Apache Hadoopは、MapReduceを使用したビッグデータの分散ストレージと処理のためにJavaで記述された無料のオープンソースソフトウェアフレームワークです。非常に大きなサイズのデータセットを大きなブロックに分割して処理し、クラスター内のコンピューター全体に分散します。
Hadoopモジュールは、標準のOSクラスターに依存するのではなく、アプリケーションレイヤーで障害を検出および管理するように設計されており、ソフトウェアレベルで高可用性サービスを提供します。
基本のHadoopフレームワークは、次のモジュールで構成されています。
- Hadoop Common –他のHadoopモジュールをサポートするためのライブラリとユーティリティの共通セットが含まれています
- Hadoop分散ファイルシステム(HDFS) –標準ハードウェアにデータを格納し、アプリケーションに非常に高いスループットを提供するJavaベースの分散ファイルシステム。
- Hadoop YARN –コンピューティングクラスター上のリソースを管理し、それらを使用してユーザーのアプリケーションをスケジュールします。
- Hadoop MapReduce –MapReduceプログラミングモデルに基づく大規模データ処理のフレームワーク。
この投稿では、RHEL8にApacheHadoopをインストールする方法を説明します。
前提条件
rootユーザーに切り替えます。
su-
または
sudo su-
Apache Hadoop v3.1.2はJavaバージョン8のみをサポートします。したがって、OpenJDK8またはOracleJDK8のいずれかをインストールします。
このデモでは、OpenJDK8を使用します。
yum -y install java-1.8.0-openjdk wget
Javaのバージョンを確認してください。
java -version
出力:
openjdkバージョン"1.8.0_201"OpenJDKランタイム環境(ビルド1.8.0_201-b09)OpenJDK 64ビットサーバーVM(ビルド25.201-b09、混合モード)
RHEL8にApacheHadoopをインストールする
Hadoopユーザーを作成する
通常のユーザーがApacheHadoopを実行することをお勧めします。そこで、ここでは、hadoopという名前のユーザーを作成し、そのユーザーのパスワードを設定します。
useradd -m -d / home / hadoop -s / bin / bash hadooppasswd hadoop
次に、以下の手順に従って、パスワードなしのsshをローカルシステムに設定します。
#su --hadoop $ ssh-keygen $ cat〜/ .ssh / id_rsa.pub>>〜/ .ssh / authorized_keys $ chmod 600〜/ .ssh / authorized_keys
ローカルシステムへのパスワードなしの通信を確認します。
$ ssh 127.0.0.1
出力:
初めてssh経由で接続する場合は、yesと入力して、既知のホストにRSAキーを追加する必要があります。
