はじめに
分散データベースは、水平スケーリングに使用されます 、およびデータベースアプリケーションに変更を加えたり、単一のマシンを垂直方向にスケーリングしたりすることなく、ワークロード要件を満たすように設計されています。
分散データベースはさまざまな問題を解決します 、可用性、フォールトトレランス、スループット、遅延、スケーラビリティ、および単一のマシンと単一のデータベースを使用することから発生する可能性のある他の多くの問題など。
この記事では、分散データベースとは何か、およびその長所と短所について学習します。

分散データベース定義
分散データベースは、ネットワークで接続された複数のサイトに分散した複数の相互接続されたデータベースを表します。データベースはすべて接続されているため、ユーザーには単一のデータベースとして表示されます。
分散データベースは複数のノードを利用します。それらは水平方向にスケーリングし、分散システムを開発します。システム内のノードが増えると、より多くのコンピューティング能力が提供され、可用性が向上し、単一障害点の問題が解決されます。
分散データベースのさまざまな部分がいくつかの物理的な場所に保存されています 、および処理要件は、複数のデータベースノード上のプロセッサ間で分散されます。
一元化された分散データベース管理システム( DDBMS )分散データを1つの物理的な場所に保存されているかのように管理します。 DDBMSは、データベース間のすべてのデータ操作を同期し、1つのデータベースの更新が他のサイトのデータベースに自動的に反映されるようにします。
分散データベース機能
分散データベースの一般的な機能は次のとおりです。
- 場所の独立性 -データは複数のサイトに物理的に保存され、独立したDDBMSによって管理されます。
- 分散クエリ処理 -分散データベースは、複数のサイトでデータを管理する分散環境でクエリに応答します。高レベルのクエリは、管理を簡素化するためのクエリ実行プランに変換されます。
- 分散トランザクション管理 -コミットプロトコル、分散同時実行制御技術、および多くのトランザクションや障害が発生した場合の分散リカバリ方法を通じて、一貫性のある分散データベースを提供します。
- シームレスな統合 -コレクション内のデータベースは通常、単一の論理データベースを表し、相互接続されています。
- ネットワークリンク -コレクション内のすべてのデータベースはネットワークによってリンクされており、相互に通信します。
- トランザクション処理 -分散データベースには、1つ以上のデータベース操作のコレクションを含むプログラムであるトランザクション処理が組み込まれています。トランザクション処理は、完全に実行されるか、まったく実行されないアトミックプロセスです。
分散データベースタイプ
分散データベースには次の2つのタイプがあります。
- 同種
- 異種
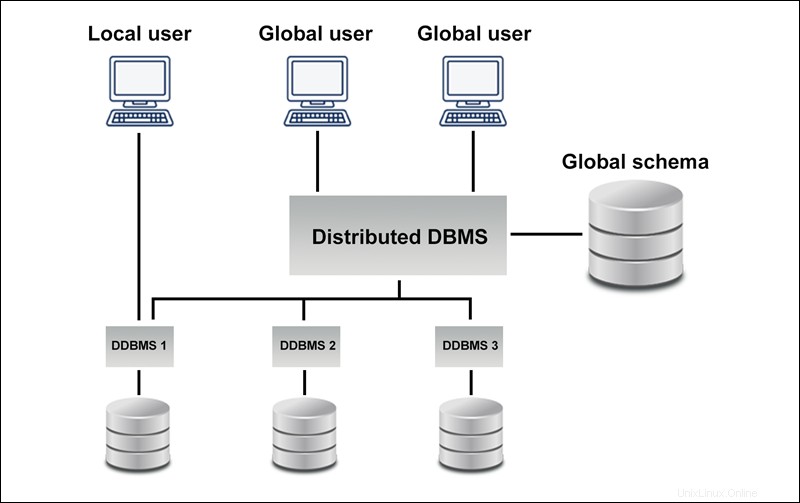
同種
同種の分散データベースは、同一のデータベースのネットワークです。 複数のサイトに保存されています。サイトのオペレーティングシステム、DDBMS、データ構造は同じであるため、管理が容易です。
同種のデータベースにより、ユーザーは各データベースのデータにシームレスにアクセスできます。
次の図は、同種のデータベースの例を示しています。
異種
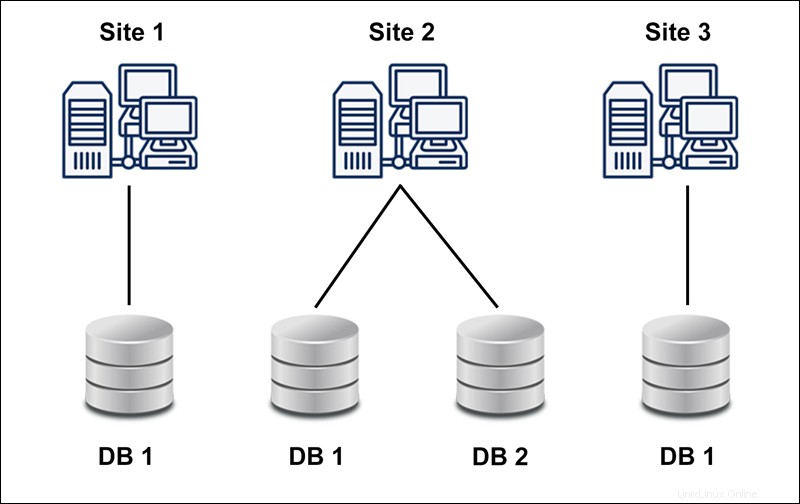
異種分散データベースは異なるを使用します スキーマ、オペレーティングシステム、DDBMS、およびさまざまなデータモデル。
異種分散データベースの場合、特定のサイトが他のサイトを完全に認識せず、ユーザー要求の処理における協力が制限される可能性があります。制限は、サイト間の通信を確立するために翻訳が必要な理由です。
次の図は、異種データベースの例を示しています。
分散データベースストレージ
分散データベースストレージは、次の2つの方法で管理されます。
- レプリケーション
- 断片化
レプリケーション
