はじめに
データベースの正規化は、データテーブルを適切に整理するのに役立つリレーショナルデータベース設計の方法です。このプロセスは、データの損失や冗長性なしに、情報と関係を忠実に表現するシステムを作成することを目的としています。
この記事では、データベースの正規化と、実践的な例を通じてデータベースを正規化する方法について説明します。

データベースの正規化とは何ですか?
データベースの正規化 は、大きなテーブルを小さな論理ユニットに分解することにより、適切な列とキーを持つデータベーステーブルを作成するための手法です。このプロセスでは、データベースが存在する環境の要求も考慮されます。
正規化は反復プロセスです。 通常、データベースの正規化は一連のテストを通じて行われます。後続の各ステップは、テーブルをより管理しやすい情報に分解し、データベース全体を論理的で操作しやすくします。
データベースの正規化が重要な理由
正規化は、データベース設計者が属性をテーブルに最適に分散するのに役立ちます。この手法により、次のことが排除されます。
- 複数の属性 値。
- 2倍または繰り返し 属性。
- わかりにくい 属性。
- 冗長の属性 情報。
- その他の機能から作成された属性 。
データベース全体の正規化は必要ありませんが、十分に機能する情報環境を提供します。この方法は体系的に以下を保証します:
- データベース構造 一般化されたクエリに適しています。
- データの冗長性を最小限に抑える 、データベースサーバーのメモリ効率を向上させます。
- データの整合性を最大化 挿入、更新、削除の異常を減らします。
データベースの正規化は、データベース全体の一貫性を変革し、効率的な環境を提供します。
データベースの冗長性と異常
冗長性のあるテーブル内のエンティティを変更する場合 、繰り返されるすべての情報のインスタンス、および変更されたデータに関連するその他の情報を変更する必要があります。そうしないと、データベースに一貫性がなくなり、異常 変更を加えるときに発生します。
たとえば、次の正規化されていないテーブルでは、次のようになります。

テーブルにはデータ冗長性が含まれています 、これにより3つの異常が発生します データを変更する場合:
1.異常を挿入 。金融部門に新しい従業員を挿入しようとするときは、マネージャーの名前も知っている必要があります。そうしないと、テーブルにデータを挿入できません。
2.異常を更新します。 従業員がセクターを切り替えると、マネージャーの名前が正しくなくなります。たとえば、ジェイコブが財務に変更した場合、アダムは彼のマネージャーのままです。
3.異常を削除 。 Joshuaが会社を辞めることにした場合、行を削除すると、金融セクターが存在するという情報も削除されます。
これらの異常の解決策は、データベースの正規化にあります。 概念と手順。
データベースの正規化の概念
データベースの正規化で使用される基本的な概念は次のとおりです。
- キー 。データベースレコードを一意に識別する列属性。
- 機能依存性 。リレーション内の2つの属性間の制約。
- 正規形 。データベースの特定の品質を達成するための手順。
データベースの正規形
データベースの正規化は、正規形と呼ばれる一連のルールによって実現されます。 。中心的な概念は、データベース設計者がリレーショナルデータベースの望ましい品質を達成できるようにすることです。
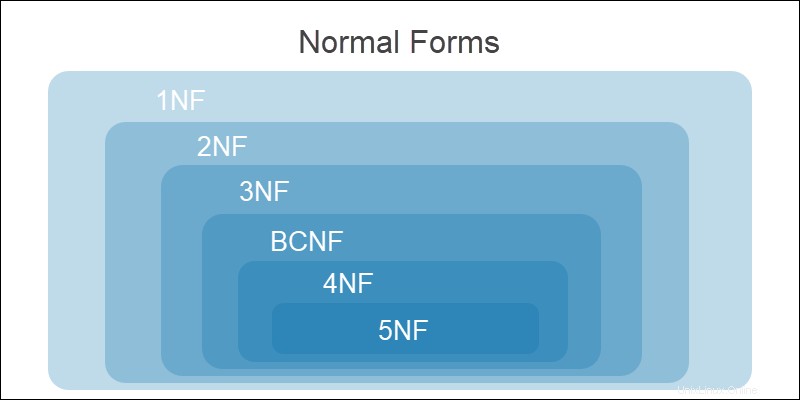
正規化のすべてのレベルは累積的です。以前の正規形の要件を満たす必要があります 次のフォームに進む前に。
正規化の段階は次のとおりです。
| ステージ | 対処された冗長性の異常 |
|---|---|
| 非正規化フォーム(UNF) | 正規化前の状態。冗長で複雑な値が存在します。 |
| 第一正規形(1NF) | 繰り返して複雑な値が分割され、すべてのインスタンスがアトミックになります。 |
| 第2正規形(2NF) | 部分的な依存関係は新しいテーブルに分解されます。すべての行は機能的に主キーに依存しています。 |
| 第3正規形(3NF) | 推移的な依存関係は新しいテーブルに分解されます。キー以外の属性は主キーによって異なります。 |
