はじめに
wc コマンドはcoreutilsの一部です GNUコアユーティリティを含むLinuxパッケージ。 wcを使用する ファイルまたは標準入力の文字、単語、行、およびバイト数をカウントします。
このチュートリアルでは、 wcについて詳しく説明します。 コマンドとそのオプション。この記事には、 wcの方法を示すための役立つ例も含まれています。 他のコマンドと連携します。

前提条件
- Linuxを実行しているシステム。
- コマンドライン/ターミナルへのアクセス。
Linuxwcコマンド構文
wc コマンドは次の構文を取ります:
wc [options] [location/file]デフォルトでは、出力にはファイル内の新しい行、単語、バイト数が表示され、その後にファイル名が続きます。

複数のファイルの統計を表示するには、1つのコマンドでファイルを一覧表示します。
wc [options] [location/file1] [location/file2] [location/file3]出力には、各ファイルの情報が表示され、その後に行、単語、バイトの総数が表示されます。

入力リダイレクトを使用してwcを停止します ファイル名の印刷から:
wc < [file/location]
または、catコマンドを使用してファイルの内容を一覧表示し、出力を wcにパイプします。 :
cat [file/location] | wc
Linuxwcコマンドオプション
wc コマンドは次のオプションを取ります:
| オプション | 説明 |
|---|---|
-c、-bytes | バイト数を出力します。 |
-m、--chars | 文字数を出力します。 |
-l、--lines | 行数を出力します。 |
-files0-from =[file] | ファイル内のNULで終了する名前で指定されたファイルから入力を読み取ります。 -の場合 ファイルの代わりに提供される場合、コマンドは標準入力から読み取ります。 |
-L、-max-line-length | 最長の行の長さを印刷します。 |
-w、--words | 単語数を出力します。 |
-help | ヘルプを表示します。 |
-version | バージョン情報を表示します。 |
Linuxwcの例
以下の例は、 wcの使用法を示しています。 指図。
findコマンドでwcを使用する
findコマンドを使用して、 wcの出力を提供します 。次の例は、 / etc内の各ファイルの文字数を示しています。 ファイル名が30で始まるフォルダ :
find /etc -name '30*' -print0 | wc -m --files0-from=-
findの出力 wcにパイプされます 、次に関連する統計を出力します。
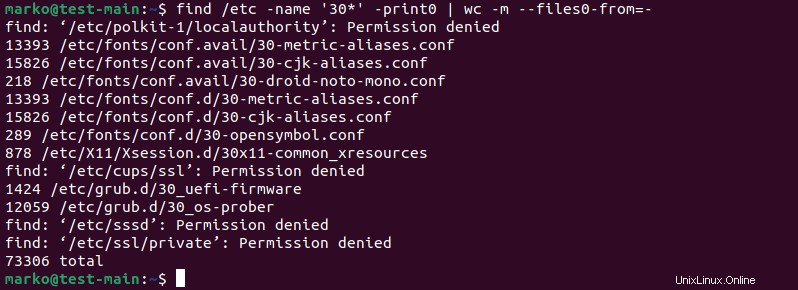
ファイルリストの統計を表示
wc コマンドは、ファイル名を持つファイルから読み取り、リスト内の各ファイルの統計を提供できます。 wcの場合 ファイルを正しく読み取ることができるようにするには、ファイル内の名前をNULで終了する必要があります。
findを使用する 現在のディレクトリにあるファイルのNUL終了リストを含むファイルを作成するには:
find * -print0 > search.txt次のコマンドはファイルを読み取り、各ファイルのバイト数を提供します。
wc -c --files0-from=search.txt
wcを使用してファイルとディレクトリをカウントする
現在のディレクトリ内のファイルとディレクトリの数を見つけるには、lsコマンドを wcにパイプします。 :
ls | wc -l
-l </ code> オプションは、 lsの行数をカウントします 出力。この数は、ファイルとディレクトリの総数に対応します。

複数のファイルにわたってwcカウントを実行する
wcを使用する 複数のファイルにわたる文字、単語、行、およびバイトをカウントします。たとえば、ディレクトリ内のすべてのTXTファイルの合計単語数を確認するには、次のように入力します。
cat *.txt | wc -w
猫 コマンドはwcにパイプします ディレクトリ内のすべてのTXTファイルの内容。 wc -w 単語の総数を数えます。

すべてのファイルで最長の行を見つける
-L オプションは、各ファイルの最長行の長さを出力します。複数のファイルが指定されている場合、合計 行には、すべてのファイルの最長の行が表示されます。
たとえば、ディレクトリ内のすべてのTXTファイルで最長の行を検索するには、次のように入力します。
wc -L *.txt
wc TXTファイルを処理し、ファイルごとに、最長行の文字数を出力します。

最後の行は、すべてのファイルの最長行の文字数を示しています。