AWKは強力なデータ駆動型プログラミング言語であり、その起源はUnixの初期にまでさかのぼります。当初は「ワンライナー」プログラムを作成するために開発されましたが、その後、本格的なプログラミング言語に進化しました。 AWKの名前は、その作者であるAho、Weinberger、およびKernighanのイニシャルに由来しています。 Linuxおよびその他のUnixシステムのawkコマンドは、AWKスクリプトを実行するインタープリターを呼び出します。 awkのいくつかの実装は、gawk(GNU awk)、mawk(Minimal awk)、nawk(New awk)などの最近のシステムに存在します。 awkをマスターしたい場合は、以下の例を確認してください。
AWKプログラムを理解する
awkで記述されたプログラムは、単なるパターンとアクションのペアであるルールで構成されています。パターンは中括弧{}内にグループ化され、awkがパターンに一致するテキストを見つけるたびにアクション部分がトリガーされます。 awkはワンライナーを書くために開発されましたが、経験豊富なユーザーはそれを使って複雑なスクリプトを簡単に書くことができます。
AWKプログラムは、大規模なファイル処理に非常に役立ちます。特殊文字と区切り文字を使用してテキストフィールドを識別します。また、配列やループなどの高水準プログラミング構造も提供します。したがって、プレーンなawkを使用して堅牢なプログラムを作成することは非常に実行可能です。
Linuxでのawkコマンドの実用的な例
管理者は通常、他の種類のファイル操作と一緒にデータの抽出とレポートにawkを使用します。以下では、awkについて詳しく説明します。コマンドに注意深く従って、完全に理解するためにターミナルでそれらを試してください。
1。テキスト出力から特定のフィールドを印刷する
最も広く使用されているLinuxコマンドは、さまざまなフィールドを使用して出力を表示します。通常、このようなデータから特定のフィールドを抽出するには、Linuxのcutコマンドを使用します。ただし、以下のコマンドは、awkコマンドを使用してこれを行う方法を示しています。
$ who | awk '{print $1}' このコマンドは、whoコマンドの出力の最初のフィールドのみを表示します。したがって、現在ログに記録されているすべてのユーザーのユーザー名を取得するだけです。ここでは、 $ 1 最初のフィールドを表します。 $ Nを使用する必要があります N番目のフィールドを抽出する場合。
2。テキスト出力から複数のフィールドを印刷する
---awkインタープリターを使用すると、必要な数のフィールドを印刷できます。以下の例は、whoコマンドの出力から最初の2つのフィールドを抽出する方法を示しています。
$ who | awk '{print $1, $2}' 出力フィールドの順序を制御することもできます。次の例では、最初にwhoコマンドによって生成された2番目の列を表示し、次に2番目のフィールドに最初の列を表示します。
$ who | awk '{print $2, $1}' フィールドパラメータを省略してください( $ N )データ全体を表示します。
3。 BEGINステートメントを使用する
BEGINステートメントを使用すると、ユーザーはいくつかの既知の情報を出力に出力できます。これは通常、awkによって生成された出力データをフォーマットするために使用されます。このステートメントの構文を以下に示します。
BEGIN { Actions}
{ACTION} BEGINセクションを形成するアクションは常にトリガーされます。次に、awkは残りの行を1つずつ読み取り、何かを行う必要があるかどうかを確認します。
$ who | awk 'BEGIN {print "User\tFrom"} {print $1, $2}' 上記のコマンドは、whoコマンドの出力から抽出された2つの出力フィールドにラベルを付けます。
