
- 2バイト、4バイト、および8バイトの整数
- 4バイトおよび8バイトの浮動小数点数
- 選択可能な小数:
| 名前 | ストレージサイズ | 説明 | 範囲 |
| smallint | 2バイト | 小範囲の整数。 | -32768〜 + 32767 |
| 整数 | 4バイト | 中距離整数。 | -2147483648から+2147483647 |
| bigint | 8バイト | 広範囲の整数。 | -9223372036854775808から9223372036854775807 |
| 10進数 | 変数 | ユーザー指定の精度の小数。 | 小数点の前の最大131072桁。小数点以下16383桁まで |
| 数値 | 変数 | ユーザー指定の精度の小数。 | 小数点の前の131072桁まで。小数点以下16383桁まで |
| 本物 | 4バイト | 可変精度の小数。 | 小数点以下6桁の精度 |
| 倍精度 | 8バイト | 可変精度の小数。 | 小数点以下15桁の精度 |
| smallserial | 2バイト | 小さな自動インクリメント整数。 | 1から32767 |
| シリアル | 4バイト | 中程度の自動インクリメント整数。 | 1から2147483647 |
| bigserial | 8バイト | 大きな自動インクリメント整数。 | 1から9223372036854775807 |
金銭
金銭的データ型 固定の小数精度で数値を格納します。このタイプは、-92233720368547758.08〜 + 92233720368547758.07の範囲で最大8バイトのデータを格納し、数値を使用します 、整数 、および bigint 値としてのデータ型。
日付/時刻
PostgreSQLはすべての標準SQL日付と時刻のデータ型をサポートします 、1マイクロ秒または14桁の解像度。日付は唯一の例外であり、グレゴリオ暦に従ってカウントされた1日の解像度です:
| 名前 | ストレージサイズ | 説明 | 範囲 |
| タイムスタンプ | 8バイト | 日付と時刻、タイムゾーンなし。 | 紀元前4713年から西暦294276年 |
| タイムスタンプ | 8バイト | 日付と時刻、タイムゾーン付き。 | 紀元前4713年から西暦294276年 |
| 日付 | 4バイト | 日付。 | 紀元前4713年から西暦294276年 |
| タイムゾーンのない時間 | 8バイト | 時刻、タイムゾーンなし。 | 00:00:00〜24:00:00 |
| タイムゾーンのある時間 | 12バイト | 時刻、タイムゾーン付き。 | 00:00:00 + 1459〜24:00:00-1459 |
| 間隔 | 12バイト | 時間間隔。 | -178000000〜178000000年 |
バイナリ
PostgreSQLは、可変長のバイナリ文字列をbyteaデータ型として保存できます。 、1バイトまたは4バイトに加えて、実際のバイナリ文字列のサイズを使用します。
ブール値
ブールデータ型 boolを使用して宣言されます またはboolean キーワード。 true(1)を保持できます 、 false(0) 、または不明(null) 値。
列挙
列挙型データ型 1から10までの数値や年の月など、静的で順序付けられた値のセットで構成されます。他のデータ型とは異なり、 create typeを使用して列挙型を作成できます コマンド:
CREATE TYPE year AS ENUM ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec');ビット文字列
ビット文字列タイプ ビットマスクを格納または視覚化するために使用される1と0の文字列を格納します:
| 名前 | 説明 |
| bit(n) | 固定長のnのビット文字列を格納します 文字。 |
| Variing(n) | 最大nまでのさまざまな長さのビット文字列を格納します 文字。 |
UUID
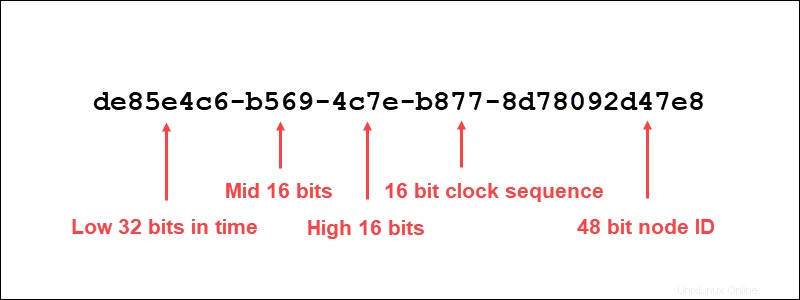
UUID (Universally Unique Identifiers)は、アルゴリズムによって作成された32桁のセットです。これは、ハイフンで区切られた4桁、8桁、および12桁のいくつかのグループで構成されています。
ネットワークアドレス
PostgreSQLはネットワークアドレスデータ型を使用します IPv4、IPv6、およびMACアドレスを保存するには:
| 名前 | ストレージサイズ | 説明 |
| cidr | 7または19バイト | IPv4およびIPv6ネットワークを格納します。 |
| inet | 7または19バイト | IPv4およびIPv6ホストとネットワークを格納します。 |
| macaddr | 6バイト | MACアドレスを保存します。 |
ネットワークアドレスデータ型を使用すると、プレーンテキストを使用するよりもいくつかの利点があります。これには、ストレージスペースの節約、特殊な機能とコマンド、およびより簡単なエラーチェックが含まれます。
テキスト検索
テキスト検索データ型 自然言語のドキュメントのコレクションから最適なものを検索できます:
| 名前 | 説明 |
| tsvector | テキスト検索用に最適化されたドキュメントを表し、同じ単語(語彙素)のさまざまなバリエーションをマージするように正規化された個別の単語のリストを使用します。 |
