はじめに
awk commandは、ユーザーがデータを処理および操作し、フォーマットされたレポートを作成できるようにするLinuxツールおよびプログラミング言語です。このツールは、高度なテキスト処理のためのさまざまな操作をサポートし、複雑なデータ選択の表現を容易にします。
このチュートリアルでは、 awkが何であるかを学習します コマンドとその使用方法。

前提条件
- Linuxを実行しているシステム。
- ターミナルウィンドウへのアクセス。
AWKコマンド構文
awkの構文 コマンドは次のとおりです:
awk [options] 'selection_criteria {action}' input-file > output-file利用可能なオプションは次のとおりです。
| オプション | 説明 |
|---|---|
-F[セパレータ] | ファイル区切り文字を指定するために使用されます。デフォルトの区切り文字は空白です。 |
-f[ファイル名] | awkを含むファイルを指定するために使用されます 脚本。 awkを読み取ります 最初のコマンドライン引数ではなく、指定されたファイルからのプログラムソース。 |
-v | 変数を割り当てるために使用されます。 |
AWKコマンドはどのように機能しますか?
awk コマンドの主な目的は、情報検索とテキスト操作を行うことです。 Linuxで簡単に実行できます。このコマンドは、一連の入力行を順番にスキャンし、ユーザーが指定したパターンに一致する行を検索することで機能します。
パターンごとに、ユーザーは指定されたパターンに一致する各行で実行するアクションを指定できます。したがって、 awkを使用します 、ユーザーは複雑なログファイルを簡単に処理し、読み取り可能なレポートを出力できます。
AWKオペレーション
awk ユーザーが入力ファイルまたはテキストに対してさまざまな操作を実行できるようにします。利用可能な操作の一部は次のとおりです。
- ファイルを1行ずつスキャンします。
- 入力行/ファイルをフィールドに分割します。
- 入力行またはフィールドを指定されたパターンと比較します。
- 一致した行に対してさまざまなアクションを実行します。
- 出力行をフォーマットします。
- 算術演算と文字列演算を実行します。
- 出力で制御フローとループを使用します。
- 指定された構造に従ってファイルとデータを変換します。
- フォーマットされたレポートを生成します。
AWKステートメント
このコマンドは、基本的な制御フローステートメント( if-else )を提供します 、 while 、 for 、 break )また、ユーザーが中かっこを使用してステートメントをグループ化できるようにします {} 。
- if-else
