システム管理者には、実行中のプロセスを表示および管理するための多くのツールがあります。私にとって、これらは主にトップでした 、上 、および htop 。数年前、私はGlancesを見つけました。これは、他のお気に入りにはない情報を表示するツールです。これらのツールはすべてCPUとメモリの使用量を監視し、それらのほとんどは実行中のプロセスに関する情報を一覧表示します(少なくとも)。ただし、Glanceは、ファイルシステムI / O、ネットワークI / O、センサーの読み取り値も監視します。これらの読み取り値は、CPUやその他のハードウェアの温度、ファンの速度、ハードウェアデバイスおよび論理ボリュームごとのディスク使用量を表示できます。
私の記事Linuxシステム監視用の4つのオープンソースツールでGlanceについて言及しました。 、しかし、私はこの記事でそれをより深く掘り下げます。私の以前の記事を読んだ場合、この情報の一部はおなじみかもしれませんが、ここでいくつかの新しい情報も見つける必要があります。
GlanceはPythonで記述されているため、クロスプラットフォームです。現在のバージョンのPythonがインストールされているWindowsおよびその他のホストにインストールできます。ほとんどのLinuxディストリビューション(私の場合はFedora)のリポジトリにはGlanceがあります。そうでない場合、または別のオペレーティングシステム(Windowsなど)を使用している場合、またはソースから直接取得したい場合は、GlanceのGitHubリポジトリにダウンロードしてインストールする手順があります。
この記事のコマンドを試す間、テストマシンでGlanceを実行することをお勧めします。テストに使用できる物理ホストがない場合は、仮想マシン(VM)でGlanceを探索できますが、ハードウェアセンサーセクションは表示されません。結局のところ、VMには実際のハードウェアはありません。
LinuxホストでGlanceを起動するには、ターミナルセッションを開き、コマンド glanceを入力します。 。
Glanceには、概要、プロセス、アラートの3つの主要なセクションと、サイドバーがあります。 Glanceを使用するためのそれらとその他の詳細を今すぐ調べます。
上位数行のGlanceの[概要]セクションには、他のモニターの[概要]セクションにある情報とほとんど同じ情報が含まれています。端末に十分な水平方向のスペースがある場合、Glanceは棒グラフと数値インジケーターの両方でCPU使用率を表示できます。それ以外の場合は、番号のみが表示されます。
Glanceの[概要]セクションは、他のモニター(トップなど)のセクションよりも気に入っています。 );わかりやすい形式で正しい情報を提供していると思います。
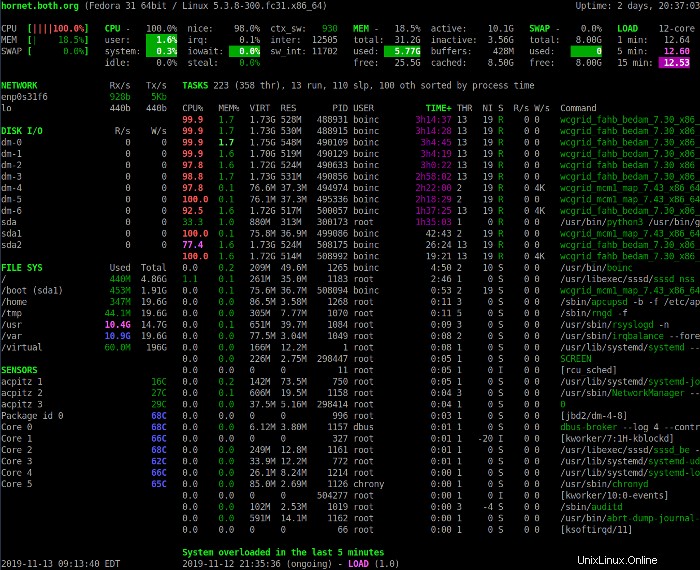
上記の[概要]セクションでは、システムのステータスの概要を説明します。最初の行は、ホスト名、Linuxディストリビューション、カーネルバージョン、およびシステム稼働時間を示しています。
次の4行には、CPU、メモリ使用量、スワップ、および負荷の統計が表示されます。左側の列には、使用中のCPU、メモリ、およびスワップスペースの割合が表示されます。また、システムに存在するすべてのCPUの結合された統計も表示されます。
1を押します 統合されたCPU使用率の表示と個々のCPUの表示を切り替えるためのキー。次の画像は、個々のCPU統計を含むGlance表示を示しています。
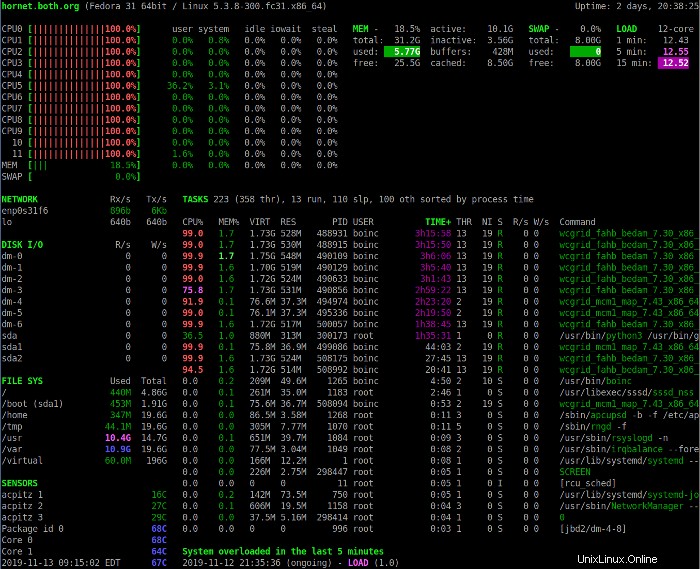
このビューには、いくつかの追加のCPU統計が含まれています。どちらの表示モードでも、CPU使用率フィールドの説明は、CPUセクションに表示されるデータを解釈するのに役立ちます。 CPUには0(ゼロ)から始まる番号が付けられていることに注意してください。
| CPU | これは、使用可能な合計のパーセンテージとしての現在のCPU使用率です。 |
| ユーザー | これらは、ユーザースペースで実行されている、つまりカーネルでは実行されていないアプリケーションやその他のプログラムです。 |
