Apache Sparkは、大規模な分析データと機械学習処理のためのオープンソースの計算フレームワークです。これは、scala、R、Python、Javaなどのさまざまな優先言語をサポートしています。 Sparkストリーミング用の高レベルのツール、グラフ処理用のGraphX、SQL、MLLibを提供します。
この記事では、ubuntuにApacheSparkをインストールして構成する方法を学びます。この記事の流れを示すために、Ubuntu20.04LTSバージョンシステムを使用しました。 Apache Sparkをインストールする前に、Scalaとscalaをシステムにインストールする必要があります。
Scalaのインストール
JavaとScalaをまだインストールしていない場合は、次のプロセスに従ってインストールできます。
Javaの場合、オープンJDK 8をインストールするか、お好みのバージョンをインストールできます。
$ sudo apt update
$ sudo apt install openjdk-8-jdk
Javaのインストールを確認する必要がある場合は、次のコマンドを実行できます。
$ java -version

Scalaに関して言えば、scalaはオブジェクト指向で関数型プログラミング言語であり、Scalaを1つの簡潔なものにまとめたものです。 ScalaはjavascriptランタイムとJVMの両方と互換性があり、高性能システムの構築に役立つ大規模なライブラリエコシステムに簡単にアクセスできます。次のaptコマンドを実行してscalaをインストールします。
$ sudo apt update
$ sudo apt install scala
次に、バージョンを確認してインストールを確認します。
$ scala -version