if-else ステートメントは、括弧内に指定された条件を評価することによって機能し、条件がtrueの場合、 ifに続くステートメントが機能します。 ステートメントが実行されます。 else 一部はオプションです。
例:
awk -F ',' '{if($2==$3){print $1","$2","$3} else {print "No Duplicates"}}' answers.txt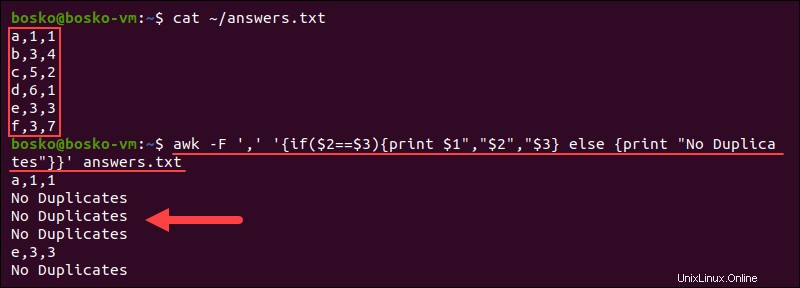
出力には、重複が存在する行が表示され、重複なしと表示されます。 行に重複する回答がない場合。
- ながら
while ステートメントは、指定された条件が真である限り、ターゲットステートメントを繰り返し実行します。つまり、Cプログラミング言語のように動作します。条件が真の場合、ループの本体が実行されます。条件がfalseの場合、 awk 実行を続行します。
たとえば、次のステートメントは awkに指示します すべての入力フィールドを1行に1つずつ出力するには:
awk '{i=0; while(i<=NF) { print i ":"$i; i++;}}' employees.txt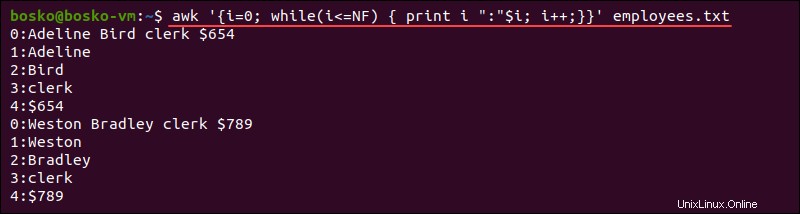
- for
for ステートメントもCのステートメントと同様に機能し、ユーザーが特定の回数実行する必要のあるループを作成できるようにします。
例:
awk 'BEGIN{for(i=1; i<=10; i++) print "The square of", i, "is", i*i;}'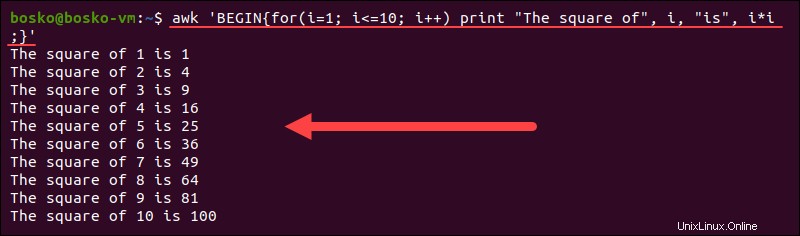
上記のステートメントは、 iの値を増やします 10に達するまで1ずつ、 iの2乗を計算します 毎回。
- 休憩
ブレーク ステートメントは、囲んでいる whileからすぐに終了します またはfor 。次の反復を開始するには、続行を使用します ステートメント。
次の ステートメントはawkに指示します 次のレコードにスキップして、上からパターンのスキャンを開始します。 終了 ステートメントはawkに指示します 入力が終了したこと。
以下は、 breakの例です。 ステートメント:
awk 'BEGIN{x=1; while(1) {print "Example"; if ( x==5 ) break; x++; }}'
上記のコマンドは、5回の反復後にループを中断します。
AWKパターン
awkのアクションの前にパターンを挿入する セレクターとして機能します 。セレクターは、アクションを実行するかどうかを決定します。次の式はパターンとして機能します。
- 正規表現。
- 算術関係式。
- 文字列値の式。
- 上記の式の任意のブール値の組み合わせ。
次のセクションでは、上記の表現とその使用方法について説明します。
正規表現パターン