| システム | これらはカーネルレベルの関数です。カーネル自体にかかるCPU時間は含まれず、カーネルシステムコールのみが含まれます。 |
| アイドル | これはアイドル時間です。つまり、実行中のプロセスで使用されていない時間です。 |
| いい | これは、ポジティブで素晴らしいレベルで実行されているプロセスによって使用される時間です。 |
| irq | これらはCPU時間を要する割り込み要求です。 |
| iowait | これらはI/Oが発生するのを待つために費やされるCPUサイクルであり、これは無駄なCPU時間です。 |
| 盗む | ハイパーバイザーが別の仮想プロセッサにサービスを提供しているときに、仮想CPUが実際のCPUを待機するCPUサイクルの割合。 |
| ctx-sw | これらは1秒あたりのコンテキストスイッチの数です。これは、CPUが1つのプロセスの実行から別のプロセスの実行に切り替わる1秒あたりの回数を表します。 |
| inter | これは、1秒あたりのハードウェア割り込みの数です。ハードウェア割り込みは、ハードドライブなどのハードウェアデバイスがCPUにデータ転送が完了したこと、またはネットワークインターフェイスカードがさらにデータを受け入れる準備ができていることを通知したときに発生します。 |
| sw_int | ソフトウェア割り込みは、要求されたタスクが完了したこと、またはソフトウェアが何かの準備ができていることをCPUに通知します。これらはカーネルレベルのソフトウェアでより一般的である傾向があります。 |
素敵な数字について
適切な数値は、管理者がプロセスの優先度に影響を与えるために使用するメカニズムです。プロセスの優先度を直接変更することはできませんが、nice番号を変更すると、カーネルスケジューラの優先度設定アルゴリズムの結果が変更される可能性があります。良い数字は-20から+19まであり、数字が大きいほど良いです。デフォルトのnice番号は0で、デフォルトの優先度は20です。nice番号をゼロより大きく設定すると、優先度番号がいくらか増加し、プロセスがより適切になり、CPUサイクルの貪欲さが低下します。ナイス数をより負の数に設定すると、優先順位の数値が低くなり、プロセスのニースが低下します。素敵な数字は、reniceコマンドを使用するか、top、top、htop内から変更できます。
メモリ
[概要]セクションの[メモリ]部分には、メモリ使用量に関する統計が含まれています。
| MEM | これは、使用可能な合計量のパーセントとしてメモリ使用量を示します。 |
| 合計 | これは、ホストにインストールされているRAMメモリの合計量から、ディスプレイアダプタに割り当てられている量を差し引いたものです。 |
| 使用済み | これは、システムおよびアプリケーションプログラムによって使用されているメモリの合計量ですが、キャッシュやバッファは含まれていません。 |
| 無料 | これは空きメモリの量です。 |
| アクティブ | これはアクティブに使用されているメモリの量です。非アクティブなメモリは、必要に応じてディスクにスワップされる可能性があります。 |
| 非アクティブ | これは使用中のメモリですが、しばらくの間アクセスされていません。 |
| バッファ | これはバッファスペースに使用されるメモリです。これは通常、通信やネットワークなどのI/Oで使用されます。データは、ソフトウェアがデータを取得して使用できるようになるまで、またはストレージデバイスに送信したり、ネットワークに送信したりできるようになるまで、受信および保存されます。 |
| キャッシュ | これは、プログラムで使用できるようになるまで、またはディスクに保存できるようになるまで、ディスク転送用のデータを保存するために使用されるメモリです。 |
スワップスペースとその仕組みについて少し理解していれば、スワップセクションは自明です。これは、使用可能な合計スワップスペースの量、使用されている量、および残りの量を示しています。
[概要]セクションの[負荷]部分には、1分、5分、および15分の負荷平均が表示されます。
