はじめに
Kibanaは、強力な視覚化およびクエリプラットフォームであり、ELKスタックの主要なビジュアルコンポーネントです。このツールには、データをクエリ、視覚化、実用的な情報に変換するための多くの便利な機能を備えた、すっきりとしたユーザーインターフェースがあります。
このチュートリアルでは、Kibanaでのデータのクエリと視覚化に関する例と説明を提供します。

前提条件
- Kibanaをデプロイして構成しました。
- WebトラフィックのサンプルKibanaデータ。
- Kibanaダッシュボードにアクセスするためのブラウザ。
Kibanaとは何ですか?
Kibanaは、ブラウザーベースの視覚化、探索、および分析プラットフォームです。 ElasticsearchおよびLogstashとともに、KibanaはElasticスタックの重要なコンポーネントです。直感的なユーザーインターフェイスは、さまざまなプロット、チャート、グラフ、およびマップを介して、インデックス付きのElasticsearchデータを図に作成するのに役立ちます。
Kibanaは何に使用されますか?
Kibanaは、大量の半構造化ログデータをクエリおよび分析するためのツールです。 ELKスタックでは、KibanaはElasticsearchに保存されているデータのウェブインターフェースとして機能します。
いくつかのユースケースは次のとおりです。
- ウェブサイトのトラフィックのリアルタイム分析。
- 感覚データの分析と監視。
- eコマースウェブサイトの販売統計。
- メール配信モニター。
Kibanaは、視覚化、分析、データ探索に加えて、Elasticsearchの承認と認証を管理するためのユーザーインターフェイスを提供します。
Kibanaの機能
Kibanaには多くのエキサイティングな機能があります。以下の表に、いくつかの注目すべき機能の概要を示します。
| 機能 | 説明 |
|---|---|
| 視覚化 | Core Kibanaは、円グラフ、ヒストグラム、線グラフなどの従来のグラフインターフェイスを備えています。 |
| ダッシュボード | 1つのダッシュボードペインにさまざまな視覚化をまとめると、よりわかりやすいデータの概要が作成されます。 |