正規表現パターンは、スラッシュで囲まれた文字列を含む最も単純な形式の式です。文字、数字、または両方の組み合わせのシーケンスにすることができます。
次の例では、プログラムは「A」で始まるすべての行を出力します。指定された文字列がより大きな単語の一部である場合は、それも印刷されます。
awk '$1 ~ /^A/ {print $0}' employees.txt
リレーショナル式のパターン
別のタイプのawk パターンは関係表現パターンです。関係式のパターンには、次の関係演算子のいずれかを使用することが含まれます: <、<=、==、!=、> = 、および> 。
以下は、 awkの例です。 関係式:
awk 'BEGIN { a = 10; b = 10; if (a == b) print "a == b" }'
範囲パターン
範囲パターンは、2つのパターンで構成されるパターンです。 カンマで区切ります。範囲パターンは、パターン1とパターン2の出現の間の各行に対して指定されたアクションを実行します。
例:
awk '/clerk/, /manager/ {print $1, $2}' employees.txt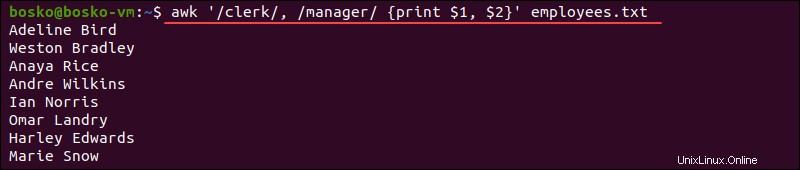
上記のパターンは、 awkに指示します キーワード「clerk」と「manager」を含む入力のすべての行を出力します。
特別な表現パターン
特別な表現パターンには、 BEGINが含まれます およびEND プログラムの初期化と終了を示します。 BEGIN パターンは、最初のレコードが処理される前に、入力の先頭と一致します。 END パターンは、最後のレコードが処理された後、入力の終わりと一致します。
たとえば、 awkに指示できます プロセスの開始時と終了時にメッセージを表示するには:
awk 'BEGIN { print "List of debtors:" }; {print $1, $2}; END {print "End of the debtor list"}' debtors.txt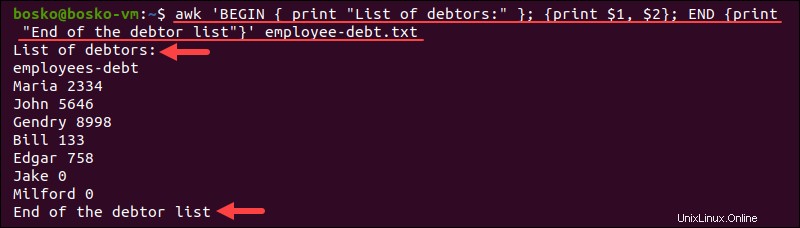
パターンの組み合わせ
awk コマンドを使用すると、ユーザーは論理演算子を使用して2つ以上のパターンを組み合わせることができます。組み合わせたパターンは、任意のブール型のパターンの組み合わせにすることができます。パターンを組み合わせるための論理演算子は次のとおりです。
-
||(または) -
&&(および) -
!(ではない)
例:
awk '$3 > 10 && $4 < 20 {print $1, $2}' employees.txt 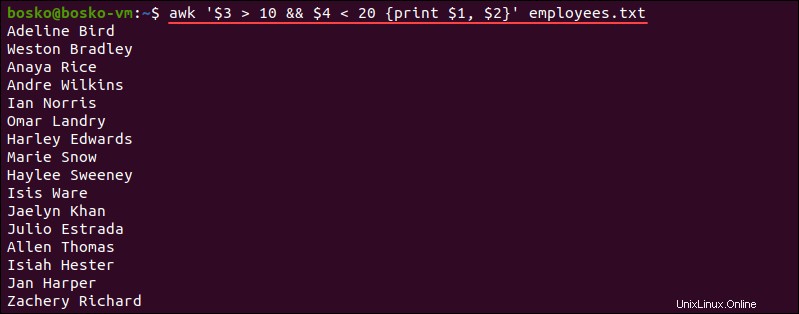
出力は、3番目のフィールドが10より大きく、4番目のフィールドが20より小さいレコードの1番目と2番目のフィールドを出力します。
