はじめに
Redisは、非常に高速な非リレーショナルデータベースソリューションです。そのシンプルなKey-Valueデータモデルにより、Redisは、優れた読み取り/書き込み速度と可用性を維持しながら、大規模なデータセットを処理できます。
Redisを使用すると、リスト、ハッシュ、セット、並べ替えられたセットなどのさまざまなデータタイプを使用して、データを保存および管理できます。
このチュートリアルでは、Redisデータ型の方法を学びます 作業とマスター基本コマンド データ型ごとに。
Redisデータ型
Key-Valueデータベースは、各データオブジェクトに一意のキーを適用することでデータを構造化します。キーを使用して、その特定のキーに割り当てられた値を管理および取得します。サイズが最大512MBの任意のバイナリシーケンスをRedisキーとして使用し、単純な文字列またはその他の抽象データ構造に関連付けることができます。
Redisキーは、7つの異なるデータ型のいずれかを使用して値にマッピングされます:
- 文字列
- リスト
- ハッシュ
- セット
- ソートされたセット
- HyperLogLogs
- ビットマップ(BitStrings)
各Redisデータ型には、ルーチンアクセスパターン、トランザクションサポート、および一括操作のための独自のコマンドセットがあります。Redisがインストールされていない場合は、詳細ガイドを使用して、UbuntuにRedisをインストールするか、DockerにRedisをデプロイしてください。
文字列
文字列は、キーに付加できる最小値を表します。文字列値の最大許容サイズは512MBで、任意の文字シーケンスを含みます。 Redisでは、キーと値のペアのキー部分も文字列です。
このタイプのデータ構造を使用するデータベースは、文字列間キー値ストアと呼ばれることがよくあります。
すべてのデータが1つのオブジェクトに含まれているため、Redisでの文字列操作は非常に高速です。 SETなどの基本的なRedisコマンド 、 GET 、および DEL 文字列値に対して重要な操作を実行できるようにします。
SET key value–指定されたキーの値を設定します。GET key–指定されたキーの値を取得します。-
DEL key–指定されたキーの値を削除します。
次の例は、 redis-cli内でこれらの簡単なコマンドを使用する方法を示しています インタラクティブシェル。 SET GETが実行されている間、コマンドはキーに値を追加します コマンドは値をフェッチして表示します。キーに値がマップされていない場合、 GET コマンドの出力は(nil) 。

値が存在する場合、 DELの出力 コマンドは、削除されるアイテムの数を表示します。新しいキーと値を追加しても、データベースのパフォーマンスや処理速度には影響しません。
リスト
Redisを使用すると、順序付けられた文字列のシーケンスをキーに関連付けることができます。このリンクされた文字列のリスト 次のような一連の操作を実行できます:
-
LPUSH–値をリストの左端にプッシュします。 -
RPUSH–値をリストの最後にプッシュします。 -
LRANGE–さまざまなアイテムを取得します。 -
LPOP/RPOP–両端からアイテムを表示および削除するために使用されます。 -
LINDEX–リスト内の特定の位置から値を取得します。