数字キー1を使用できます 、 3 、 4 、および 5 このセクションのデータの表示を変更します。 2 キーを押すと、左側のサイドバーのオンとオフが切り替わります。
負荷平均は、CPU使用率を測定するための重要な基準ですが、一般的に誤解されています。しかし、たとえば、1分(または5分または10分)の平均負荷が4.04であると言った場合、それは実際にはどういう意味ですか?負荷平均は、CPUの需要の尺度と見なすことができます。これは、CPU時間を待機している命令の平均数を表す数値であるため、CPUパフォーマンスの真の尺度です。
システム管理者の詳細
- Sysadminブログを有効にする
- 自動化されたエンタープライズ:自動化によってITを管理するためのガイド
- eBook:システム管理者向けのAnsible自動化
- 現場からの物語:IT自動化に関するシステム管理者ガイド
- eBook:SREおよびシステム管理者向けのKubernetesのガイド
- 最新のシステム管理者の記事
たとえば、完全に使用されているシングルプロセッサシステムのCPUの平均負荷は1です。これは、CPUが需要に正確に対応していることを意味します。言い換えれば、それは完璧な利用率を持っています。負荷平均が1未満の場合は、CPUが十分に活用されていないことを意味し、負荷平均が1より大きい場合は、CPUが過剰に使用されており、需要が不足していることを意味します。たとえば、シングルCPUシステムの負荷平均が1.5の場合、CPU命令の3分の1は、前の命令が完了するまで実行を待機する必要があることを示しています。
これは、複数のプロセッサにも当てはまります。 4 CPUシステムの負荷平均が4の場合、完全に使用されます。たとえば、負荷平均が3.24の場合、3つのプロセッサが完全に使用され、1つは約24%で使用されます。上記の例では、4 CPUシステムの1分間の負荷平均は4.04です。これは、4つのCPUの間に残りの容量がなく、いくつかの命令が強制的に待機されることを意味します。完全に利用された4CPUシステムは、4.00の平均負荷を示します。これは、システムが完全にロードされているが、過負荷ではないことを意味します。
最適な負荷平均条件は、負荷平均がシステム内のCPUの総数と等しくなることです。つまり、すべてのCPUが完全に使用されており、命令を強制的に待機させる必要はありません。しかし、現実は乱雑であり、最適な条件が満たされることはめったにありません。ホストが100%の使用率で実行されている場合、これではCPU負荷要件の急上昇は許容されません。
長期的な負荷平均は、全体的な使用率の傾向を示しています。
Linuxジャーナル 2006年12月1日号に、負荷平均、理論、その背後にある数学、およびそれらの解釈方法に関する優れた記事が掲載されました。残念ながら、 Linux Journal は公開を中止し、そのアーカイブは直接利用できなくなったため、サードパーティのアーカイブへのリンクがあります。
CPUホッグの検索
Glancesのようなツールを使用する理由の1つは、CPU時間を過度に消費しているプロセスを見つけることです。新しいターミナルセッション(Glanceを実行しているセッションとは異なります)を開き、次のCPUを大量に消費するBashプログラムを入力して開始します。
X=0;while [ 1 ];do echo $X;X=$((X+1));doneこのプログラムはCPUを大量に消費し、使用可能なすべてのCPUサイクルを使い果たします。この記事を読み終えてGlanceを試してみる間、実行できるようにしてください。これにより、CPUサイクルを占有するプログラムがどのように見えるかがわかります。 TIME + の累積時間だけでなく、時間の経過に伴う負荷平均への影響も必ず観察してください。 このプロセスの列。
「プロセス」セクションには、実行中の各プロセスに関する標準情報が表示されます。表示モードと端末画面のサイズに応じて、実行中のプロセスについて異なる列の情報が表示されます。十分な幅のある端末を使用するデフォルトのモードでは、以下の列が表示されます。ターミナル画面のサイズを変更すると、表示される列が自動的に変更されます。次の列は通常、プロセスごとに左から右に表示されます。