| レポートの生成と共有 | CSVテーブルの生成、視覚化の埋め込み、URLによる共有。 |
| 検索とフィルタリング | 直感的なKibanaクエリ言語(KQL)を使用したデータフィルタリングとクエリ。 |
| プラグイン | 3Dグラフ、カレンダーの視覚化、Prometheusエクスポーターなどの追加の視覚化およびUIツールは、プラグインを介して利用できます。 |
| 地理空間分析 | 空間データを視覚化すると、現実的な位置ビューが提供されます。 |
| 時系列分析 | 集計を使用した時系列データ分析用のビジュアルビルダー。 |
| キャンバス | 完全にカスタマイズ可能な色、形、テキスト、動的なプレゼンテーションのクエリ。 |
Kibanaインデックスパターン
インデックスパターンは、ElasticsearchがKibanaと通信する方法です。定義されたインデックスパターンは、Elasticsearchから取得して使用するデータをKibanaに指示します。次の手順に従って、インデックスパターンを追加します。
1.ページ上部の検索バーは、Kibanaのオプションを見つけるのに役立ちます。 CTRLを押します + / または、検索バーをクリックして検索を開始します。
2.インデックスパターンと入力します 。 Enterを押します 検索結果を選択します。
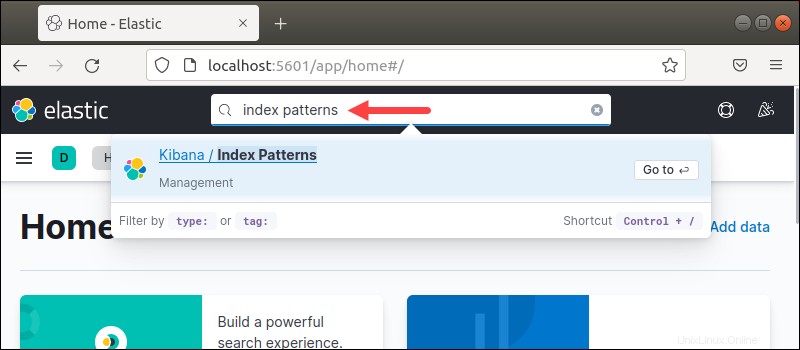
検索では大文字と小文字は区別されません。
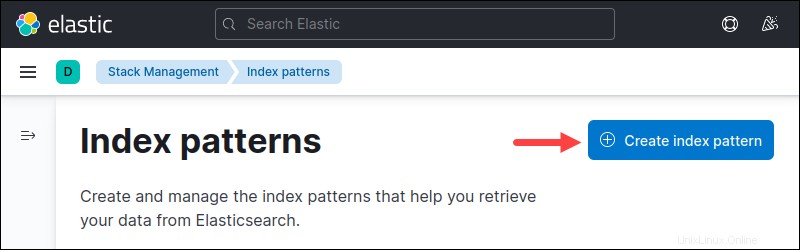
3.インデックスパターン ページが開きます。 インデックスパターンの作成をクリックします インデックスパターンを作成します。
4.インデックスパターンを定義するには、追加するインデックスを正確な名前で検索します。アスタリスクを使用します( * )厳密に一致する場合、または類似した名前の複数のインデックスを一致させる場合。
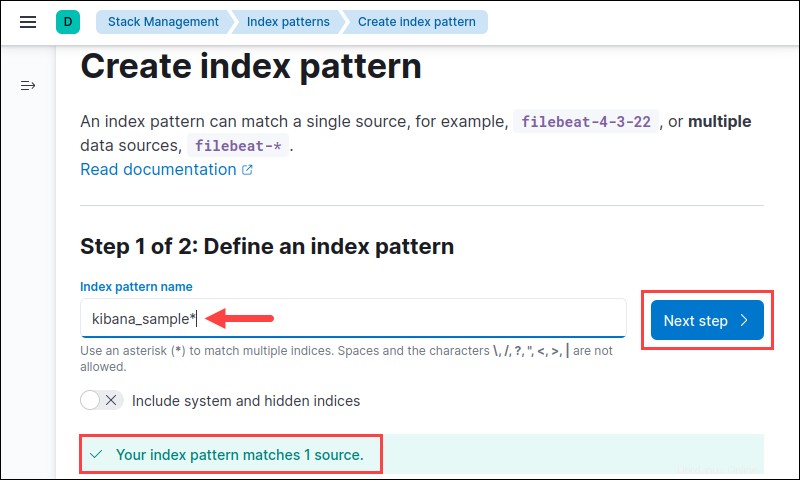
インデックス名がわからない場合は、利用可能なインデックスパターンが下部に一覧表示されます。チュートリアルでは、KibanaのサンプルWebトラフィックデータを使用しています。 次のステップをクリックします 続行します。