LPUSH/RPUSHを使用してリストに値を追加する場合 コマンドの場合、出力には現在のアイテム数が表示されます。次に、 LRANGEを使用してリスト全体を取得できます。 0を使用したコマンド 開始点として-1 最後のインデックスアイテムを示します。
LINDEXを使用して、リンクリストから特定の値を取得します LPOP/RPOPを使用してアイテムをコマンドまたは削除します コマンド。
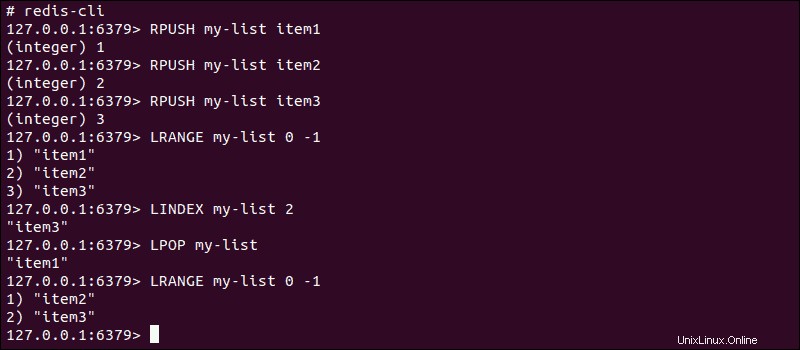
リンクリストへの値の追加は、サイズに関係なく書き込み速度に影響を与えない効率的な操作です。ただし、リンクリストからのデータの読み取りは、キーと値のペアの値側の文字列の数に依存する可能性があります。
ハッシュ
Redisハッシュは、キーと値のペアの順序付けられていないマッピングを格納します。ハッシュキーは値に関連付けられています。値は、他のキーと値のペアを含むRedis文字列です。セット、リスト、その他のハッシュなど、その他の複雑なデータ構造を値として使用することはできません。
基本的なハッシュコマンドを使用すると、個々のフィールドまたは複数のフィールドに個別にアクセスして変更できます。
-
HSET–値をハッシュ内のキーにマップします。 -
HGET–ハッシュ内のキーに関連付けられた個々の値を取得します。 -
HGETALL–ハッシュコンテンツ全体を表示します。 -
HDEL–既存のキーと値のペアをハッシュから削除します。
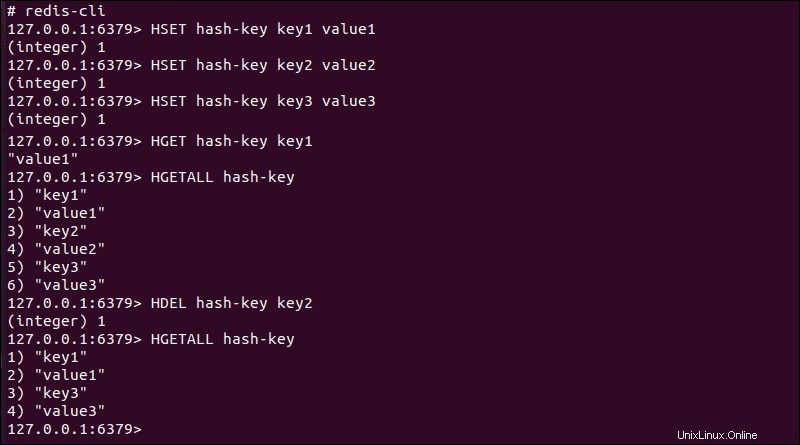
HSETを使用してアイテムがハッシュに追加されるたび コマンド、戻り値 (integer) n エントリがすでに存在するかどうかとインスタンスの数を通知します。これと同じ情報は、 HDELを使用するときに提供されます コマンド。
セット
Redisセットは、順序付けられていない一意の文字列のコレクションです。セットは注文されていないため、リストのようにインデックスの前または最後からアイテムを削除することはできません。ただし、文字列は一意であり、同じアイテムの複数のインスタンスがセット内に表示される可能性はありません。
次のコマンドを使用します セットの個々のアイテムを追加、削除、取得、および検査するには:
-
SADD–1つ以上のアイテムをセットに追加します。 -
SISMEMBER–アイテムがセットの一部であるかどうかを確認します。 -
SMEMBERS–セットからすべてのアイテムを取得します。 -
SREM–既存のアイテムをセットから削除します。
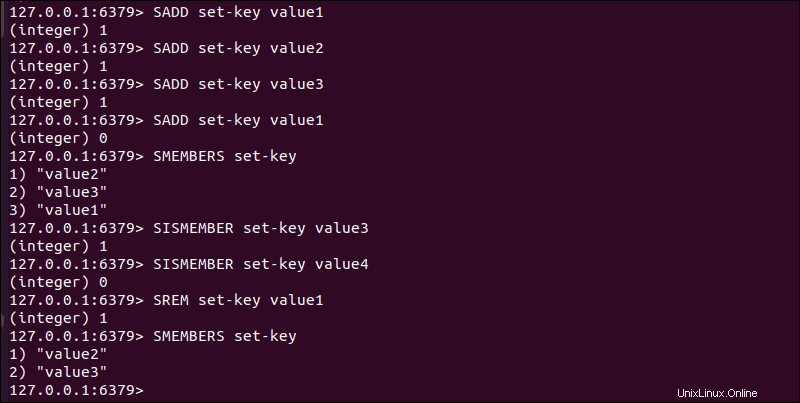
同じアイテムをセットに複数回追加すると、常に1つのコピーが生成されます。そのため、 SMEMBERSを使用する必要はありません。 またはSISMEMBER アイテムがすでにセットのメンバーであるかどうかを判別するコマンド。
SADDを使用します セット内に重複するエントリがないことを確認するコマンド。
ソートされたセット
並べ替えられたセットまたはZSET sはRedisで最も高度なデータ型の1つです。
ソートされたセットのキーと値のペアの値の部分は、メンバーと呼ばれる一意の文字列要素(キー)で構成されます 、アイテム(値)はスコアと呼ばれます 。並べ替えられたセットは、すべての要素を浮動小数点値(スコア)にマップします )そしてその値を使用して、特定の順序で要素を並べ替えます。