| CPU% | これは、単一コアのパーセンテージとしてのCPU時間の量です。たとえば、98%は、シングルコアで使用可能なCPUサイクルの98%を表します。複数のプロセスで最大100%のCPU使用率が表示される場合があります。 |
| MEM% | これは、プロセスで使用されるRAMメモリの量であり、ホスト内の仮想メモリの合計に対する割合です。 |
| VIRT | これは、12メガバイトの場合は12Mなど、人間が読める形式でプロセスによって使用される仮想メモリの量です。 |
| RES | これは、プロセスによって使用される物理(常駐)メモリの量を指します。繰り返しになりますが、これは人間が読める形式であり、 Kのインジケーターが付いています。 、 M 、または G 、キロバイト、メガバイト、またはギガバイトを指定します。 |
| PID | すべてのプロセスには、PIDと呼ばれる識別番号があります。この番号は、 reniceなどのコマンドで使用できます。 およびキル 、プロセスを管理します。 キルを忘れないでください ユーティリティは、「kill」シグナル以外の別のプロセスにシグナルを送信できます。 |
| ユーザー | これは、プロセスを所有するユーザーの名前です。 |
| TIME + | これは、プロセスが開始されてからプロセスによって発生したCPU時間の累積量を示します。 |
| THR | これは、このプロセスで現在実行されているスレッドの総数です。 |
| NI | これはプロセスの良い数です。 |
| S | これは現在のステータスです。 ( R )わからない、( S )眠っている、(私 )dle、 T またはt デバッグトレース中にプロセスが停止したとき、または( Z )オンビー。ゾンビは、殺されたが完全には死んでいないプロセスであるため、RAMなどのシステムリソースを消費し続けます。 |
| R/sおよびW/s | これらは1秒あたりのディスクの読み取りと書き込みです。 |
| コマンド | これは、プロセスを開始するために使用されるコマンドです。 |
Glanceは通常、デフォルトのソート列を自動的に決定します。プロセスは自動的に並べ替えることができます( a )、またはCPU( c )、メモリ( m )、名前( p )、ユーザー( u )、I / O率( i )、または時間( t )。プロセスは、最も使用されているリソースによって自動的にソートされます。上の画像では、 TIME + 列が強調表示されます。
Glanceは、画面の下部に、イベントの時間と期間を含む警告と重要なアラートも表示します。これは、問題を診断しようとしていて、一度に何時間も画面を見つめることができない場合に役立ちます。これらのアラートログは、 lでオンまたはオフに切り替えることができます (小文字のL)キー、警告は wでクリアできます キー、アラートと警告はすべて xでクリアできます 。
Glancesの左側には、上では利用できない情報を表示する非常に優れたサイドバーがあります。 またはhtop 。 上の間 このデータの一部を表示します。Glancesはセンサーに関するデータを表示する唯一のモニターです。結局のところ、コンピュータ内部の温度を確認すると便利な場合があります。
個々のモジュール、ディスク、ファイルシステム、ネットワーク、センサーは、 dを使用してオンとオフを切り替えることができます 、 f 、 n 、および s それぞれキー。サイドバー全体は、 2を使用して切り替えることができます 。 Docker統計は、 Dを使用してサイドバーに表示できます 。
Glanceが仮想マシンで実行されている場合、ハードウェアセンサーは表示されないことに注意してください。
hを押すとヘルプが表示されます 鍵; h を押して、ヘルプページを閉じます また。ヘルプページはかなり簡潔ですが、利用可能なインタラクティブオプションとそれらのオンとオフを切り替える方法が示されています。マニュアルページには、Glanceを起動するときに使用できるオプションの簡潔な説明があります。
qを押すことができます またはEsc Glanceを終了します。