4。 ENDステートメントを使用する
ENDステートメントを使用して、操作の最後に特定のアクションが常に実行されるようにすることもできます。 ENDセクションをメインのアクションセットの後に配置するだけです。
$ who | awk 'BEGIN {print "User\tFrom"} {print $1, $2} END {print "--COMPLETED--"}' 上記のコマンドは、出力の最後に指定された文字列を追加します。
5。パターンを使用した検索
awkの動作の大部分は、パターンマッチングと正規表現に関係しています。すでに説明したように、awkは各入力行のパターンを検索し、一致がトリガーされたときにのみアクションを実行します。以前のルールはアクションのみで構成されていました。以下に、Linuxでawkコマンドを使用したパターンマッチングの基本を示します。
$ who | awk '/mary/ {print}' このコマンドは、ユーザーmaryが現在ログオンしているかどうかを確認します。一致するものが見つかった場合は、行全体が出力されます。
6。ファイルから情報を抽出する
awkコマンドはファイルで非常にうまく機能し、複雑なファイル処理タスクに使用できます。次のコマンドは、awkがファイルを処理する方法を示しています。
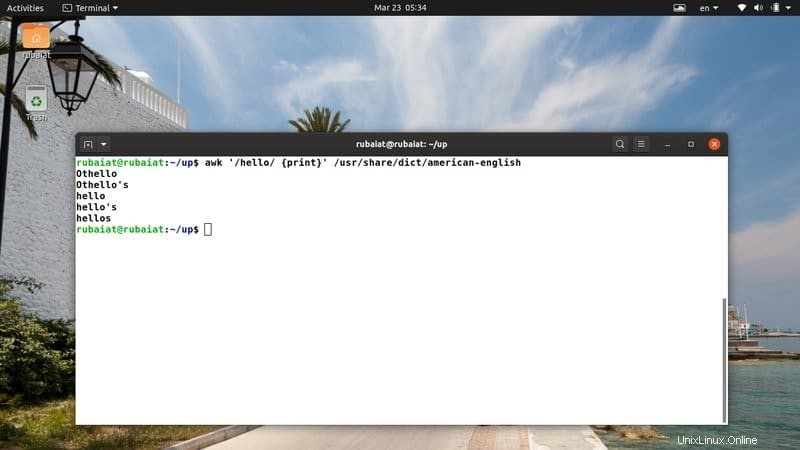
$ awk '/hello/ {print}' /usr/share/dict/american-english このコマンドは、アメリカ英語の辞書ファイルでパターン「hello」を検索します。ほとんどのLinuxベースのディストリビューションで利用できます。したがって、このファイルでawkプログラムを簡単に試すことができます。
7。ソースファイルからAWKスクリプトを読む
ワンライナープログラムを作成することは便利ですが、awkを完全に使用して大規模なプログラムを作成することもできます。それらを保存し、ソースファイルを使用してプログラムを実行することをお勧めします。
$ awk -f script-file $ awk --file script-file
-f または–ファイル オプションを使用すると、プログラムファイルを指定できます。ただし、Linuxシェルはプログラムコードをこのように解釈しないため、スクリプトファイル内で引用符(‘‘)を使用する必要はありません。
8。入力フィールドセパレータの設定
フィールドセパレータは、入力レコードを分割する区切り文字です。 -F を使用して、awkにフィールドセパレーターを簡単に指定できます。 または–field-separator オプション。以下のコマンドをチェックして、これがどのように機能するかを確認してください。
$ echo "This-is-a-simple-example" | awk -F - ' {print $1} '
$ echo "This-is-a-simple-example" | awk --field-separator - ' {print $1} ' Linuxでワンライナーawkコマンドではなくスクリプトファイルを使用する場合も同じように機能します。
9。状態に基づいて情報を印刷する
Linuxのcutコマンドについては、前のガイドで説明しました。次に、特定の基準が一致した場合にのみawkを使用して情報を抽出する方法を示します。そのガイドで使用したのと同じテストファイルを使用します。そこで、向こうに向かい、 test.txtのコピーを作成します。 ファイル。
$ awk '$4 > 50' test.txt
このコマンドは、人口が5,000万人を超えるtest.txtファイルからすべての国を出力します。
10。正規表現を比較して情報を印刷する
次のawkコマンドは、任意の行の3番目のフィールドにパターン「Lira」が含まれているかどうかを確認し、一致するものが見つかった場合は行全体を出力します。 Linuxのcutコマンドを説明するために使用したtest.txtファイルを再び使用しています。したがって、先に進む前に、このファイルがあることを確認してください。