メンバー、並べ替えられた順序、およびスコア値によって並べ替えられたセットのアイテムにアクセスできます。基本的なコマンドを使用すると、個々の値をフェッチ、追加、削除したり、メンバーの値とスコア範囲に基づいてアイテムを取得したりできます。
-
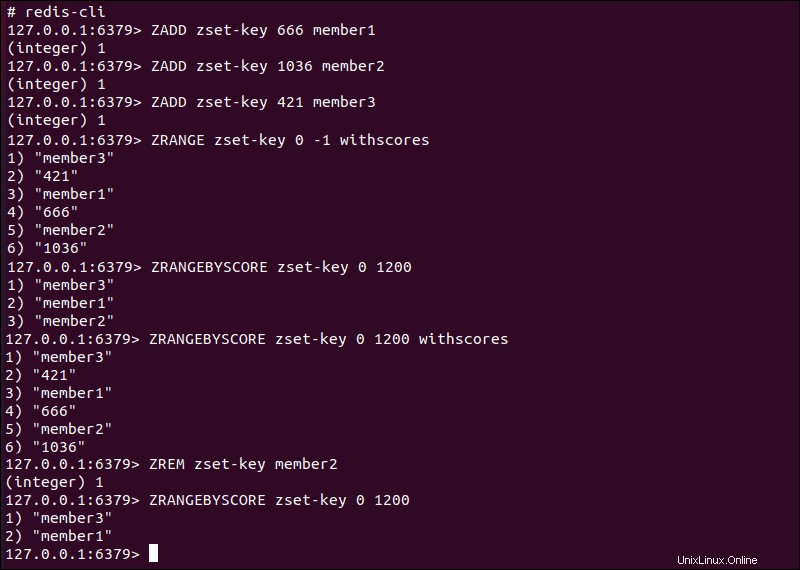
ZADD–スコアのあるメンバーをソートされたセットに追加します。 -
ZRANGE–ソートされた順序での位置に基づいてアイテムを取得します。withscoresオプションは実際のスコア値を生成します。 -
ZRANGEBYSCORE–定義されたスコア範囲に基づいてソートされたセットからアイテムをフェッチします。withscoresオプションは実際のスコア値を生成します。 -
ZREM– 並べ替えられたセットからアイテムを削除します。
メンバーのみ メンバーとスコアのペアの値は一意として扱われます。 2つの異なるスコアを関連付ける場合 同じメンバーに 値の場合、ソートされたセットには最新の追加のみが含まれます。 2人の異なるメンバーの場合 同じスコアを持っている Redisは値を英数字で並べ替えます。
HyperLogLogs
HyperLogLogsは、コレクション内の一意のアイテムの推定数を提供します。他のソリューションとは対照的に、HyperLogLogsのアイテムは個別にカウントされません。これは、同じ要素が2回カウントされないように、前のアイテムを追跡する必要があるためです。このような操作には、データの保存に使用されるメモリと同じ量のメモリが必要です。
HyperLogLog構造は、はるかに効率的な確率的アルゴリズムを使用します 各アイテムを数えるのではなく、セットのサイズを推定します。見積もりのエラー率は1%未満です。
HyperLogLogコマンドを使用すると、アイテムを追加したり、一意のアイテムの推定数を取得したり、複数のHyperLogLogの和集合を作成したりできます。
-
PFADD–HyperLogLogに1つまたは複数の要素を追加します。 -
PFCOUNT–単一のHyperLogLogから一意のアイテムの推定数を取得します。 -
PFMERGE–異なるHyperLogLogを単一のHyperLogLogにマージします。
結果の精度は、コレクションのサイズによって異なります。ただし、アイテムの正確な数が必要ない場合は、この確率的構造により、他の方法で必要となるメモリのごく一部しか使用できません。
ビットマップ
Redis文字列は、最大サイズが512メガバイトのバイナリシーケンスです。ビットマップを使用すると、適切なコマンドを使用してビットレベルで文字列を操作できます。
-
SETBIT–ビットは0または1の値に基づいて定義またはクリアされます。 -
GETBIT–キーで指定された文字列値のビット値を取得します。 -
BITOP–文字列間でビット演算を実行します。 -
BITPOS–文字列の1または0に設定されている最初のビットを見つけます。 BITCOUNT–文字列の1に設定されたビット数をカウントします。
文字列のビットを操作できることは、非常にスペースを節約する機会を提供します。また、データの基本的な要素に直接アクセスして作業する手段も提供します。