[hadoop @ rhel8〜] $ ssh 127.0.0.1ホスト「127.0.0.1(127.0.0.1)」の信頼性を確立できません。ECDSAキーフィンガープリントはSHA256:85jUAgtJg8RLOqs8T2egxF7U7IWIiYF+CRspO8yatAkです。接続を続行しますか(はい/いいえ)? はい 警告:既知のホストのリストに「127.0.0.1」(ECDSA)を恒久的に追加しました。次のコマンドでWebコンソールをアクティブ化します:systemctl enable --now cockpit.socket最終ログイン:Wed May 8 12:15:04 2019 from 127.0.0.1 [hadoop @ rhel8〜] $
Hadoopをダウンロード
Apache Hadoopページにアクセスして、Apache Hadoopの最新バージョンをダウンロードします(ドキュメントを確認して、本番環境に対応しているバージョンを常に選択してください)。または、ターミナルで次のコマンドを使用して、Hadoopv3.1.2をダウンロードできます。
$wgethttps://www-us.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz$tar-zxvfhadoop-3.1.2.tar。 gz $ mv hadoop-3.1.2 hadoop
Hadoopクラスタータイプ
Hadoopクラスターには次の3つのタイプがあります。
- ローカル(スタンドアロン)モード –単一のJavaプロセスとして実行されます。
- 疑似分散モード –各Hadoopデーモンは個別のプロセスとして実行されます。
- 完全分散モード –マルチノードクラスター。少数のノードから非常に大きなクラスターまで。
環境変数の設定
ここでは、Hadoopを疑似分散モードで構成します。まず、〜/.bashrcファイルに環境変数を設定します。
環境に応じて、ファイル内のJAVA_HOMEおよびHADOOP_HOME変数エントリを変更します。export JAVA_HOME = /usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.201.b09-2.el8.x86_64/ エクスポートHADOOP_HOME= / home / hadoop / hadoop export HADOOP_INSTALL =$ HADOOP_HOMEexport HADOOP_MAPRED_HOME =$ HADOOP_HOMEexport HADOOP_COMMON_HOME =$ HADOOP_HOMEexport HADOOP_HDFS_HOME =$ HADOOP_HOMEexport HADOOP_YARN_HOME =$ HADOOP_HOME> PATH / bin _現在のターミナルセッションに環境変数を適用します。
$ source〜/ .bashrcHadoopの構成
Hadoop環境ファイルを編集し、以下に示すように変数を更新します。
$ vi $ HADOOP_HOME / etc / hadoop / hadoop-env.sh環境に応じてJAVA_HOME変数を更新します。
export JAVA_HOME = /usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.201.b09-2.el8.x86_64/設定したクラスターモード(疑似分散)に応じて、Hadoopの構成ファイルを編集します。
$ cd $ HADOOP_HOME / etc / hadoopcore-site.xmlを編集し、HDFSホスト名でファイルを更新します。
fs.defaultFS hdfs:// rhel8.itzgeek.local :9000 hadoopユーザーのホーム/home/hadoopディレクトリの下にnamenodeディレクトリとdatanodeディレクトリを作成します。