5.データにタイムスタンプ付きのインデックスがある場合は、データを時間でフィルタリングするためのデフォルトの時間フィールドを指定します。ドロップダウンメニューから適切なオプションを選択します。
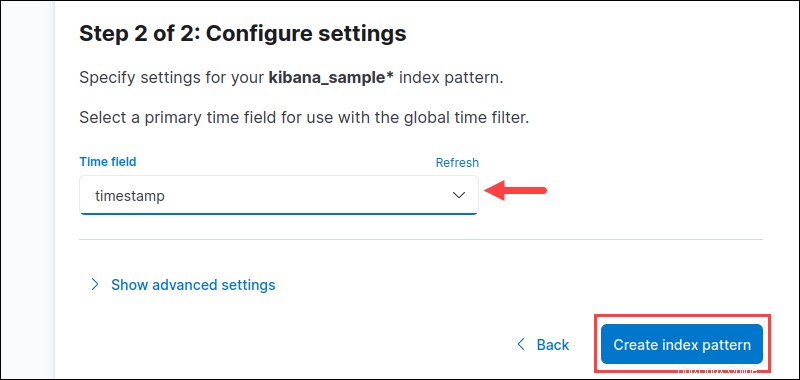
または、時間フィルターを使用したくないを選択します 時間データまたはマージ時間フィールドがない場合のオプション。 インデックスパターンの作成を押します ボタンを押して終了します。
6.データを調べるには、「検出」と入力します 検索バーで( CTRL + / )そして Enterを押します 。
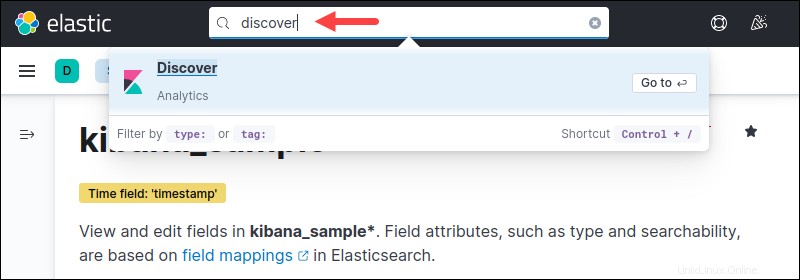
7.左側のペインのドロップダウンメニューからインデックスパターンを選択します。
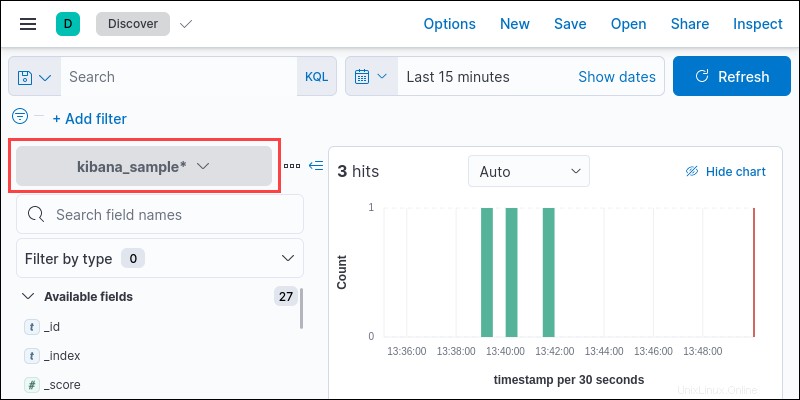
検出ページには、作成されたインデックスパターンのデータが表示されます。
Kibana Search
Kibanaは、データに対してクエリを実行するためのさまざまなメソッドを提供します。検索フィールドをクリックすると、提案とオートコンプリートのオプションが表示され、学習曲線がスムーズになります。後で視覚化に使用するためにコードを保存します。
以下は、情報を検索するための最も一般的な方法と、ベストプラクティスです。
KQLとLucene
バージョン6.2以前のバージョンでは、Luceneを使用してデータをクエリしていました。新しいバージョンでは、検索を改善するためにKueryまたはKQL言語を使用するオプションが追加されました。 7.0以降のバージョンはデフォルトでKQLを使用し、Luceneに戻す選択肢を提供します。
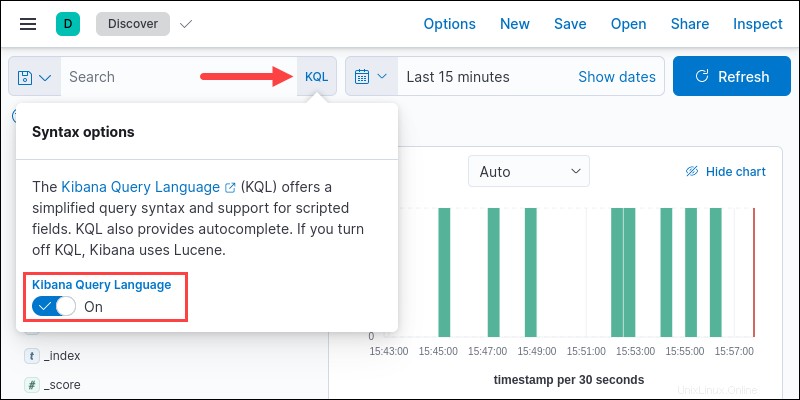
言語をLuceneに変更するには、 KQLをクリックします 検索バーのボタン。 Kibanaクエリ言語を変更する オフのオプション 。
テキスト検索
フィールドやローカルステートメントのない検索ボックスを使用して、使用可能なすべてのデータフィールドでフリーテキスト検索を実行します。
データが表示されない場合は、検索ボックスの横にある時間フィールドを拡大して、より広い範囲をキャプチャしてみてください。