$ awk '$3 ~ /Lira/' test.txt
必要に応じて、一致する特定の部分のみを印刷することを選択できます。
11。入力の行の総数を数える
awkコマンドには、多くの高度なことを簡単に実行できるようにする多くの特別な目的の変数があります。そのような変数の1つは、現在の行番号を含むNRです。
$ awk 'END {print NR} ' test.txt このコマンドは、test.txtファイルにある行数を出力します。最初に各行を繰り返し、ENDに達すると、NRの値を出力します。この場合は行の総数が含まれます。
12。出力フィールドセパレータの設定
以前、 -Fを使用して入力フィールドセパレータを選択する方法を示しました。 または–field-separator オプション。 awkコマンドを使用すると、出力フィールドの区切り文字を指定することもできます。以下の例は、実際の例を使用してこれを示しています。
$ date | awk 'OFS="-" {print$2,$3,$6}' このコマンドは、dd-mm-yy形式を使用して現在の日付を出力します。 awkなしで日付プログラムを実行して、デフォルトの出力がどのようになるかを確認します。
13。 If構文の使用
他の一般的なプログラミング言語と同様に、awkもif-else構造をユーザーに提供します。 awkのifステートメントの構文は次のとおりです。
if (expression)
{
first_action
second_action
} 対応するアクションは、条件式がtrueの場合にのみ実行されます。次の例は、参照ファイル test.txtを使用してこれを示しています。 。
$ awk '{ if ($4>100) print }' test.txt インデントを厳密に維持する必要はありません。
14。 If-Elseコンストラクトの使用
以下の構文を使用して、便利なif-elseラダーを作成できます。これらは、動的データを処理する複雑なawkスクリプトを考案するときに役立ちます。
if (expression) first_action else second_action
$ awk '{ if ($4>100) print; else print }' test.txtを出力します 4番目のフィールドは各行で100以下であるため、上記のコマンドは参照ファイル全体を出力します。
15。フィールド幅を設定する
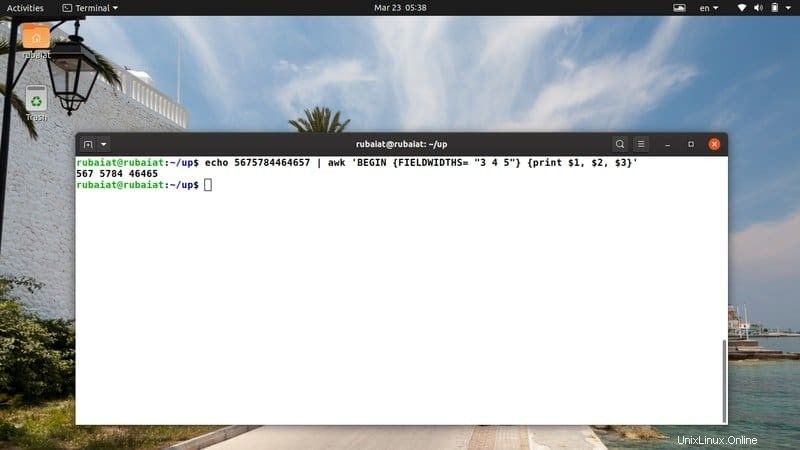
入力データが非常に乱雑である場合があり、ユーザーはレポートでそれらを視覚化するのが難しい場合があります。幸い、awkにはFIELDWIDTHSと呼ばれる強力な組み込み変数があり、空白で区切られた幅のリストを定義できます。
$ echo 5675784464657 | awk 'BEGIN {FIELDWIDTHS= "3 4 5"} {print $1, $2, $3}' 出力フィールドの幅を必要に応じて正確に制御できるため、分散データを解析するときに非常に便利です。
16。レコード区切り文字を設定する
RSまたはRecordSeparatorは、レコードの分離方法を指定できるもう1つの組み込み変数です。まず、このawk変数の動作を示すファイルを作成しましょう。
$ cat new.txt Melinda James 23 New Hampshire (222) 466-1234 Daniel James 99 Phonenix Road (322) 677-3412
$ awk 'BEGIN{FS="\n"; RS=""} {print $1,$3}' new.txt このコマンドは、ドキュメントを解析し、2人の名前と住所を吐き出します。
17。印刷環境変数