ApacheSparkのインストール
apache-sparkをインストールするための公式のaptリポジトリはありませんが、公式サイトからバイナリをプリコンパイルできます。次のwgetコマンドとリンクを使用して、バイナリファイルをダウンロードします。
$ wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
次に、次のtarコマンドを使用して、ダウンロードしたバイナリファイルを抽出します。
$ tar -xzvf spark-3.1.2-bin-hadoop3.2.tgz
最後に、抽出したsparkファイルを/optディレクトリに移動します。
$ sudo mv spark-3.1.2-bin-hadoop3.2 /opt/spark
環境変数の設定
コマンドが完全なパスなしで機能するために設定する必要のあるファイルの.profileにあるsparkのパス変数は、echoコマンドを使用するか、適切なテキストエディターを使用して手動で実行できます。より簡単な方法として、次のechoコマンドを実行します。
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile
$ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
$ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile
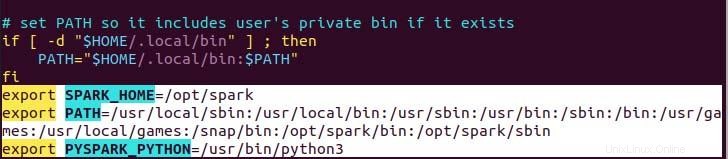
ご覧のとおり、パス変数は、echowith>>操作を使用して.profileファイルの下部に追加されます。
次に、次のコマンドを実行して、新しい環境変数の変更を適用します。
$ source ~/.profile
ApacheSparkのデプロイ
これで、次のコマンドを使用して、マスターサービスとワーカーサービスを実行できるすべての設定が完了しました。
$ start-master.sh
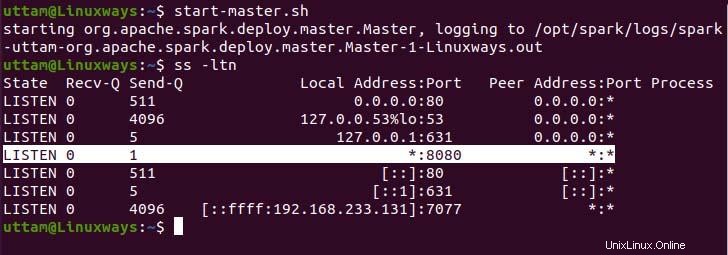
ご覧のとおり、sparkマスターサービスはポート8080で実行されています。sparkのデフォルトポートであるポート8080でローカルホストを参照すると。 URLを参照すると、次のタイプのユーザーインターフェイスが表示される場合があります。マスターサービスのみを開始しても、実行中のワーカープロセッサが見つからない場合があります。ワーカーサービスを開始すると、次の例のように新しいノードが一覧表示されます。
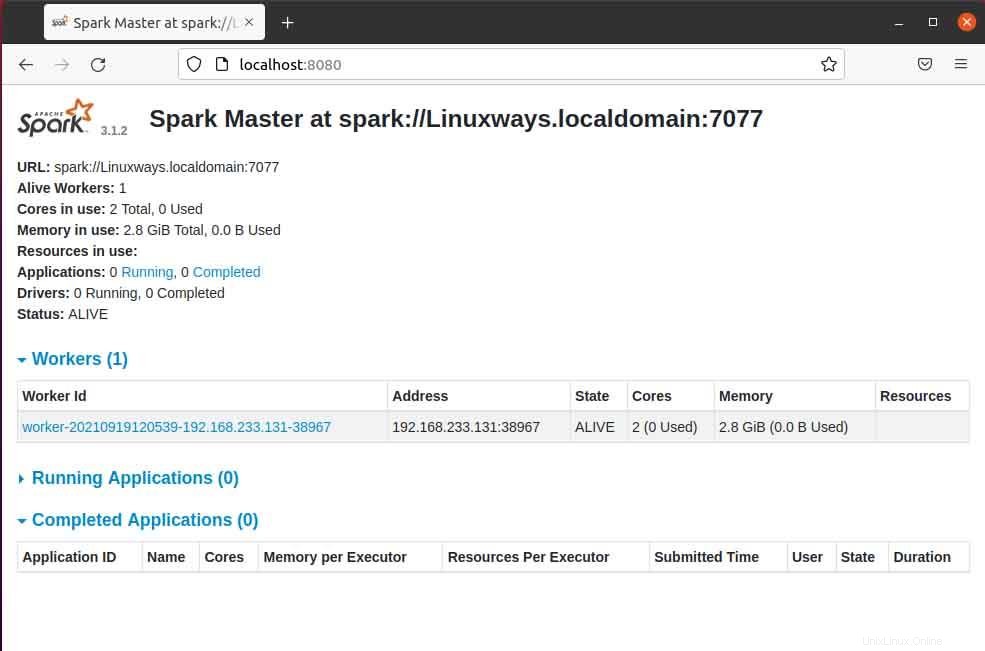
ブラウザでマスターページを開くと、このホストを介してワーカーサービスを接続するために使用されるsparkマスターspark:// HOST:PORTURLが表示されます。現在のホストの場合、sparkマスターのURLはspark://Linuxways.localdomain:7077であるため、ワーカープロセスを開始するには、次の方法でコマンドを実行する必要があります。
$ start-workers.sh <spark-master-url>
次のコマンドを実行してワーカーサービスを実行します。
$ start-workers.sh spark://Linuxways.localdomain:7077

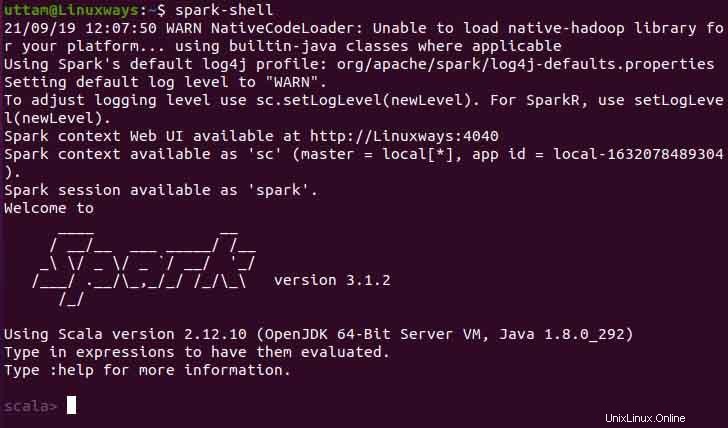
また、次のコマンドを実行することで、spark-shellを使用できます。
$ spark-shell
結論
この記事から、ubuntuにapachesparkをインストールして構成する方法を学んでいただければ幸いです。この記事では、プロセスをできるだけ理解できるようにしようとしました。