単一単語クエリ
elasticsearchという単語を検索しています すべてのフィールドのデータ内のすべてのインスタンスを検索します。
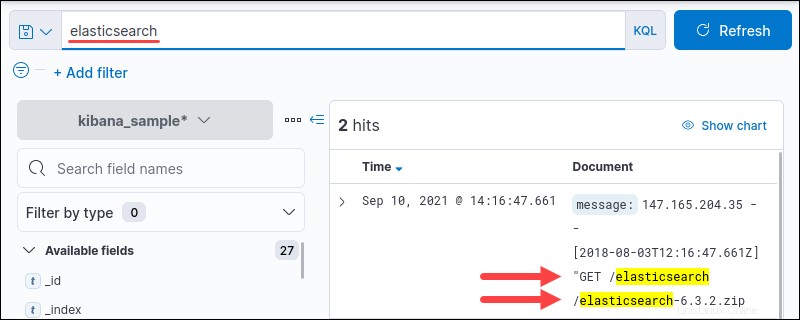
Kibanaでのクエリでは、大文字と小文字は区別されません。アスタリスク記号を使用します( * )あいまい文字列検索の場合。
マルチワードクエリ
スペースバーを押して単語を区切り、複数の個別の用語をクエリします。
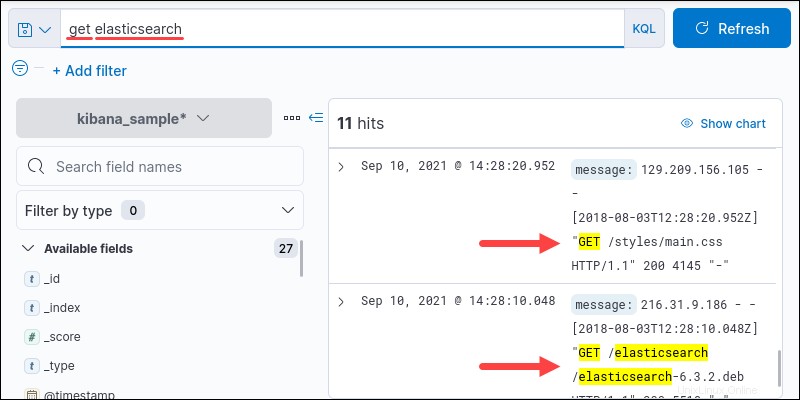
たとえば、 get elasticsearch elasticsearchを検索します およびget 別の言葉として。
文字列クエリ
正確な文字列に一致させるには、引用符を使用します。
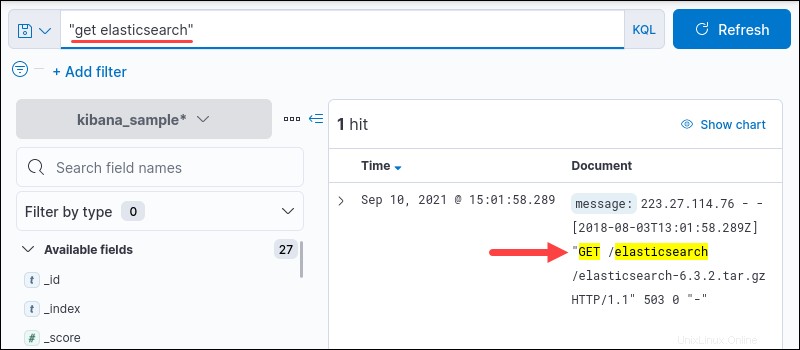
たとえば、 "get elasticsearch" 文字列全体をクエリします。
フィールド検索
Kibanaでは、個々のフィールドを検索できます。左下のメニューペインの[使用可能なフィールド]の下にある使用可能なすべてのフィールドを確認します :
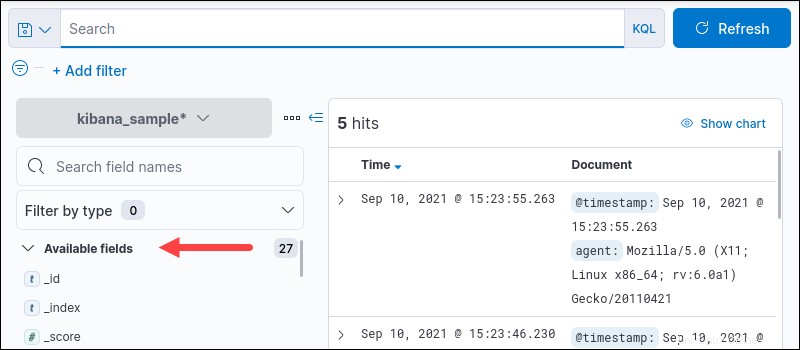
特定のフィールドで検索を実行するには、次の構文を使用します。
<field name> : <query>クエリの構文は、フィールドタイプによって異なります。
正確なフレーズの検索フィールド
たとえば、 response.keywordを検索します "404"のフィールド メッセージ応答:
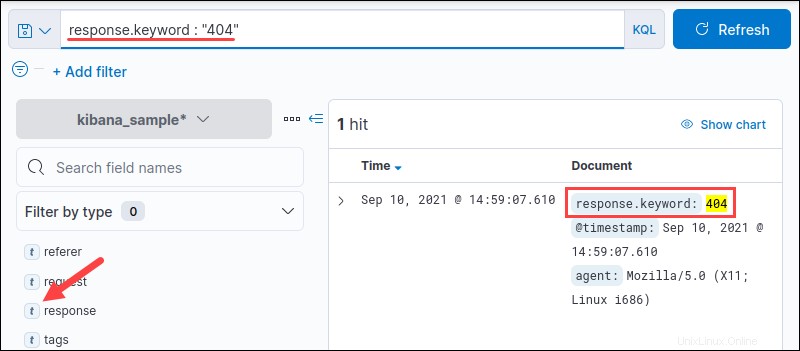
出力には、指定されたフィールドで一致したすべてのインスタンスが表示されます。クエリ用語をスペースで区切って複数の値を検索します:
response.keyword : 404 200フィールドタイプがtに設定されていることに注意してください 、フィールドがテキストタイプであることを示します 。
検索フィールド範囲
多くの場合、数値と日付のタイプには範囲が必要です。 KQLは4つの範囲演算子をサポートしています。
- より大きい(>)。