Linuxのawkコマンドを使用すると、変数ENVIRONを使用して環境変数を簡単に出力できます。以下のコマンドは、これを使用してPATH変数の内容を出力する方法を示しています。
$ awk 'BEGIN{ print ENVIRON["PATH"] }' ENVIRON変数の引数を代入することにより、任意の環境変数の内容を出力できます。次のコマンドは、環境変数HOMEの値を出力します。
$ awk 'BEGIN{ print ENVIRON["HOME"] }' 18。出力から一部のフィールドを省略
awkコマンドを使用すると、出力から特定の行を省略できます。次のコマンドは、参照ファイル test.txtを使用してこれを示します。 。
$ awk -F":" '{$2=""; print}' test.txt このコマンドは、各国の首都の名前を含むファイルの2番目の列を省略します。次のコマンドに示すように、複数のフィールドを省略することもできます。
$ awk -F":" '{$2="";$3="";print}' test.txt 19。空の行を削除する
データに含まれる空白行が多すぎる場合があります。 awkコマンドを使用すると、空の行を非常に簡単に削除できます。次のコマンドをチェックして、これが実際にどのように機能するかを確認してください。
$ awk '/^[ \t]*$/{next}{print}' new.txt 単純な正規表現とnextというawkビルトインを使用して、ファイルnew.txtからすべての空の行を削除しました。
20。末尾の空白を削除する
多くのLinuxコマンドの出力には、末尾の空白が含まれています。 Linuxでawkコマンドを使用して、スペースやタブなどの空白を削除できます。以下のコマンドをチェックして、awkを使用してこのような問題に取り組む方法を確認してください。
$ awk '{sub(/[ \t]*$/, "");print}' new.txt test.txt 参照ファイルに末尾の空白をいくつか追加し、awkがそれらを正常に削除したかどうかを確認します。これは私のマシンで正常に実行されました。
21。各行のフィールド数を確認してください
単純なawkワンライナーを使用して、行にフィールドがいくつあるかを簡単に確認できます。これを行うには多くの方法がありますが、このタスクにはawkの組み込み変数のいくつかを使用します。 NR変数は行番号を提供し、NF変数はフィールド数を提供します。
$ awk '{print NR,"-->",NF}' test.txt これで、 test.txtの1行にいくつのフィールドがあるかを確認できます。 資料。このファイルの各行には5つのフィールドが含まれているため、コマンドが期待どおりに機能していることが保証されます。
22。現在のファイル名を確認する
awk変数FILENAMEは、現在の入力ファイル名を確認するために使用されます。簡単な例を使用して、これがどのように機能するかを示しています。ただし、ファイル名が明示的にわからない場合や、複数の入力ファイルがある場合に役立ちます。
$ awk '{print FILENAME}' test.txt
$ awk '{print FILENAME}' test.txt new.txt 上記のコマンドは、入力ファイルの新しい行を処理するたびにawkが処理しているファイル名を出力します。
23。処理されたレコードの数を確認する
次の例は、awkコマンドによって処理されたレコードの数を確認する方法を示しています。多くのLinuxシステム管理者はレポートの生成にawkを使用しているため、非常に便利です。
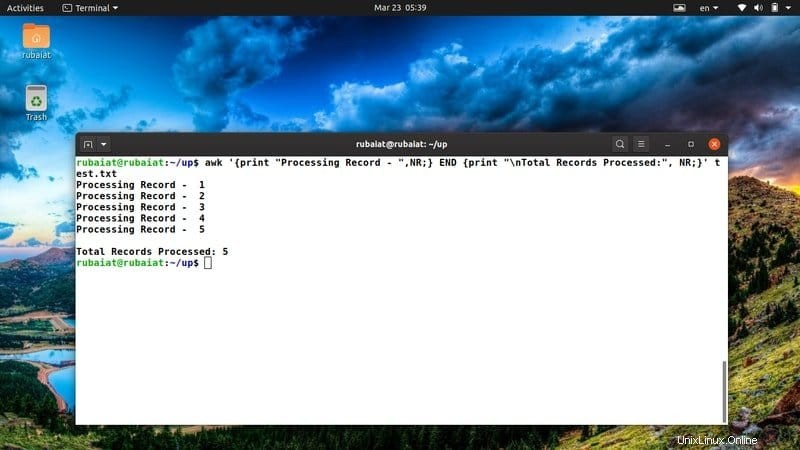
$ awk '{print "Processing Record - ",NR;} END {print "\nTotal Records Processed:", NR;}' test.txt このawkスニペットは、自分のアクションの概要を明確にするためによく使用します。新しいアイデアやアクションに対応するために簡単に調整できます。