AWK変数
awk コマンドには組み込みのフィールド変数があり、入力ファイルをフィールドと呼ばれる個別の部分に分割します。 。 awk 次の変数を各データフィールドに割り当てます:
-
$ 0。行全体を指定するために使用されます。 -
$ 1。最初のフィールドを指定します。 -
$ 2。 2番目のフィールドを指定します。 - など
その他の利用可能な組み込みのawk 変数は次のとおりです:
-
NR。入力レコード(通常は行)の数をカウントします。awkコマンドは、ファイル内のレコードごとに1回パターン/アクションステートメントを実行します。
例:
awk '{print NR,$0}' employees.txt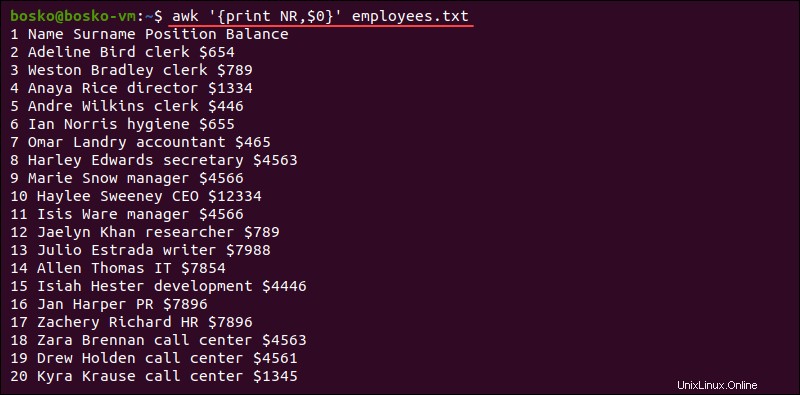
このコマンドは、出力に行番号を表示します。
-
NF。現在の入力レコードのフィールド数をカウントし、ファイルの最後のフィールドを表示します。
例:
awk '{print $NF}' employees.txt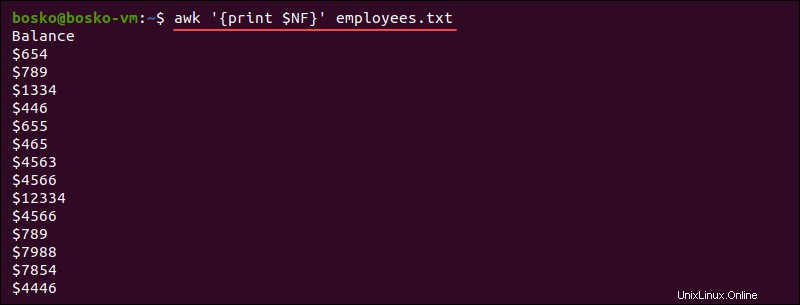
-
FS。入力行のフィールドを分割するために使用される文字が含まれます。デフォルトの区切り文字はスペースですが、FSを使用できます セパレータを別の文字に再割り当てします(通常はBEGIN) )。
たとえば、 etc / passwdを作成できます。 ファイル(ユーザーリスト)は、区切り文字をコロン( :)から変更することで読みやすくなります )ダッシュ( / )フィールドセパレータも印刷します:
awk -FS 'BEGIN{FS=":"; OFS="-"} {print $0}' /etc/passwd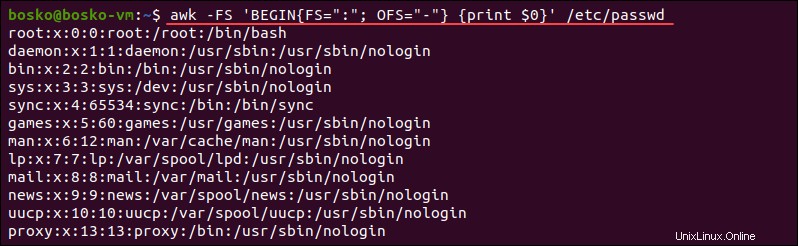
-
RS。現在のレコード区切り文字を格納します。デフォルトの入力行は入力レコードであり、これにより改行がデフォルトのレコード区切り文字になります。このコマンドは、入力がコンマ区切りファイル(CSV)の場合に役立ちます。
例:
awk 'BEGIN {FS="-"; RS=","; OFS=" owes Rs. "} {print $1,$2}' debtors.txt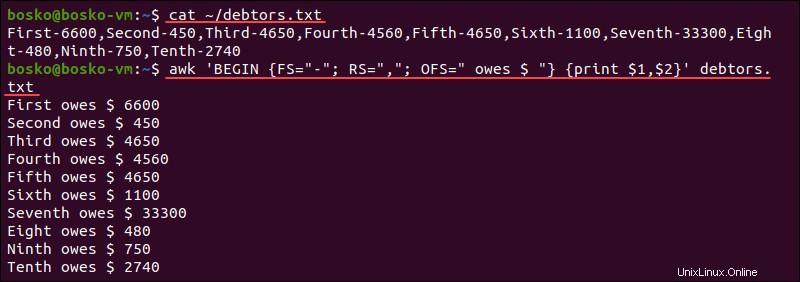
-
OFS。印刷時にフィールドを区切る出力フィールドセパレータを格納します。デフォルトの区切り文字は空白です。印刷されたファイルにコンマで区切られた複数のパラメーターがある場合は常に、OFS各パラメータの間に値が出力されます。
例:
awk 'OFS=" works as " {print $1,$3}' employees.txt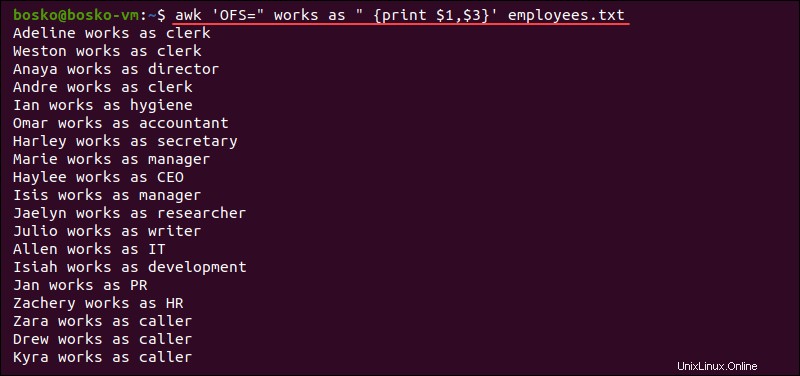
