Awkは、テキストファイルの処理または分析に使用されるスクリプト言語です。または、awkコマンドは主に、列またはフィールド、あるいは列のセットに基づいてデータをグループ化するために使用されると言えます。主に、便利な方法でデータをレポートするために使用されます。また、開始ブロックと終了ブロックを使用してデータを処理します。
AWKは「Aho、Weinberger、Kernighan」の略です
このチュートリアルでは、実際の例を使用してawkコマンドを学習します。
awkの構文
#awk‘pattern {action}’ input-file> output-file
次のデータを含む入力ファイルを取得しましょう
$ cat awk_file Name,Marks,Max Marks Ram,200,1000 Shyam,500,1000 Ghyansham,1000 Abharam,800,1000 Hari,600,1000 Ram,400,1000
それでは、awkコマンドの実際的な例を詳しく見ていきましょう。
1)ファイルからすべての行を印刷します
デフォルトでは、awkはファイルのすべての行を印刷するため、上記で作成したファイルのすべての行を印刷するには、以下のコマンドを使用します:
$ awk '{print;}' awk_file
Name,Marks,Max Marks
Ram,200,1000
Shyam,500,1000
Ghyansham,1000
Abharam,800,1000
Hari,600,1000
Ram,400,1000 注: awkコマンドでは、「{print;}」を使用して、すべてのフィールドとその値を出力します。
2)2番目と3番目のような特定のフィールドのみを印刷します
awkコマンドでは、$(ドル)記号の後にフィールド番号を使用して、フィールド値を出力します。以下の例では、フィールド2(つまりマーク)とフィールド3(つまり最大マーク)を印刷しています
$ awk -F "," '{print $2, $3;}' awk_file
Marks Max Marks
200 1000
500 1000
1000
800 1000
600 1000
400 1000 上記のコマンドでは、オプション-F "、"を使用しました。これは、カンマ(、)がファイルのフィールド区切り文字であることを指定します。
3)パターンに一致する線を印刷します
「Hari&Ram」という単語を含む行を印刷したいのですが、
$ awk '/Hari|Ram/' awk_file Ram,200,1000 Hari,600,1000 Ram,400,1000
4)名前の最初の列で一意の値を見つけるにはどうすればよいですか
最初の列から一意の値を出力するには、awkコマンドの下で実行します
$ awk -F, '{a[$1];}END{for (i in a)print i;}' awk_file
Abharam
Hari
Name
Ghyansham
Ram
Shyam 5)特定の列のデータ入力の合計を見つける方法
awkコマンドでは、検索に基づいて算術演算を実行することもできます。構文を以下に示します
$ awk -F、‘$ 1 ==” Item1″ {x + =$ 2;} END {print x}’ awk_file
次の例では、Ramを検索してから、Ramwordの2番目のフィールドの値を追加します。
$ awk -F, '$1=="Ram"{x+=$2;}END{print x}' awk_file
600 6)列内のすべての数値の合計を見つける方法
awkコマンドでは、ファイルの列にあるすべての数値の合計を計算することもできます。以下の例では、2列目と3列目のすべての数値の合計を計算しています。
$ awk -F"," '{x+=$2}END{print x}' awk_file
3500
$ awk -F"," '{x+=$3}END{print x}' awk_file
5000 7)個々のグループレコードの合計を見つける方法
たとえば、最初の列を検討する場合、アイテムに基づいて最初の列の合計を行うことができます
$ awk -F, '{a[$1]+=$2;}END{for(i in a)print i", "a[i];}' awk_file
Abharam, 800
Hari, 600
Name, 0
Ghyansham, 1000
Ram, 600
Shyam, 500 8)特定の列のすべてのエントリの合計を見つけて、ファイルの最後に追加します
awkコマンドは列のすべての数値の合計を実行できることをすでに説明したので、ファイルの最後に列2と列3の合計を追加するには、
を実行します。$ awk -F"," '{x+=$2;y+=$3;print}END{print "Total,"x,y}' awk_file
Name,Marks,Max Marks
Ram,200,1000
Shyam,500,1000
Ghyansham,1000
Abharam,800,1000
Hari,600,1000
Ram,400,1000
Total,3500 5000 9)最初の列に基づいてすべての列に対するエントリの数を見つける方法
$ awk -F, '{a[$1]++;}END{for (i in a)print i, a[i];}' awk_file
Abharam 1
Hari 1
Name 1
Ghyansham 1
Ram 2
Shyam 1 10)すべてのグループの最初のレコードのみを印刷する方法
すべてのグループの最初にのみ印刷するには、awkコマンドの下で実行します
$ awk -F, '!a[$1]++' awk_file Name,Marks,Max Marks Ram,200,1000 Shyam,500,1000 Ghyansham,1000 Abharam,800,1000 Hari,600,1000
AWK開始ブロック
BEGINブロックの構文は
です。
$awk「BEGIN{awk初期化コード}{実際のAWKコード}」ファイル名
以下の内容のデータファイルを作成しましょう
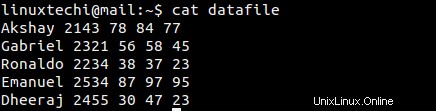
11)各列名とそれに対応するデータを入力する方法
$ awk 'BEGIN{print "Names\ttotal\tPPT\tDoc\txls"}{printf "%-s\t%d\t%d\t%d\t%d\n", $1,$2,$3,$4,$5}' datafile

12)フィールドセパレータの変更方法
スペースがデータファイルのフィールドセパレータであることがわかるように、次の例では、フィールドセパレータをスペースから「|」に変更します
$ awk 'BEGIN{OFS="|"}{print $1,$2,$3,$4,$5}' datafile

このチュートリアルは以上です。参考になると思います。以下のコメントのセクションでフィードバックや質問を共有してください。