| Boyce-Codd Normal Form(BCNF) | すべての候補キーの推移的および部分的な機能依存性は、新しいテーブルに分解されます。 |
| 第4正規形(4NF) | 多値従属性の削除。 |
| 第5正規形(5NF) | JOIN依存関係の削除。 |
データベースは、第3正規形を満たすときに正規化されます。 。正規化のさらなるステップは、データベース設計を複雑にし、システムの機能を損なう可能性があります。
キーとは何ですか?
データベースキーは、テーブル内のエンティティを一意に記述する属性または機能のグループです。正規化で使用されるキーのタイプは次のとおりです。
- スーパーキー 。テーブル内の各レコードを一意に定義する一連の機能。
- 候補キー 。フィールド数が最小のスーパーキーのセットから選択されたキー。
- 主キー 。候補キーのセットから最も適切な選択肢が、テーブルの主キーとして機能します。
- 外部キー 。別のテーブルの主キー。
- 複合キー 。 2つ以上の属性が一緒になって一意のキーを形成しますが、個別のキーではありません。
テーブルが複数のより単純なテーブルに分解されると、キーはデータベースエンティティの参照ポイントを定義します。
たとえば、次のデータベース構造では:

スーパーキーの例 表には次のようなものがあります:
- employeeID
- (employeeID、name)
- メール
すべてのスーパーキーは、各行の一意の識別子として機能できます。一方、2人が同じ名前または年齢である可能性があるため、従業員の名前または年齢は一意の識別子ではありません。
候補キー フィールドの数が最小であるスーパーキーのセットから来ます。選択は2つのオプションになります:
- employeeID
- メール
どちらのオプションにも最小限の数のフィールドが含まれているため、最適な候補キーになります。 主キーの最も論理的な選択 employeeIDです 従業員の電子メールが変更される可能性があるためです。表の主キーは、外部キーとして簡単に参照できます。 別のテーブルで。
機能的なデータベースの依存関係
機能データベースの依存関係は、データベーステーブル内の2つの属性間の関係を表します。機能従属性のいくつかのタイプは次のとおりです。
- 重要な機能依存性 。属性と、元の要素がグループ内にある機能のグループとの間の依存関係。
- 非自明な機能依存性 。属性と、機能がグループに含まれていないグループとの間の依存関係。
- 推移的な依存関係。 2番目が最初に依存し、3番目が2番目に依存する、3つの属性間の機能依存性。推移性のため、3番目の属性は最初の属性に依存しています。
- 多値従属性。 複数の値が1つの属性に依存する依存関係。
関数従属性は、データベースの正規化に不可欠なステップです。長期的には、依存関係はデータベースの全体的な品質を決定するのに役立ちます。
データベースの正規化の例-データベースを正規化する方法
データベースの正規化の一般的な手順は、すべてのデータベースで機能します。テーブルを分割する具体的な手順と、3NFを超えるかどうかは、ユースケースによって異なります。
非正規化データベースの例
正規化されていないテーブルには、1つのフィールド内に複数の値があり、最悪の場合は冗長な情報があります。
例:
| managerID | managerName | エリア | employeeID | employeeName | ectorID | ectorName |
|---|---|---|---|---|---|---|
| 1 | アダムA。 | 東 | 1 2 | デビッドD。 ユージーンE。 | 4 3 | 財務 IT |
| 2 | ベティB。 | 西 | 3 4 5 | ジョージG。 ヘンリーH。 イングリッドI。 | 2 1 4 | セキュリティ 管理 財務 |
| 3 | カールC。 | 北 | 6 7 | ジェームズJ。 Katy K. | 1 4 | 管理 財務 |
データの挿入、更新、および削除は複雑な作業です。既存のテーブルに変更を加えると、情報が失われるリスクが高くなります。