24。レコード内の文字の総数を印刷する
awk言語は、レコードに存在する文字数を示すlength()と呼ばれる便利な関数を提供します。これは、多くのシナリオで非常に役立ちます。次の例をざっと見て、これがどのように機能するかを確認してください。
$ echo "A random text string..." | awk '{ print length($0); }' $ awk '{ print length($0); }' /etc/passwd 上記のコマンドは、入力文字列またはファイルの各行に存在する文字の総数を出力します。
25。指定された長さより長いすべての行を印刷する
上記のコマンドにいくつかの条件を追加して、事前定義された長さよりも大きい行のみを出力するようにすることができます。特定のレコードの長さについてすでに知っている場合に便利です。
$ echo "A random text string..." | awk 'length($0) > 10'
$ awk '{ length($0) > 5; }' /etc/passwd より多くのオプションや引数を投入して、要件に基づいてコマンドを微調整できます。
26。行数、文字数、単語数を印刷する
Linuxの次のawkコマンドは、指定された入力の行数、文字数、および単語数を出力します。この操作を行うために、NR変数といくつかの基本的な算術を利用します。
$ echo "This is a input line..." | awk '{ w += NF; c += length + 1 } END { print NR, w, c }' これは、入力文字列に1行、5単語、正確に24文字が存在することを示しています。
27。単語の頻度を計算する
連想配列とawkのforループを組み合わせて、ドキュメントの単語頻度を計算できます。次のコマンドは少し複雑に見えるかもしれませんが、基本的な構成を明確に理解すれば、かなり簡単です。
$ awk 'BEGIN {FS="[^a-zA-Z]+" } { for (i=1; i<=NF; i++) words[tolower($i)]++ } END { for (i in words) print i, words[i] }' test.txt ワンライナースニペットで問題が発生した場合は、次のコードを新しいファイルにコピーし、ソースを使用して実行してください。
$ cat > frequency.awk
BEGIN {
FS="[^a-zA-Z]+"
}
{
for (i=1; i<=NF; i++)
words[tolower($i)]++
}
END {
for (i in words)
print i, words[i]
} 次に、 -fを使用して実行します オプション。
$ awk -f frequency.awk test.txt
28。 AWKを使用してファイルの名前を変更する
awkコマンドは、特定の条件に一致するすべてのファイルの名前を変更するために使用できます。次のコマンドは、awkを使用してディレクトリ内のすべての.MP3ファイルの名前を.mp3ファイルに変更する方法を示しています。
$ touch {a,b,c,d,e}.MP3
$ ls *.MP3 | awk '{ printf("mv \"%s\" \"%s\"\n", $0, tolower($0)) }'
$ ls *.MP3 | awk '{ printf("mv \"%s\" \"%s\"\n", $0, tolower($0)) }' | sh まず、拡張子が.MP3のデモファイルをいくつか作成しました。 2番目のコマンドは、名前変更が成功したときに何が起こるかをユーザーに示します。最後に、最後のコマンドはLinuxでmvコマンドを使用して名前変更操作を実行します。
29。数値の平方根を印刷する