| tsquery | 検索する必要のあるキーワードを格納し、ブール演算子(AND、OR、およびNOT)を使用してそれらを結合します。 |
幾何学的
幾何学的データ型 ポイント、ライン、ポリゴンなど、2次元でレンダリングされた空間オブジェクトを表します。
| 名前 | ストレージサイズ | 表現 | 数値の説明 |
| ポイント | 16バイト | 平面上のポイント。 | (x、y) |
| 行 | 32バイト | 無限の線。 | ((x1、y1)、(x2、y2)) |
| lseg | 32バイト | 有限線分。 | ((x1、y1)、(x2、y2)) |
| ボックス | 32バイト | 長方形の箱。 | ((x1、y1)、(x2、y2)) |
| パス | 16+16nバイト | オープンパスまたはクローズドパス。 | ((x1、y1)、...(xn、yn)) |
| ポリゴン | 40+16nバイト | ポリゴン。 | ((x1、y1)、...(xn、yn)) |
| サークル | 24バイト | サークル。 | ((x、y)、r)(中心点と半径) |
XML
PostgreSQLでは、XMLデータをXMLデータ型として保存できます。 XMLPARSEを使用する 機能:
XMLPARSE (DOCUMENT [document name] WELLFORMED)または:
XMLPARSE (CONTENT [XML content] WELLFORMED)場所:
-
[document name]:単一ルートのXMLドキュメント。 -
[XML content]:有効なXML値 WELLFORMED:このオプションは、[ドキュメント名]または[XMLコンテンツ]が整形式のXMLドキュメントに解決されることを保証します。入力が整形式であるかどうかをデータベースにチェックさせたくない場合にのみ使用してください。
JSON
PostgreSQLは2つのJSONデータ型を提供します :
- json: JSON検証によるテキストデータ型の拡張。このデータ型は、データをそのまま(空白を含む)保存します。データベースにすばやく挿入できますが、再処理のために取得に比較的時間がかかります。
- jsonb: JSONデータをバイナリ形式で表します。データベースへの挿入は遅くなりますが、インデックス作成のサポートと再処理の欠如により、取得が大幅に高速化されます。

配列
配列データ型 テーブルの列を、任意のベース、列挙、または複合データ型を使用できる多次元配列として定義できます。データベース内の他の列と同じように、配列を宣言、変更、および検索できます。
コンポジット
複合データ型 テーブルの行またはレコードをデータ要素として使用できるようにします。配列データ型と同様に、複合値を宣言、検索、および変更することもできます。
範囲
範囲データ型 他のデータ型の目立たない範囲または連続した範囲を使用します。組み込みの範囲データ型には次のものがあります。
| 名前 | 説明 |
| int4range | 中サイズの整数の範囲。 |
| int8range | 大きな整数の範囲。 |
| numrange | ユーザー指定の精度の小数の範囲。 |
| 奇妙な | タイムゾーンのない時間と日付の範囲。 |
| tstzrange | タイムゾーンを使用した時間と日付の範囲。 |
| daterange | 日付の範囲。 |
他のデータ型をベースとして使用して、カスタム範囲型を作成することもできます。
オブジェクト識別子
PostgreSQLは、特殊な入出力操作を実行するときに、オブジェクト識別子を主キーシステムとして使用します。
| 名前 | 参照 | 説明 |
| oid | 任意 | 数値オブジェクト識別子。 |
| regproc | pg_proc | 関数名。 |
| 手順 | pg_proc | 引数型の関数。 |
| regoper | pg_operator | 演算子名。 |
| 登録者 | pg_operator | 引数型の演算子。 |
| regclass | pg_class | 関係名。 |
| regtype | pg_type | データ型名。 |
| regconfig | pg_ts_config | テキスト検索の構成。 |
| 登録済み | pg_ts_dict | テキスト検索辞書。 |
疑似タイプ
疑似型は、関数の引数または結果型を宣言するための特別なエントリのコレクションです。
| 名前 | 説明 |
| 任意 | 関数は任意の入力データ型を受け入れます。 |
| 任意の要素 | 関数はすべてのデータ型を受け入れます。 |
| anyarray | 関数は任意の配列データ型を受け入れます。 |
| anynonarray | 関数は非配列データ型を受け入れます。 |
| anyenum | 関数は列挙型のデータ型を受け入れます。 |
| 任意の範囲 | 関数は任意の範囲データ型を受け入れます。 |
| cstring | 関数はnullで終了するC文字列を受け入れるか返します。 |
| 内部 | 関数はサーバー内部のデータ型を受け入れるか返します。 |
| language_handler | 関数は言語ハンドラーを返します。 |
| fdw_handler | 外部データラッパーハンドラーはfdw_handlerを返します。 |
| 記録 | 指定されていない行タイプを返す関数を検索します。 |
| トリガー | トリガー関数はトリガーを返します。 |
| void | 関数は値を返しません。 |