ステップ1:第一正規形1NF
データベーステーブルを1NFに作り直すには、単一フィールド内の値がアトミックである必要があります。テーブル内のすべての複雑なエンティティは、新しい行または列に分割されます。
managerID列の情報 、 managerName 、およびエリア 情報が失われないように、従業員ごとに繰り返します。
| managerID | managerName | エリア | employeeID | employeeName | ectorID | ectorName |
|---|---|---|---|---|---|---|
| 1 | アダムA。 | 東 | 1 | デビッドD。 | 4 | 財務 |
| 1 | アダムA。 | 東 | 2 | Eugene E. | 3 | IT |
| 2 | ベティB。 | 西 | 3 | ジョージG. | 2 | セキュリティ |
| 2 | ベティB。 | 西 | 4 | ヘンリーH。 | 1 | 管理 |
| 2 | ベティB。 | 西 | 5 | イングリッドI。 | 4 | 財務 |
| 3 | カールC。 | 北 | 6 | James J. | 1 | 管理 |
| 3 | カールC。 | 北 | 7 | Katy K. | 4 | 財務 |
再加工されたテーブルは、最初の正規形を満たします。
ステップ2:第2正規形2NF
データベース正規化の2番目の正規形は、データベーステーブルの各行が主キーに依存する必要があることを示しています。
テーブルは、通常の形式を満たすために2つのテーブルに分割されます。
- マネージャー (managerID、managerName、area)
| managerID | managerName | エリア |
|---|---|---|
| 1 | アダムA。 | 東 |
| 2 | ベティB。 | 西 |
| 3 | カールC。 | 北 |
- 従業員 (employeeID、employeeName、managerID、sectorID、sectorName)
| employeeID | employeeName | managerID | ectorID | ectorName |
|---|---|---|---|---|
| 1 | デビッドD。 | 1 | 4 | 財務 |
| 2 | Eugene E. | 1 | 3 | IT |
| 3 | ジョージG。 | 2 | 2 | セキュリティ |
| 4 | ヘンリーH。 | 2 | 1 | 管理 |
| 5 | イングリッドI。 | 2 | 4 | 財務 |
| 6 | James J. | 3 | 1 | 管理 |
| 7 | Katy K. | 3 | 4 | 財務 |
2番目の正規形の結果のデータベースは、現在、部分的な依存関係のない2つのテーブルです。
ステップ3:第3正規形3NF
3番目の正規形は、推移的な関数従属性を分解します。現在、テーブル従業員 2つの新しいテーブルに分解される推移的な依存関係があります:
- 従業員 (employeeID、employeeName、managerID、sectorID)
| employeeID | employeeName | managerID | ectorID |
|---|---|---|---|
| 1 | デビッドD。 | 1 | 4 |
| 2 | Eugene E. | 1 | 3 |
| 3 | ジョージG. | 2 | 2 |
| 4 | ヘンリーH。 | 2 | 1 |
| 5 | イングリッドI。 | 2 | 4 |
| 6 | James J. | 3 | 1 |
| 7 | Katy K. | 3 | 4 |
- セクター (sectorID、sectorName)
| ectorID | ectorName |
|---|---|
| 1 | 管理 |
| 2 | セキュリティ |
| 3 | IT |
| 4 | 財務 |
データベースは現在、合計3つの関係を持つ第3正規形です。最終的な構造は次のとおりです。

この時点で、データベースは正規化されています 。それ以降の正規化手順は、データのユースケースによって異なります。