- 未満(<)。
- (> =)以上。
- (<=)以下。
たとえば、日付範囲を検索します:
@timestamp <= "2021-09-02"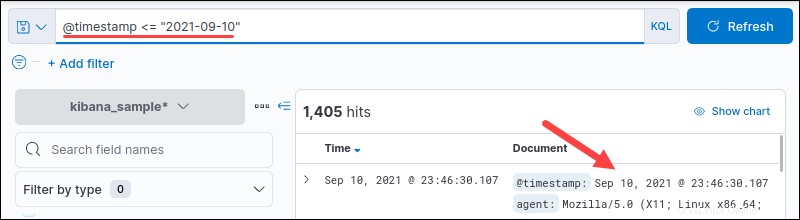
出力には、リストされた日付より前のすべての日付が表示されます。
ブールクエリ
論理ステートメントは、2つ以上のクエリを分析して真理値を求めます。論理演算子は視覚的な理由から大文字であり、小文字でも同様に機能します。ブールクエリは、テキストクエリまたはフィールドの検索の両方で実行されます。
KQLには3つの論理演算子があります:
1. AND 演算子では、両方の用語が検索結果に表示される必要があります。 AND を使用する 2つの用語が表示されるすべてのインスタンスを見つけるには:
<query> AND <query>例:
elasticsearch AND get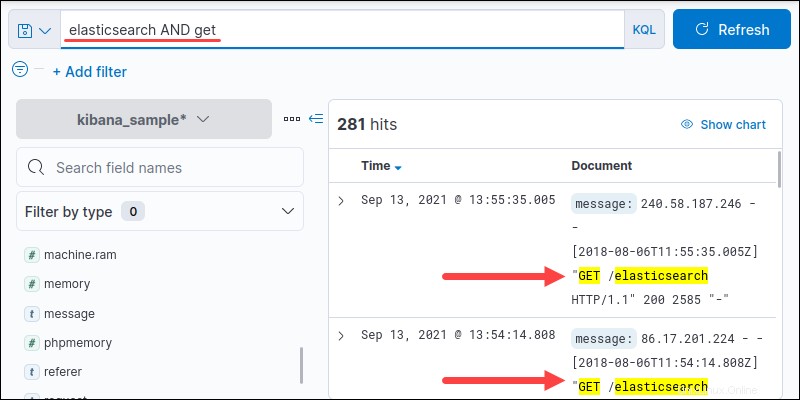
AND を組み合わせる 両方のクエリ用語が特定のフィールドに表示されるすべてのインスタンスを見つけるためのフィールドクエリを使用する演算子:
<field name> : <query> AND <field name> : <query>たとえば、WindowsXPの応答が400であるすべてのインスタンスを検索します。
machine.os.keyword : "win xp" AND response.keyword : "404"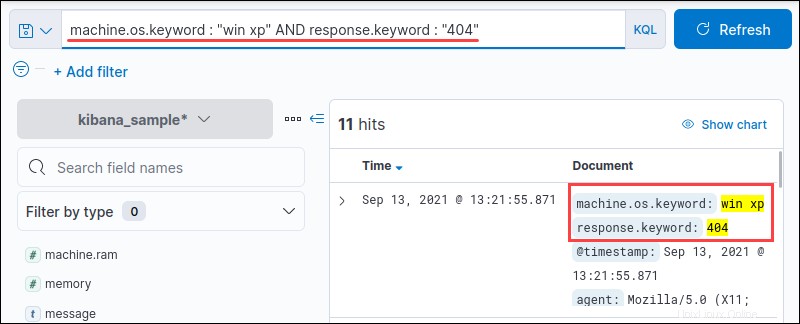
出力には、両方の win xpのすべての結果が表示されます および404 一緒に表示されます。
2.OR 演算子は、真であるために少なくとも1つの引数を必要とします。構文は次のとおりです。
<query> OR <query>例:
elasticsearch OR get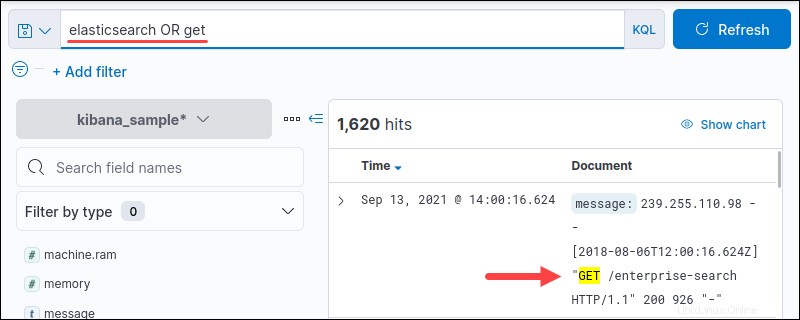
ORをマージします 演算子とフィールドのクエリを使用して、いずれかのクエリ用語が特定のフィールドに表示されるすべてのインスタンスを検索します。
<field name> : <query> OR <field name> : <query>