$ mkdir -p〜/ hadoopdata / hdfs / {namenode、datanode}hdfs-site.xmlを編集し、NameNodeおよびDataNodeディレクトリ情報でファイルを更新します。
dfs.replication 1 dfs.name.dir file :// / home / hadoop / hadoopdata / hdfs / namenode dfs.data.dir file:// / home / hadoop / hadoopdata / hdfs / datanode mapred-site.xmlを編集します。
mapreduce.framework.name yarn ヤーンサイト.xmlを編集します。
yarn.nodemanager.aux-services mapreduce_shuffle 次のコマンドを使用してNameNodeをフォーマットします。
$ hdfs namenode -format出力:
。 。 ..。 .2019-05-13 19:33:14,720 INFO namenode.FSImage:割り当てられた新しいBlockPoolId:BP-1601223288-192.168.1.10-15577561946432019-05-13 19:33:15,100 INFO common.Storage:ストレージディレクトリ/ home / hadoop / hadoopdata / hdfs /namenodeは正常にフォーマットされました。2019-05-1319:33:15,436 INFO namenode.FSImageFormatProtobuf:圧縮なしで画像ファイル/home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000を保存しています2019-05- 13 19:33:16,804 INFO namenode.FSImageFormatProtobuf:画像ファイル/home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000サイズ393バイトが1秒で保存されました.2019-05-13 19:33:17,106 INFO namenode .NNStorageRetentionManager:txid> =02019-05-13 19:33:17,150 INFO namenode.NameNode:SHUTDOWN_MSG:/********************で1つの画像を保持します**************************************** SHUTDOWN_MSG:rhel8.itzgeekでNameNodeをシャットダウンします。ローカル/192.168.1.10********************************************* *************** /ファイアウォール
以下のコマンドを実行して、ファイアウォールを介したApacheHadoop接続を許可します。これらのコマンドをrootユーザーとして実行します。
Firewall-cmd --permanent --add-port =9870 / tcpfirewall-cmd --permanent --add-port =8088 / tcpfirewall-cmd --reloadHadoop&Yarnを開始