AWKは、数字を操作するためのいくつかの組み込み関数を提供します。それらの1つはsqrt()関数です。これは、指定された数値の平方根を返すCのような関数です。次の例をざっと見て、これが一般的にどのように機能するかを確認してください。
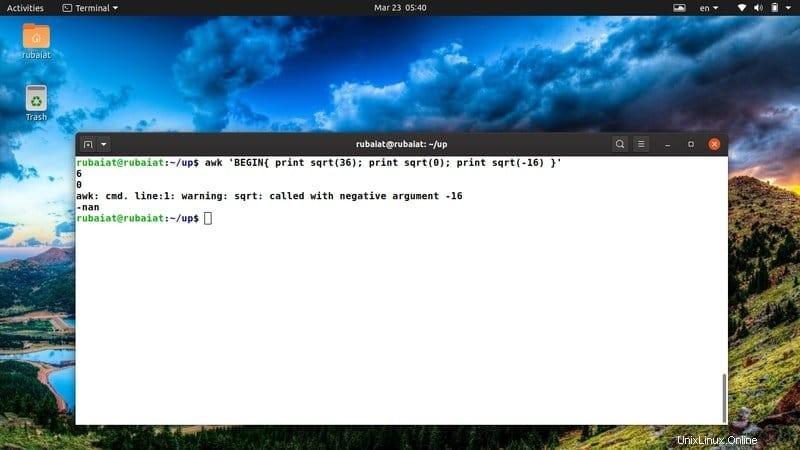
$ awk 'BEGIN{ print sqrt(36); print sqrt(0); print sqrt(-16) }' 負の数の平方根を判別できないため、出力にはsqrt(-12)の代わりに「nan」という特別なキーワードが表示されます。
30。数値の対数を印刷する
awk関数log()は、数値の自然対数を提供します。ただし、正の数でのみ機能するため、ユーザーの入力の検証に注意してください。そうしないと、誰かがあなたのawkプログラムを壊して、システムリソースへの特権のないアクセスを取得する可能性があります。
$ awk 'BEGIN{ print log(36); print log(0); print log(-16) }' 36の対数を確認し、0の対数が無限大であり、負の値の対数が「数値ではない」またはnanであることを確認する必要があります。
31。数値の指数を印刷する
指数os数nは、e^nの値を提供します。これは通常、大きな数字や複雑な算術ロジックを処理するawkスクリプトで使用されます。組み込みのawk関数exp()を使用して、数値の指数を生成できます。
$ awk 'BEGIN{ print exp(30); print log(0); print exp(-16) }' ただし、awkは非常に大きな数の指数を計算できません。 Cなどの低水準プログラミング言語を使用してこのような計算を行い、その値をawkスクリプトにフィードする必要があります。
32。 AWKを使用してランダムな番号を生成する
Linuxでawkコマンドを使用して、ランダムな数値を生成できます。これらの数値は0から1の範囲になりますが、0または1にはなりません。固定値に結果の数値を掛けて、より大きなランダム値を取得できます。
$ awk 'BEGIN{ print rand(); print rand()*99 }' rand()関数には引数は必要ありません。さらに、この関数によって生成される数値は正確にランダムではなく、疑似ランダムです。さらに、実行ごとにこれらの数値を予測するのは非常に簡単です。したがって、機密性の高い計算をこれらに依存するべきではありません。
33。赤のカラーコンパイラ警告
最新のLinuxコンパイラは、コードが言語標準を維持していない場合、またはプログラムの実行を停止しないエラーがある場合に警告をスローします。次のawkコマンドは、コンパイラによって生成された警告行を赤で出力します。
$ gcc -Wall main.c |& awk '/: warning:/{print "\x1B[01;31m" $0 "\x1B[m";next;}{print}' このコマンドは、コンパイラの警告を具体的に特定する場合に役立ちます。このコマンドは、gcc以外の任意のコンパイラーで使用できます。その特定のコンパイラーを反映するために、パターン/:warning:/を必ず変更してください。
34。ファイルシステムのUUID情報を印刷する
UUIDまたはUniversallyUniqueIdentifierは、Linuxファイルシステムなどのリソースを識別するために使用できる番号です。次のLinuxawkコマンドを使用して、ファイルシステムのUUID情報を簡単に出力できます。
$ awk '/UUID/ {print $0}' /etc/fstab このコマンドは、 / etc / fstabでテキストUUIDを検索します awkパターンを使用したファイル。関心のないファイルからコメントを返します。以下のコマンドは、UUIDで始まる行のみを取得するようにします。