たとえば、OSがWindows XPであるか、応答が 400であるすべての結果を検索します。 :
machine.os.keyword : "win xp" OR response.keyword : "404"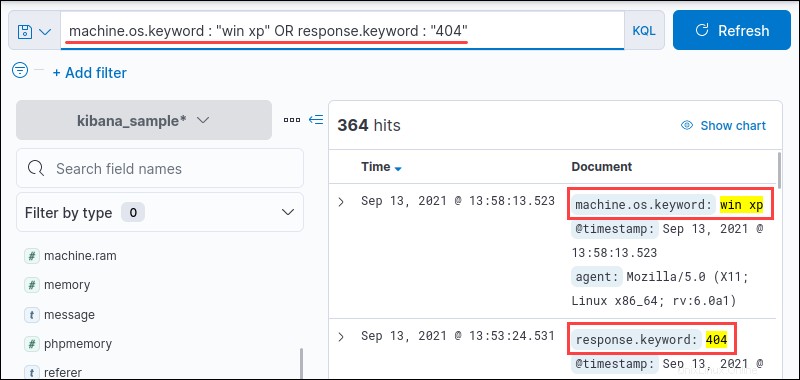
3. NOT 演算子は検索語を否定します。たとえば、 404以外の応答キーワードを検索します :
NOT response.keyword : "404"
または、-を使用します または! 検索語の前に否定を示します。
キバナフィルター
Kibanaフィルターは、検索クエリでフィールドを除外または含めるのに役立ちます。
1.+フィルターの追加をクリックしてフィルターを作成します リンク。
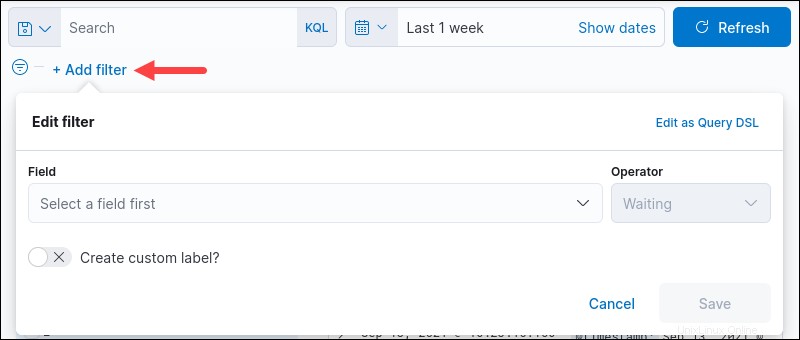
フィルタを作成するためのダイアログボックスが表示されます。
2.フィールドを選択します ドロップダウンメニューから、または検索を開始して自動提案を取得します。
3.オペレーターを選択します ドロップダウンメニューから。
4.追加の値 選択した演算子に応じてフィールドが表示されます。 存在する および存在しません 他のすべての演算子が必要とするのに対し、オプションは[値]フィールドを必要としません。オペレーターが必要とする場合は、フィルタリング値を選択してください。
5.オプションの手順として、フィルターのカスタムラベルを作成します。 カスタムラベルを作成しますか?にチェックマークを付けます チェックボックスをオンにして名前を入力します。 保存をクリックします 終了します。
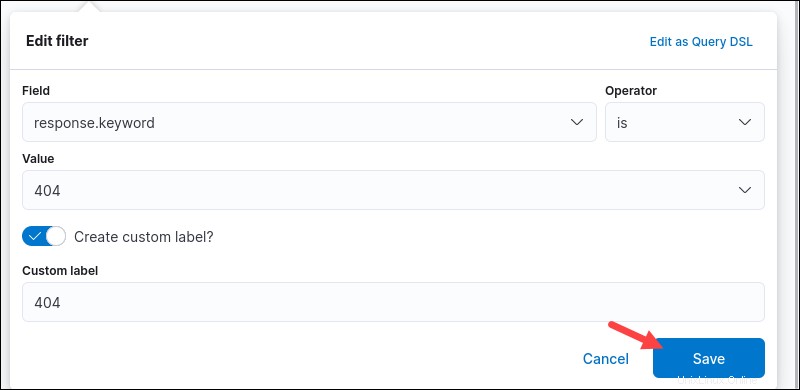
フィルタは検索ボックスの下に表示され、現在のデータとそれ以降のすべての検索に自動的に適用されます。

複数のフィルターを追加して、データセット検索をさらに絞り込みます。
キバナの視覚化
Kibanaでの視覚化は、データを視覚化および表示するための多くのオプションを備えた重要な機能です。
Kibana視覚化タイプ
ビジュアライゼーションを作成する場合、次から選択できる5つのエディターがあります。