AWKアクション
awk ツールは、パターンとアクションのペアを含むルールに従います。アクションは、中括弧で囲まれたステートメントで構成されます {} これには、式、制御ステートメント、複合ステートメント、入力および出力ステートメント、および削除ステートメントが含まれます。これらのステートメントは、上記のセクションで説明されています。
awkを作成します 次の構文を使用したスクリプト:
awk '{action}' 例:
awk '{print "How to use the awk command"}'
この簡単なコマンドは、 awkに指示します コマンドを実行するたびに指定された文字列を出力します。 Ctrl + Dを使用してプログラムを終了します 。
AWKコマンドの使用方法-例
データの操作とフォーマットされた出力の生成は別として、 awk テキスト処理コマンドだけでなく、スクリプト言語であるため、他の用途もあります。このセクションでは、 awkの代替ユースケースについて説明します 。
- 計算 。
awkコマンドを使用すると、算術計算を実行できます。例:
df | awk '/\/dev\/loop/ {print $1"\t"$2 + $3}'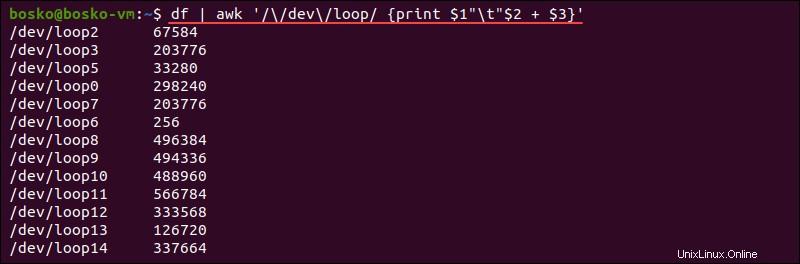
この例では、dfコマンドにパイプし、レポートで生成された情報を使用して、 / devのみを含むマウントされたファイルシステムで使用可能で使用されている合計メモリを計算します。 および/loop 名前に。
生成されたレポートには、 / devのメモリ合計が表示されます。 および/loop dfの2列目と3列目のファイルシステム 出力。
- フィルタリング 。
awkコマンドを使用すると、行の長さを制限して出力をフィルタリングできます。例:
awk 'length($0) > 8' /etc/shells
この例では、 / etc / shellsを実行しました awkを介したシステムファイル そして、8文字を超える行のみを含むように出力をフィルタリングしました。
- 監視 。
psにパイプして、特定のプロセスがLinuxで実行されているかどうかを確認します 指図。例:
ps -ef | awk '{ if($NF == "clipboard") print $0}'
出力には、マシンで実行されているすべてのプロセスのリストが出力され、最後のフィールドは指定されたパターンに一致します。
- カウント 。
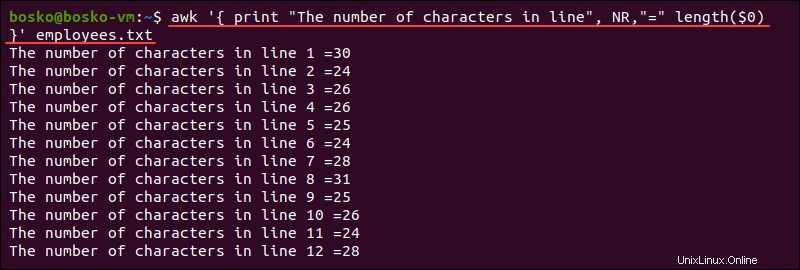
awkを使用できます 1行の文字数をカウントし、その数を結果に出力します。例:
awk '{ print "The number of characters in line", NR,"=" length($0) }' employees.txt