$ awk '/^UUID/ {print $1}' /etc/fstab 出力を最初のフィールドに制限します。したがって、UUID番号のみを取得します。
35。 Linuxカーネルイメージバージョンを印刷する
さまざまなLinuxディストリビューションでさまざまなLinuxカーネルイメージが使用されています。システムがawkを使用して基づいている正確なカーネルイメージを簡単に印刷できます。次のコマンドをチェックして、これが一般的にどのように機能するかを確認してください。
$ uname -a | awk '{print $3}' 最初に-aを使用してunameコマンドを発行しました オプションを選択し、このデータをawkにパイプします。次に、awkを使用してカーネルイメージのバージョン情報を抽出しました。
36。行の前に行番号を追加する
ユーザーは、行番号を含まないテキストファイルに頻繁に遭遇する可能性があります。幸い、Linuxでawkコマンドを使用すると、ファイルに行番号を簡単に追加できます。以下の例をよく見て、これが実際にどのように機能するかを確認してください。
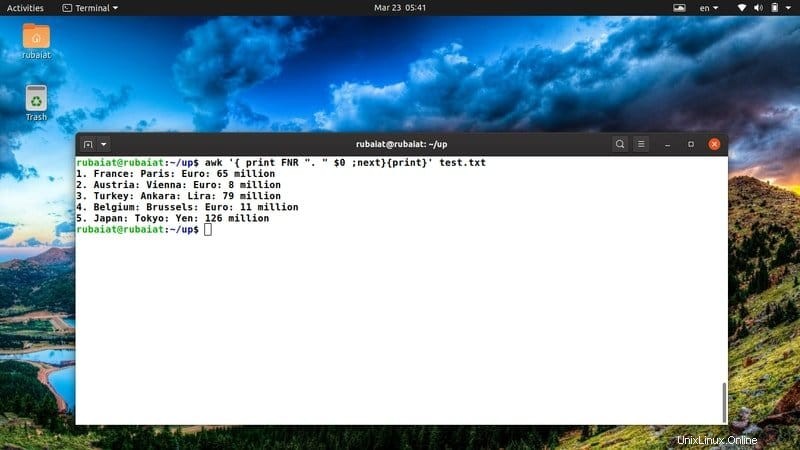
$ awk '{ print FNR ". " $0 ;next}{print}' test.txt 上記のコマンドは、test.txt参照ファイルの各行の前に行番号を追加します。これに対処するために、組み込みのawk変数FNRを利用します。
37。コンテンツを並べ替えた後にファイルを印刷する
awkを使用して、すべての行のソートされたリストを印刷することもできます。次のコマンドは、test.txt内のすべての国の名前を並べ替えられた順序で出力します。
$ awk -F ':' '{ print $1 }' test.txt | sort 次のコマンドは、 / etc / passwdからすべてのユーザーのログイン名を出力します ファイル。
$ awk -F ':' '{ print $1 }' /etc/passwd | sort 並べ替えコマンドを変更することで、並べ替えの順序を簡単に変更できます。
38。マニュアルページを印刷する
マニュアルページには、awkコマンドの詳細情報と、使用可能なすべてのオプションが含まれています。 awkコマンドを完全にマスターしたい人にとっては非常に重要です。
$ man awk
複雑なawk機能を学びたい場合、これは非常に役立ちます。問題が発生した場合は、このドキュメントを参照してください。
39。ヘルプページを印刷する
ヘルプページには、考えられるすべてのコマンドライン引数の要約情報が含まれています。次のいずれかのコマンドを使用して、awkのヘルプガイドを呼び出すことができます。
$ awk -h $ awk --help
awkで利用可能なすべてのオプションの概要が必要な場合は、このページを参照してください。
40。バージョン情報を印刷する
バージョン情報は、プログラムのビルドに関する情報を提供します。 awkのバージョンページには、著作権、コンパイルツールなどの情報が含まれています。この情報は、次のawkコマンドのいずれかを使用して表示できます。
$ awk -V $ awk --version
終わりの考え
Linuxのawkコマンドを使用すると、ファイル処理やシステムメンテナンスなど、あらゆる種類の処理を実行できます。日常のコンピューティングタスクを非常に簡単に処理するためのさまざまな操作を提供します。私たちの編集者は、テキストの操作や管理に使用できる40の便利なawkコマンドを使用してこのガイドをまとめました。 AWKはそれ自体が本格的なプログラミング言語であるため、同じ仕事をする方法は複数あります。ですから、なぜ私たちが特定のことを別の方法で行っているのか不思議に思わないでください。あなたはいつでもあなたのスキルセットと経験に基づいてあなた自身のレシピをキュレートすることができます。ご不明な点がございましたら、お気軽にお問い合わせください。