Hadoopは、マシンのクラスター上で大規模なデータセットを保存および処理するために使用される、無料のオープンソースのJavaベースのソフトウェアフレームワークです。 HDFSを使用してデータを保存し、MapReduceを使用してこれらのデータを処理します。これは、主にデータマイニングと機械学習に使用されるビッグデータツールのエコシステムです。
Apache Hadoop 3.3には、以前のリリースに比べて顕著な改善と多くのバグ修正が含まれています。 Hadoop Common、HDFS、YARN、MapReduceなどの4つの主要コンポーネントがあります。
このチュートリアルでは、Ubuntu 20.04LTSLinuxシステムにApacheHadoopをインストールして構成する方法について説明します。
ステップ1–Javaのインストール
HadoopはJavaで記述されており、Javaバージョン8のみをサポートします。Hadoopバージョン3.3以降は、Java8だけでなくJava11ランタイムもサポートします。
OpenJDK11はデフォルトのaptリポジトリからインストールできます:
sudo apt updatesudo apt install openjdk-11-jdk
インストールしたら、次のコマンドを使用して、インストールされているJavaのバージョンを確認します。
java -version
次の出力が得られるはずです:
openjdk version "11.0.11" 2021-04-20 OpenJDK Runtime Environment (build 11.0.11+9-Ubuntu-0ubuntu2.20.04) OpenJDK 64-Bit Server VM (build 11.0.11+9-Ubuntu-0ubuntu2.20.04, mixed mode, sharing)
ステップ2–Hadoopユーザーを作成する
セキュリティ上の理由から、Hadoopを実行するための別のユーザーを作成することをお勧めします。
次のコマンドを実行して、hadoopという名前の新しいユーザーを作成します。
sudo adduser hadoop
以下に示すように、新しいパスワードを入力して確認します。
Adding user `hadoop' ...
Adding new group `hadoop' (1002) ...
Adding new user `hadoop' (1002) with group `hadoop' ...
Creating home directory `/home/hadoop' ...
Copying files from `/etc/skel' ...
New password:
Retype new password:
passwd: password updated successfully
Changing the user information for hadoop
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] y
ステップ3–SSHキーベースの認証を構成する
次に、ローカルシステムのパスワードなしのSSH認証を構成する必要があります。
まず、次のコマンドを使用して、ユーザーをhadoopに変更します。
su - hadoop
次に、次のコマンドを実行して、公開鍵と秘密鍵のペアを生成します。
ssh-keygen -t rsa
ファイル名の入力を求められます。 Enterキーを押すだけで、プロセスが完了します:
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:QSa2syeISwP0hD+UXxxi0j9MSOrjKDGIbkfbM3ejyIk [email protected] The key's randomart image is: +---[RSA 3072]----+ | ..o++=.+ | |..oo++.O | |. oo. B . | |o..+ o * . | |= ++o o S | |.++o+ o | |.+.+ + . o | |o . o * o . | | E + . | +----[SHA256]-----+
次に、生成された公開鍵をid_rsa.pubからauthorized_keysに追加し、適切なアクセス許可を設定します。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 640 ~/.ssh/authorized_keys
次に、次のコマンドを使用してパスワードなしのSSH認証を確認します。
ssh localhost
既知のホストにRSAキーを追加して、ホストを認証するように求められます。 yesと入力し、Enterキーを押してローカルホストを認証します:
The authenticity of host 'localhost (127.0.0.1)' can't be established. ECDSA key fingerprint is SHA256:JFqDVbM3zTPhUPgD5oMJ4ClviH6tzIRZ2GD3BdNqGMQ. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
ステップ4–Hadoopのインストール
まず、次のコマンドを使用して、ユーザーをhadoopに変更します。
su - hadoop
次に、wgetコマンドを使用してHadoopの最新バージョンをダウンロードします。
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
ダウンロードしたら、ダウンロードしたファイルを抽出します:
tar -xvzf hadoop-3.3.0.tar.gz
次に、抽出したディレクトリの名前をhadoopに変更します:
mv hadoop-3.3.0 hadoop
次に、システムでHadoopおよびJava環境変数を構成する必要があります。
〜/ .bashrcを開きます お気に入りのテキストエディタのファイル:
nano ~/.bashrc
以下の行をファイルに追加します。 dirname $(dirname $(readlink -f $(which java))) command on terminal.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Save and close the file. Then, activate the environment variables with the following command:
source ~/.bashrc
次に、Hadoop環境変数ファイルを開きます。
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
再度、hadoop環境でJAVA_HOMEを設定します。
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
終了したら、ファイルを保存して閉じます。
ステップ5-Hadoopの構成
まず、Hadoopホームディレクトリ内にnamenodeディレクトリとdatanodeディレクトリを作成する必要があります。
次のコマンドを実行して、両方のディレクトリを作成します。
mkdir -p ~/hadoopdata/hdfs/namenodemkdir -p ~/hadoopdata/hdfs/datanode
次に、 core-site.xmlを編集します ファイルを作成し、システムのホスト名で更新します:
nano $HADOOP_HOME/etc/hadoop/core-site.xml
システムのホスト名に応じて、次の名前を変更します。
XHTML
| 123456 | |
ファイルを保存して閉じます。次に、 hdfs-site.xmlを編集します ファイル:
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
以下に示すように、NameNodeおよびDataNodeディレクトリパスを変更します。
XHTML
| 1234567891011121314151617 | |
ファイルを保存して閉じます。次に、 mapred-site.xmlを編集します ファイル:
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
次の変更を行います:
XHTML
| 123456 | |
ファイルを保存して閉じます。次に、 yarn-site.xmlを編集します ファイル:
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
次の変更を行います:
XHTML
| 123456 | |
終了したら、ファイルを保存して閉じます。
ステップ6-Hadoopクラスターを開始する
Hadoopクラスターを開始する前。 Namenodeをhadoopユーザーとしてフォーマットする必要があります。
次のコマンドを実行して、HadoopNamenodeをフォーマットします。
hdfs namenode -format
次の出力が得られるはずです:
2020-11-23 10:31:51,318 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-11-23 10:31:51,323 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-11-23 10:31:51,323 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop.tecadmin.net/127.0.1.1 ************************************************************/
Namenodeをフォーマットした後、次のコマンドを実行してHadoopクラスターを開始します。
start-dfs.sh
HDFSが正常に開始されると、次の出力が得られるはずです。
Starting namenodes on [hadoop.tecadmin.com] hadoop.tecadmin.com: Warning: Permanently added 'hadoop.tecadmin.com,fe80::200:2dff:fe3a:26ca%eth0' (ECDSA) to the list of known hosts. Starting datanodes Starting secondary namenodes [hadoop.tecadmin.com]
次に、以下に示すようにYARNサービスを開始します。
start-yarn.sh
次の出力が得られるはずです:
Starting resourcemanager Starting nodemanagers
jpsコマンドを使用してすべてのHadoopサービスのステータスを確認できるようになりました:
jps
次の出力に、実行中のすべてのサービスが表示されます。
18194 NameNode 18822 NodeManager 17911 SecondaryNameNode 17720 DataNode 18669 ResourceManager 19151 Jps
ステップ7-ファイアウォールを調整する