Hadoopが提供するスクリプトを使用して、NameNodeデーモンとDataNodeデーモンの両方を起動します。
$ start-dfs.sh出力:
[rhel8.itzgeek.local] rhel8.itzgeek.localでnamenodesを開始しています:警告:「rhel8.itzgeek.local、fe80 ::4480:83a5:c52:ea80%enp0s3」(ECDSA)のリストに永続的に追加されました既知のホスト。データノードの開始localhost:警告:既知のホストのリストに「localhost」(ECDSA)を永続的に追加しました。セカンダリネームノードの開始[rhel8.itzgeek.local] 2019-05-13 19:39:00,698警告util.NativeCodeLoader:できませんプラットフォームのnative-hadoopライブラリをロードします...該当する場合は組み込みのJavaクラスを使用しますブラウザを開き、以下のアドレスに移動してNamenodeにアクセスします。
http://ip.ad.dre.ss:9870/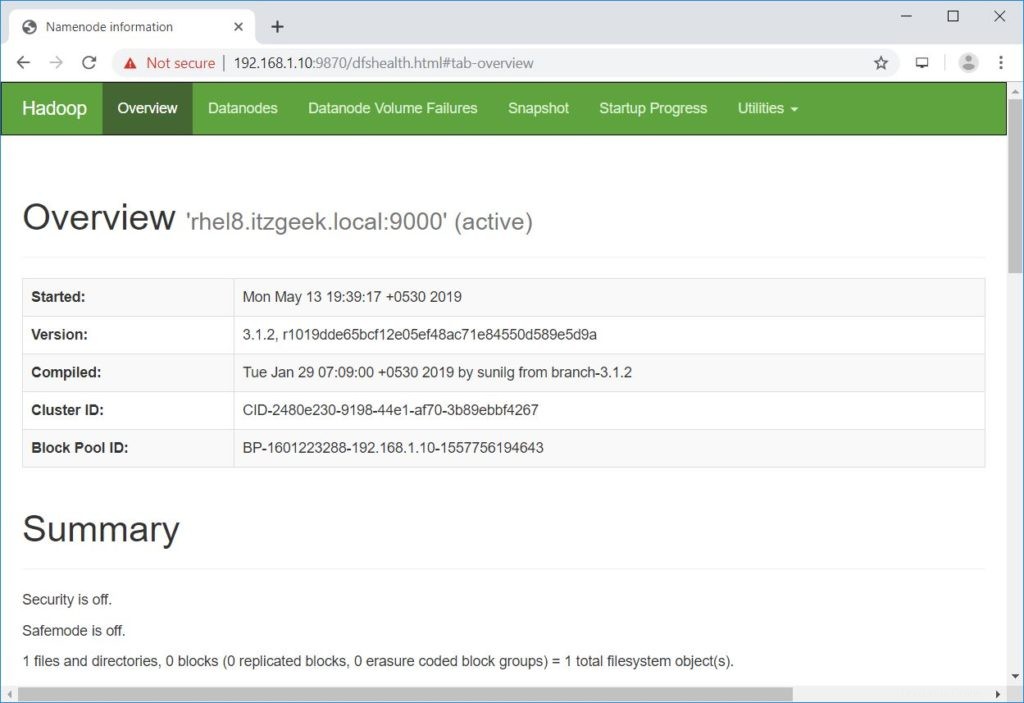
ResourceManagerとNodeManagerを起動します。
$ start-yarn.sh出力:
resourcemanagerの開始nodemanagersの開始ブラウザを開き、以下のアドレスに移動してResourceManagerにアクセスします。
http://ip.ad.dre.ss:8088/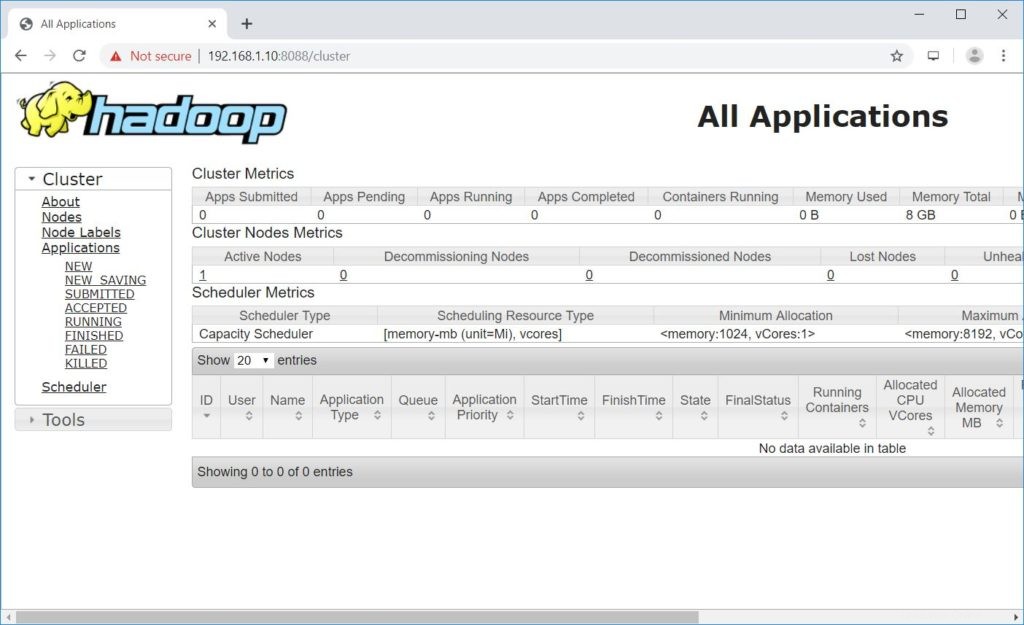
ApacheHadoopのテスト
次に、サンプルファイルをアップロードしてApacheHadoopをテストします。ファイルをHDFSにアップロードする前に、HDFSにディレクトリを作成してください。
$ hdfs dfs -mkdir / raj作成したディレクトリがHDFSに存在することを確認します。
hdfs dfs -ls /出力:
1つのアイテムが見つかりましたdrwxr-xr-x-hadoopスーパーグループ02019-05-0813:20 / raj次のコマンドを使用して、ファイルをHDFSディレクトリrajにアップロードします。
$ hdfs dfs -put〜/ .bashrc / rajアップロードされたファイルは、以下のコマンドを実行して表示できます。
$ hdfs dfs -ls / rajまたは
NameNodeに移動します>>ユーティリティ>>ファイルシステムを参照 NameNode内。
http://ip.ad.dre.ss:9870/explorer.html#/raj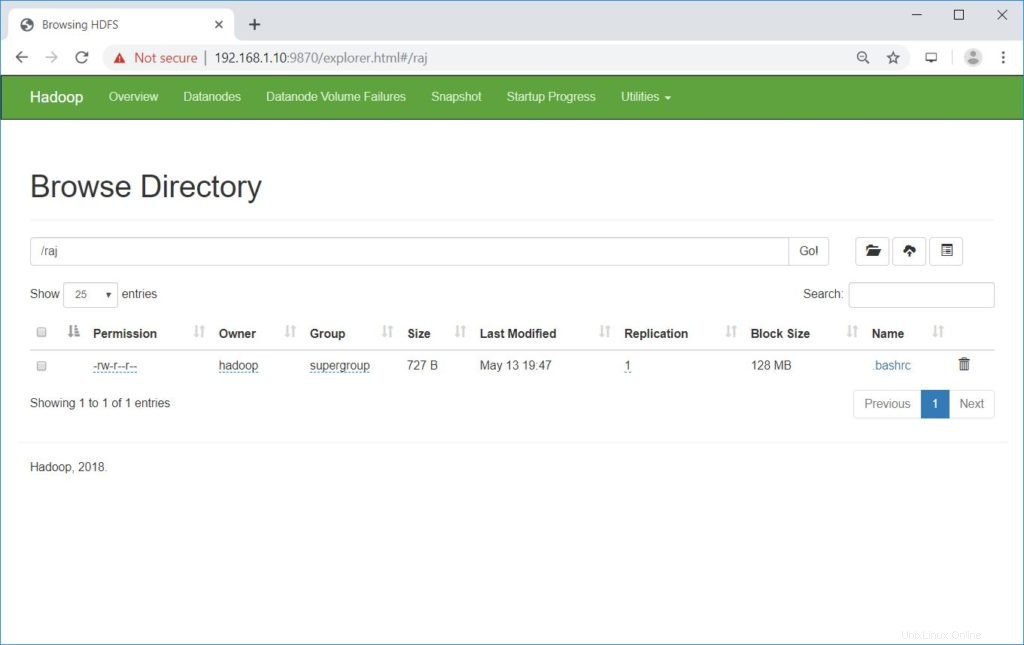
以下のコマンドを使用して、HDFSからローカルファイルシステムにファイルをコピーできます。
$ hdfs dfs -get / raj / tmp /必要に応じて、次のコマンドを使用してHDFSのファイルとディレクトリを削除できます。
$ hdfs dfs -rm -f /raj/.bashrc$ hdfs dfs -rmdir / raj結論
この投稿が、RHEL8に単一ノードのApacheHadoopクラスターをインストールして構成するのに役立つことを願っています。詳細については、Hadoopの公式ドキュメントを参照してください。コメントセクションでフィードバックを共有してください。
Cent OS