データベースレプリケーションでは、システムはさまざまなサイトのデータのコピーを保存します 。データベース全体が複数のサイトで利用できる場合、それは完全に冗長なデータベースです。
データベースレプリケーションの利点は、データの可用性が向上することです。 n個の異なるサイトであり、並列クエリ要求を処理できます。
ただし、データベースレプリケーションとは、正確なデータベースコピーを維持するために、データを定期的に更新し、他のサイトと同期する必要があることを意味します。あるサイトで行われた変更は、他のサイトに記録する必要があります。そうしないと、不整合が発生します。
利用可能なすべてのサイトで多数の同時クエリをチェックする必要があるため、絶え間ない更新により、サーバーのオーバーヘッドが大きくなり、同時実行制御が複雑になります。
フラグメンテーション
分散データベースストレージの断片化に関しては、関係は断片化されています。つまり、小さな部分に分割されています 。各フラグメントは、必要に応じて異なるサイトに保存されます。
断片化の前提条件は、データを失うことなく、後で断片を元の関係に再構築できることを確認することです。
断片化の利点は、データコピーがないことです。 、データの不整合を防ぎます。
断片化には2つのタイプがあります:
- 水平方向の断片化 -リレーションスキーマは行のグループにフラグメント化され、各グループ(タプル)は1つのフラグメントに割り当てられます。
- 垂直方向の断片化 -リレーションスキーマはより小さなスキーマにフラグメント化され、各フラグメントには、ロスレス結合を保証するための共通の候補キーが含まれています。
分散データベースの長所と短所
分散データベースの主な長所と短所は次のとおりです。
| 利点 | デメリット |
|---|---|
| モジュラー開発 | コストのかかるソフトウェア |
| 信頼性 | 大きなオーバーヘッド |
| 通信コストの削減 | データの整合性 |
| より良い応答 | 不適切なデータ配信 |
長所と短所については、次のセクションで詳しく説明します。
利点
- モジュラー開発 。分散データベースのモジュラー開発は、既存のセットアップに新しいサーバーとデータを追加し、それらを中断することなく分散システムに接続することで、システムを新しい場所またはユニットに拡張できることを意味します。このタイプの拡張では、分散データベースの機能が中断されることはありません。
- 信頼性 。分散データベースは、集中データベースとは対照的に、より高い信頼性を提供します。一元化されたデータベースでデータベースに障害が発生した場合、システムは完全に停止します。分散データベースでは、障害が発生した場合でもシステムは機能し、問題が解決するまでパフォーマンスが低下するだけです。
- 通信コストの削減 。データをローカルに保存すると、分散データベースでのデータ操作の通信コストが削減されます。一元化されたデータベースでは、ローカルデータストレージは使用できません。
- より良い応答 。分散データベースシステムでの効率的なデータ分散により、ユーザーの要求がローカルで満たされている場合に、より高速な応答が提供されます。一元化されたデータベースでは、ユーザー要求はすべての要求を処理する中央マシンを通過します。その結果、特にクエリが多い場合に、応答時間が長くなります。
デメリット
- コストのかかるソフトウェア 。複数のサイト間でデータの透明性と調整を確保するには、多くの場合、分散データベースシステムで高価なソフトウェアを使用する必要があります。
- 大きなオーバーヘッド 。複数のサイトでの多くの操作では、データベースレプリケーションを使用する場合、多数の計算と一定の同期が必要であり、多くの処理オーバーヘッドが発生します。
- データの整合性 。データベースレプリケーションを使用するときに考えられる問題は、データの整合性です。これは、複数のサイトでデータを更新することによって損なわれます。
- 不適切なデータ配布 。ユーザーの要求に対する応答性は、適切なデータ分散に大きく依存します。つまり、データが複数のサイトに正しく分散されていない場合、応答性が低下する可能性があります。