これでHadoopが起動し、ポート9870と8088でリッスンします。次に、これらのポートがファイアウォールを通過できるようにする必要があります。
次のコマンドを実行して、ファイアウォールを介したHadoop接続を許可します。
firewall-cmd --permanent --add-port=9870/tcpfirewall-cmd --permanent --add-port=8088/tcp
次に、firewalldサービスをリロードして、変更を適用します。
firewall-cmd --reload
ステップ8-HadoopNamenodeとResourceManagerにアクセスする
Namenodeにアクセスするには、Webブラウザーを開き、URL http:// your-server-ip:9870にアクセスします。次の画面が表示されます。
http://hadoop.tecadmin.net:9870
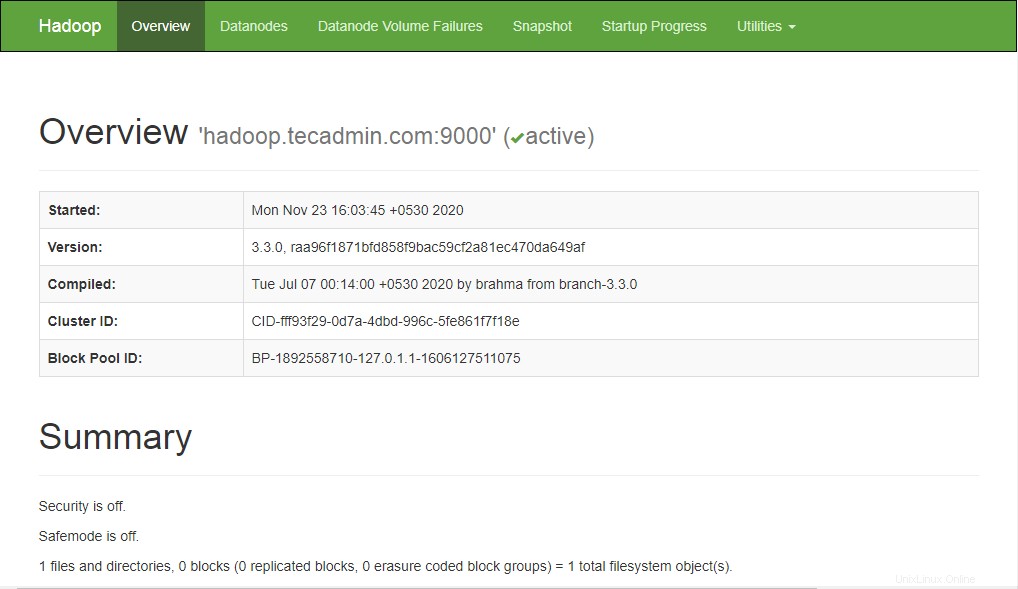
リソース管理にアクセスするには、Webブラウザーを開き、URL http:// your-server-ip:8088にアクセスします。次の画面が表示されます。
http://hadoop.tecadmin.net:8088
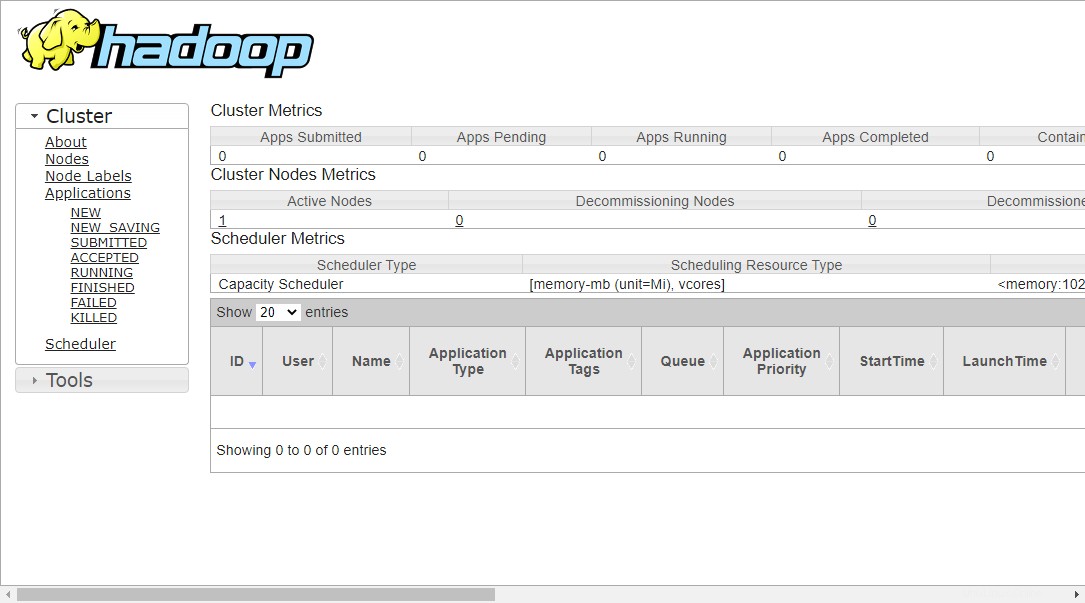
ステップ9-Hadoopクラスターを確認する
この時点で、Hadoopクラスターがインストールおよび構成されます。次に、HadoopをテストするためにHDFSファイルシステムにいくつかのディレクトリを作成します。
次のコマンドを使用して、HDFSファイルシステムにディレクトリを作成しましょう。
hdfs dfs -mkdir /test1hdfs dfs -mkdir /logs
次に、次のコマンドを実行して、上記のディレクトリを一覧表示します。
hdfs dfs -ls /
次の出力が得られるはずです:
Found 3 items drwxr-xr-x - hadoop supergroup 0 2020-11-23 10:56 /logs drwxr-xr-x - hadoop supergroup 0 2020-11-23 10:51 /test1
また、いくつかのファイルをhadoopファイルシステムに配置します。たとえば、ホストマシンからhadoopファイルシステムにログファイルを配置します。
hdfs dfs -put /var/log/* /logs/
上記のファイルとディレクトリは、HadoopNamenodeWebインターフェースで確認することもできます。
Namenode Webインターフェイスに移動し、[ユーティリティ]=>[ファイルシステムの参照]をクリックします。前に作成したディレクトリが次の画面に表示されます。
http://hadoop.tecadmin.net:9870/explorer.html
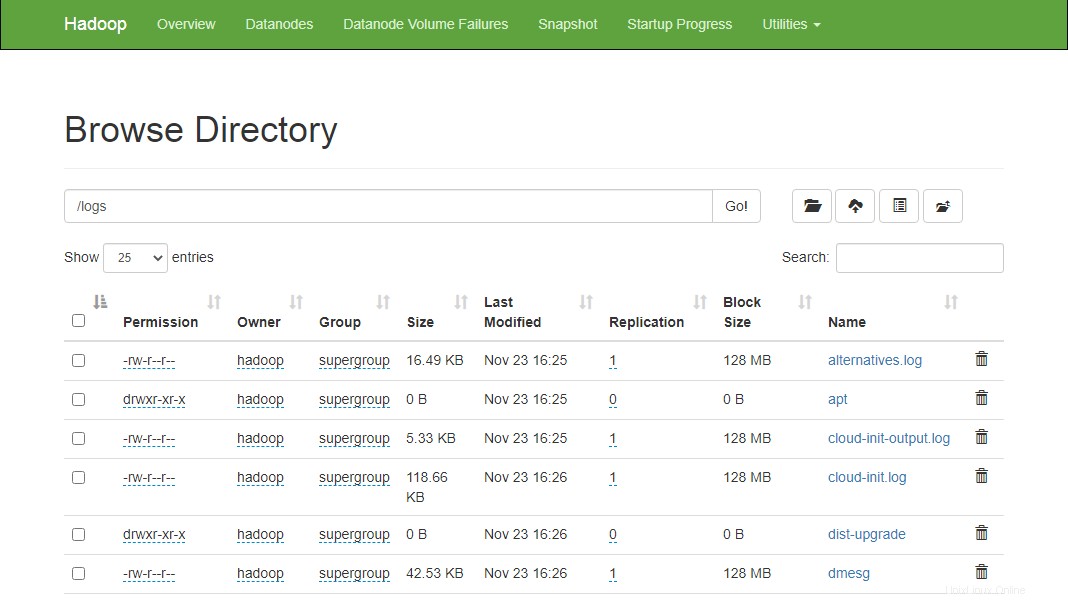
ステップ10-Hadoopクラスターを停止する
stop-dfs.sh を実行することで、HadoopNamenodeおよびYarnサービスをいつでも停止できます。 およびstop-yarn.sh Hadoopユーザーとしてのスクリプト。
Hadoop Namenodeサービスを停止するには、hadoopユーザーとして次のコマンドを実行します。
stop-dfs.sh
Hadoop Resource Managerサービスを停止するには、次のコマンドを実行します。
stop-yarn.sh
結論
このチュートリアルでは、Ubuntu20.04LinuxシステムにHadoopをインストールして構成するためのステップバイステップのチュートリアルについて説明しました。