1.レンズ ドラッグアンドドロップインターフェイスでビジュアルを作成し、視覚化タイプをすばやく切り替えることができます。ほとんどのユースケースでは、このインターフェースをお勧めします。
2.マップ は、地図上の地理データとレイヤー情報に使用されるエディターです。
3. TSVB は、高度な時系列分析のためのインターフェースです。
4.カスタムビジュアライゼーション Vega構文を使用してカスタムグラフを作成します。
5.集計ベース ビジュアライゼーションは、標準ライブラリを使用してグラフを作成します。
Kibanaは、プレゼンテーションを強化するための2つの追加ツールを追加で提供します。
1.テキストおよび画像ツール。
2.スライダーとドロップダウンメニューを追加するためのコントロールツール。
すべてのツールが連携して、データを表示するためのダッシュボードを作成します。
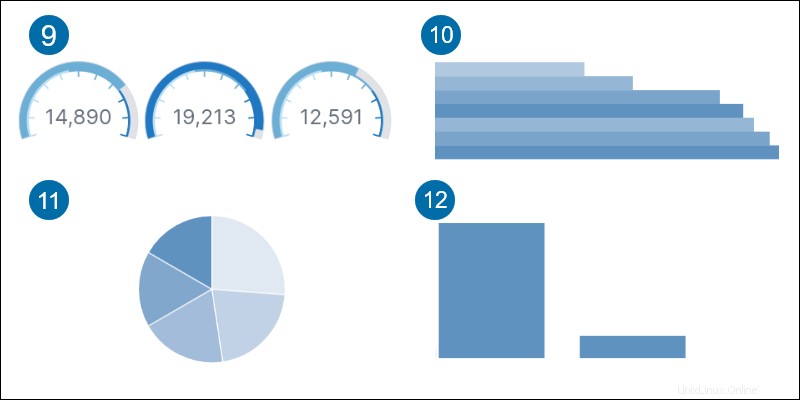
Kibana Aggregations
Kibana集計ツールは、さまざまな視覚化を提供します。
1.エリア 軸と線の間のデータを強調表示します。
2.目標 指定された目標までのメトリックの進捗状況を追跡します。
3.ライン データを一連のポイントとして表示します。
4.タグクラウド 単語の頻度を示します。
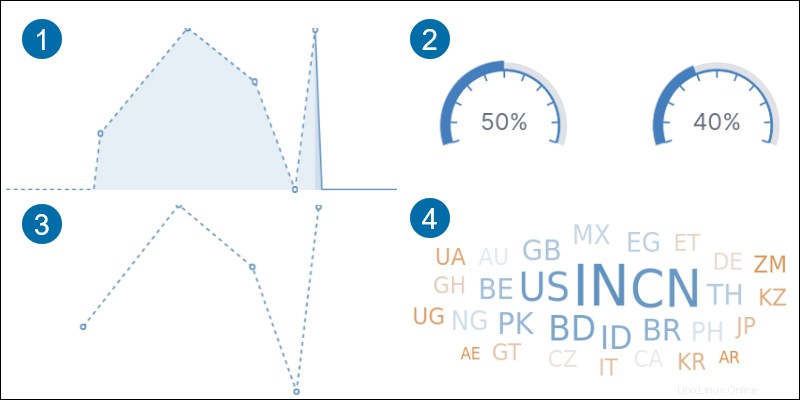
5.データテーブル 行と列にデータを表示します。
6.ヒートマップ 影付きの領域を持つセルマトリックスにデータを表示します。
7.メトリック 計算結果を単一の数値として表示します。
8.タイムリオン 時系列データをグラフ化します。
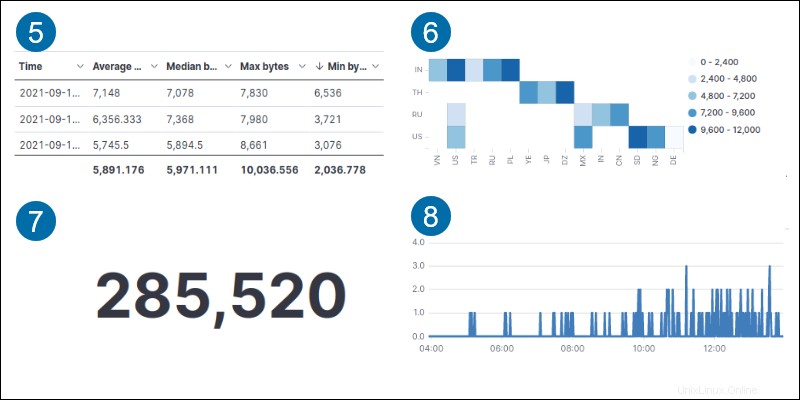
9.ゲージ メトリックステータスを表示します。
10.横棒 軸上の水平バーにデータを表示します。
11.パイ 全体と比較して部分的にデータを比較します。
12.垂直バー 軸上の垂直バーにデータを表示します。
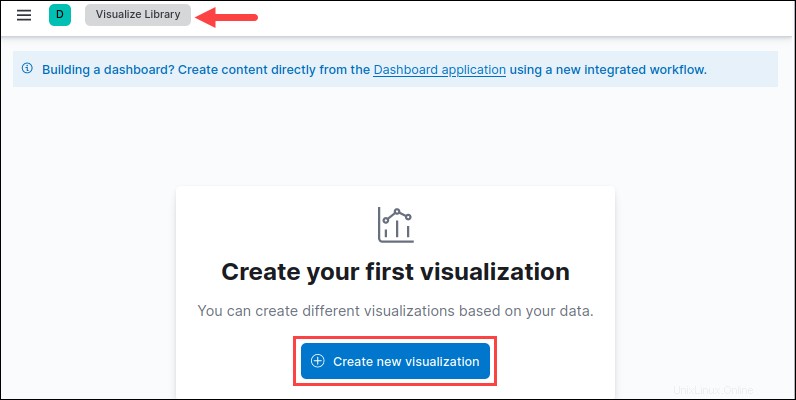
Kibanaでビジュアライゼーションを作成する
Kibanaでビジュアライゼーションを作成するには:
1. Visualize Libraryを検索します 上部の検索バー(ショートカット CTRL + / )そして Enterを押します 。
2.新しいビジュアライゼーションの作成をクリックします ボタン。
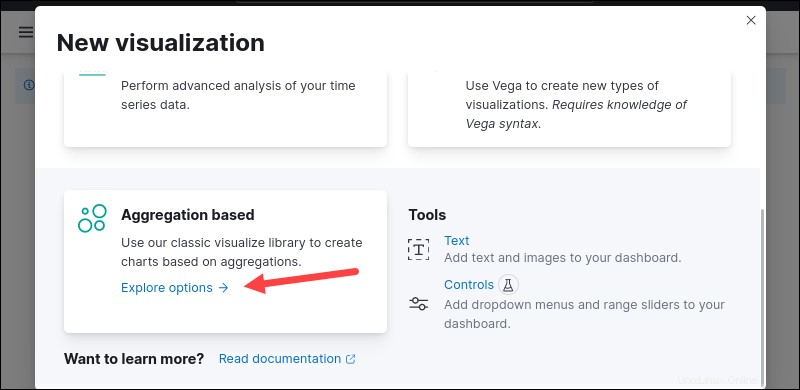
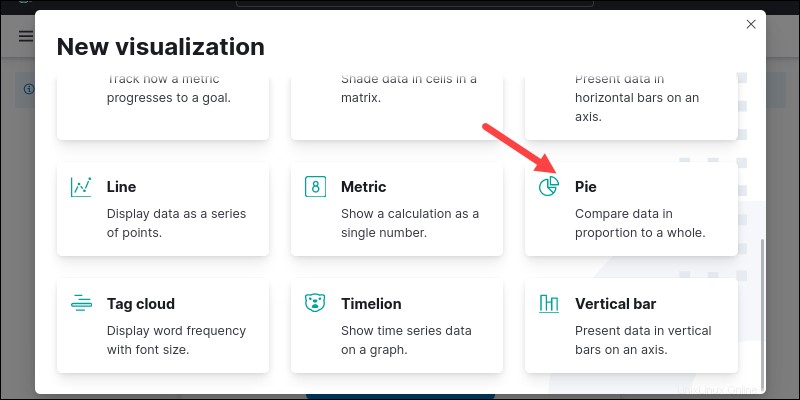
3.リストから視覚化タイプを選択します。たとえば、下にスクロールして、集計ベースを選択します。 。
4.オプションリストから、パイを見つけて選択します 円グラフを作成します。
5.名前でインデックスパターンを検索し、それを選択して続行します。作成ダッシュボードが表示されます。
6.メトリクスを選択します データのために。 カウント メトリックはデフォルトで選択されています。
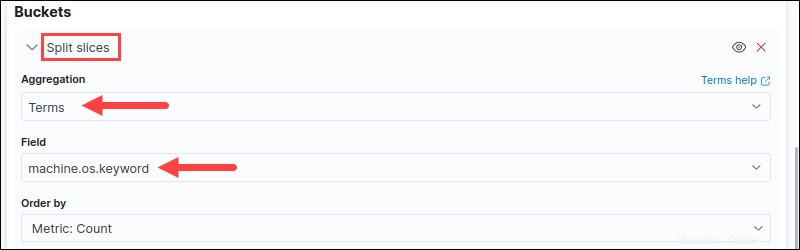
7.バケットを追加します パラメータを選択し、スライスの分割を選択します 。
8.必須フィールドのオプションを選択します。たとえば、集計を設定します 利用規約へ およびフィールド machine.os.keywordへ 。
9.更新を押します ボタン(ショートカット CTRL +入力 )円グラフを表示します。
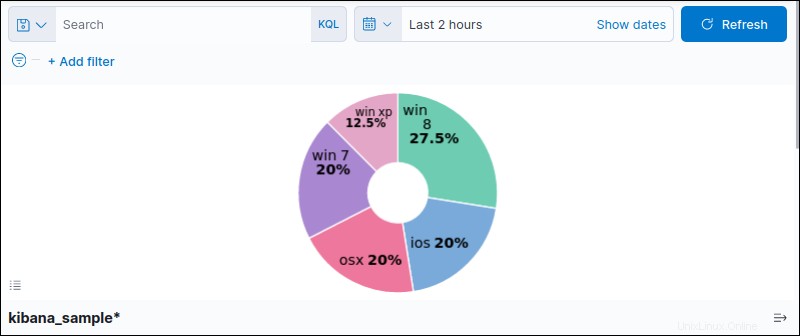
オプション、フィルタリング、タイムラインを試して、視覚化を調整します。
10.終了したら、[保存]をクリックします 右上隅のボタン。グラフに名前を付けて、新規を選択します 新しいダッシュボードを作成します。
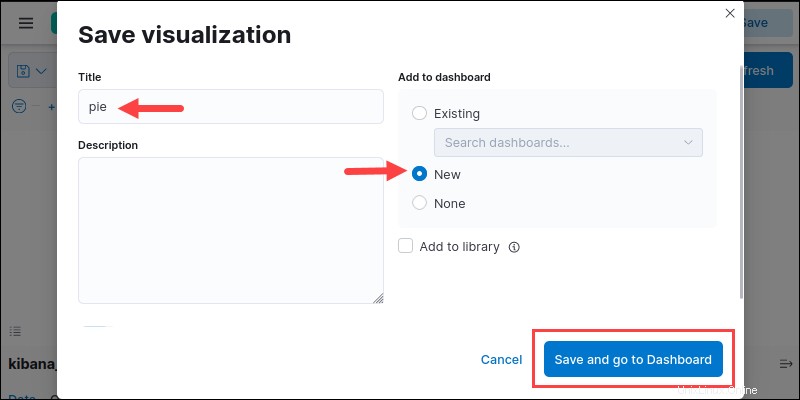
[保存してダッシュボードに移動]をクリックします ダッシュボードで視覚化を確認します。ダッシュボードを保存し、その名前を入力します。
Kibanaの視覚化を共有する
ダッシュボードをリアルタイムまたは現在の結果のスナップショットで共有します。 Kibanaダッシュボードを共有するには:
1.共有するダッシュボードを開きます。
2.共有をクリックします メニューバーにあります。
3.埋め込みコードを選択します iFrameオブジェクトを生成するオプション。または、パーマリンクを選択します リンクを介して共有するオプション。