Glanceは、正しく機能するために構成ファイルを必要としません。 1つを選択した場合、構成ファイルのシステム全体のインスタンスは /etc/glances/glances.confにあります。 。個々のユーザーは、〜/.config/glances/glances.confにローカルインスタンスを持つことができます 、これはグローバル構成をオーバーライドします。これらの構成ファイルの主な目的は、警告と重大なアラートのしきい値を設定することです。特定のモジュールをデフォルトで表示するかどうかを指定することもできます。
ファイル/usr/local/share/doc/glances/README.rst オプションのGlance機能をサポートするためにインストールできるオプションのPythonモジュールなど、追加の有用な情報が含まれています。
Glancesは、特定の表示モードで起動できるようにするコマンドラインオプションを提供します。たとえば、コマンド glance -2 左側のサイドバーを無効にしてプログラムを開始します。
サーバーモードで起動すると、Glanceを使用してリモートホストを監視できます。
[root@testvm1 ~]# glances -sその後、次のコマンドを使用してクライアントからサーバーに接続できます。
[root@testvm2 ~]# glances -c @testvm1Glanceは、Glanceサーバーのリストとそのアクティビティの概要を表示できます。また、ブラウザからリモートGlanceサーバーを監視できるようにWebインターフェイスも備えています。 Glanceの最近のバージョンでは、Docker統計も表示できます。
基本プログラムでは利用できない測定データを提供するGlance用のプラグ可能なモジュールもあります。
Glanceはホストの多くの側面を監視できますが、プロセスを管理することはできません。 トップのように、プロセスの適切な数を変更したり、プロセスを強制終了したりすることはできません。 およびhtop できる。 Glancesはインタラクティブなツールではありません。厳密に監視に使用されます。 キルなどの外部ツール およびrenice プロセスの管理に使用できます。
Glanceは、使用可能なスペースで、CPU時間など、指定されたリソースの大部分を使用しているプロセスのみを表示できます。 10個のプロセスだけをリストする余地がある場合は、それだけを見ることができます。 Glancesには、上位Xプロセス以外を表示できるスクロールまたは逆ソートオプションはありません。
観察者効果は、「状況や現象を観察するだけで、必然的にその現象が変わる」という物理理論です。これは、Linuxシステムのパフォーマンスを測定する場合にも当てはまります。
監視ツールを使用するだけで、メモリやCPU時間などのシステムのリソース使用量が変わります。 トップ ユーティリティおよび他のほとんどのモニターは、システムのCPU時間のおそらく2%または3%を使用します。 Glancesユーティリティは、他のユーティリティよりもはるかに大きな影響を及ぼします。通常、CPU時間の10%から20%を使用し、32個のCPUを備えた非常に大規模でアクティブなシステムで1つのCPUの40%を使用することを確認しました。それはたくさんあるので、Glanceをモニターとして使用することを考えるときは、その影響を考慮してください。
私の個人的な意見では、これはGlanceの機能が必要なときに支払う小さな代償です。
renice する機能など、インタラクティブな機能がないにもかかわらず または殺す プロセスとその高いCPU負荷により、Glanceは非常に便利なツールであることがわかりました。完全なGlanceのドキュメントはインターネットで入手でき、Glanceのマニュアルページには起動オプションとインタラクティブなコマンド情報があります。
この記事の一部は、DavidBothの新しい本Usingand Administering Linux:Volume 2 – Zero to SysAdmin:AdvancedTopicsに基づいています。