Apache Hadoopは、コモディティハードウェアで実行されるコンピューターのクラスターでのビッグデータの分散処理だけでなく、分散ストレージにも使用されるオープンソースフレームワークです。 HadoopはデータをHadoop分散ファイルシステム(HDFS)に保存し、これらのデータの処理はMapReduceを使用して行われます。 YARNは、Hadoopクラスター内のリソースをリクエストおよび割り当てるためのAPIを提供します。
Apache Hadoopフレームワークは、次のモジュールで構成されています。
- Hadoop Common
- Hadoop分散ファイルシステム(HDFS)
- YARN
- MapReduce
この記事では、Hadoopバージョン2をRHEL8またはCentOS8にインストールする方法について説明します。HDFS(NamenodeおよびDatanode)、YARN、MapReduceを、単一マシンでの分散シミュレーションである疑似分散モードの単一ノードクラスターにインストールします。 hdfs、yarn、mapreduceなどの各Hadoopデーモンは、個別の/個別のJavaプロセスとして実行されます。
このチュートリアルでは、次のことを学びます。
- Hadoop環境のユーザーを追加する方法
- OracleJDKをインストールおよび構成する方法
- パスワードなしのSSHを構成する方法
- Hadoopをインストールし、必要な関連xmlファイルを構成する方法
- Hadoopクラスターを開始する方法
- NameNodeおよびResourceManagerWebUIにアクセスする方法
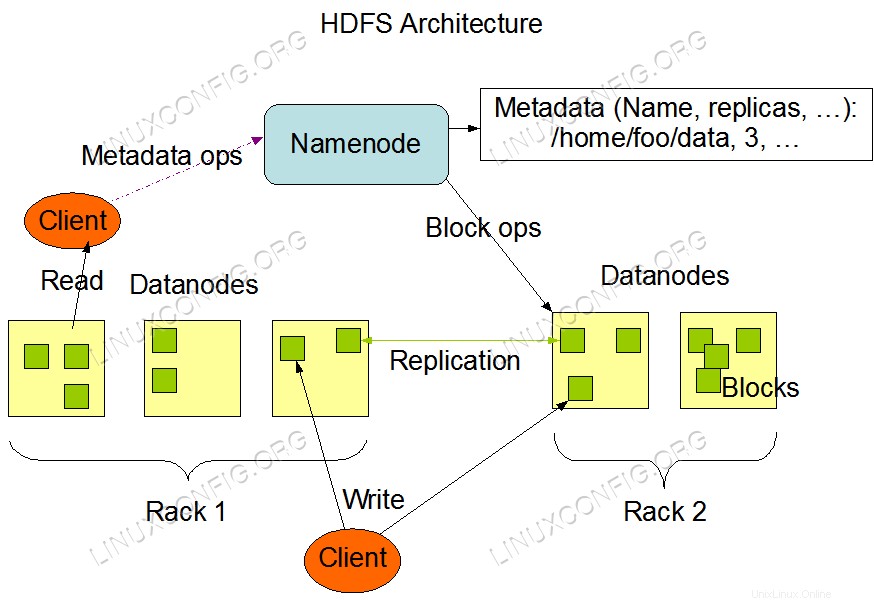 HDFSアーキテクチャ。
HDFSアーキテクチャ。 使用されるソフトウェア要件と規則
| カテゴリ | 使用する要件、規則、またはソフトウェアバージョン |
|---|---|
| RHEL 8 / CentOS 8 | |
| Hadoop 2.8.5、Oracle JDK 1.8 | |
rootまたはsudoを介したLinuxシステムへの特権アクセス コマンド。 | |
# –指定されたLinuxコマンドは、rootユーザーとして直接、またはsudoを使用して、root権限で実行する必要があります。 コマンド$ –特定のLinuxコマンドを通常の非特権ユーザーとして実行する必要があります |
Hadoop環境のユーザーを追加
次のコマンドを使用して、新しいユーザーとグループを作成します。
# useradd hadoop # passwd hadoop
[root@hadoop ~]# useradd hadoop [root@hadoop ~]# passwd hadoop Changing password for user hadoop. New password: Retype new password: passwd: all authentication tokens updated successfully. [root@hadoop ~]# cat /etc/passwd | grep hadoop hadoop:x:1000:1000::/home/hadoop:/bin/bash
OracleJDKのインストールと構成
jdk-8u202-linux-x64.rpm公式パッケージをダウンロードしてインストールし、OracleJDKをインストールします。
[root@hadoop ~]# rpm -ivh jdk-8u202-linux-x64.rpm
warning: jdk-8u202-linux-x64.rpm: Header V3 RSA/SHA256 Signature, key ID ec551f03: NOKEY
Verifying... ################################# [100%]
Preparing... ################################# [100%]
Updating / installing...
1:jdk1.8-2000:1.8.0_202-fcs ################################# [100%]
Unpacking JAR files...
tools.jar...
plugin.jar...
javaws.jar...
deploy.jar...
rt.jar...
jsse.jar...
charsets.jar...
localedata.jar...
インストール後、Javaが正常に構成されていることを確認したら、次のコマンドを実行します。
[root@hadoop ~]# java -version java version "1.8.0_202" Java(TM) SE Runtime Environment (build 1.8.0_202-b08) Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode) [root@hadoop ~]# update-alternatives --config java There is 1 program that provides 'java'. Selection Command ----------------------------------------------- *+ 1 /usr/java/jdk1.8.0_202-amd64/jre/bin/java
パスワードなしのSSHを構成する
OpenSSHサーバーとOpenSSHクライアントをインストールするか、すでにインストールされている場合は、以下のパッケージが一覧表示されます。
[root@hadoop ~]# rpm -qa | grep openssh* openssh-server-7.8p1-3.el8.x86_64 openssl-libs-1.1.1-6.el8.x86_64 openssl-1.1.1-6.el8.x86_64 openssh-clients-7.8p1-3.el8.x86_64 openssh-7.8p1-3.el8.x86_64 openssl-pkcs11-0.4.8-2.el8.x86_64
次のコマンドを使用して、公開鍵と秘密鍵のペアを生成します。端末はファイル名の入力を求めるプロンプトを表示します。 ENTERを押します 続行します。その後、公開鍵をid_rsa.pubからコピーします。 authorized_keysへ 。
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 640 ~/.ssh/authorized_keys
[hadoop@hadoop ~]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: SHA256:H+LLPkaJJDD7B0f0Je/NFJRP5/FUeJswMmZpJFXoelg hadoop@hadoop.sandbox.com The key's randomart image is: +---[RSA 2048]----+ | .. ..++*o .o| | o .. +.O.+o.+| | + . . * +oo==| | . o o . E .oo| | . = .S.* o | | . o.o= o | | . .. o | | .o. | | o+. | +----[SHA256]-----+ [hadoop@hadoop ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys [hadoop@hadoop ~]$ chmod 640 ~/.ssh/authorized_keys
次のコマンドを使用して、パスワードなしのssh構成を確認します:
$ ssh
[hadoop@hadoop ~]$ ssh hadoop.sandbox.com Web console: https://hadoop.sandbox.com:9090/ or https://192.168.1.108:9090/ Last login: Sat Apr 13 12:09:55 2019 [hadoop@hadoop ~]$
Hadoopをインストールし、関連するxmlファイルを構成します
Apacheの公式WebサイトからHadoop2.8.5をダウンロードして抽出します。
# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz # tar -xzvf hadoop-2.8.5.tar.gz
[root@rhel8-sandbox ~]# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz --2019-04-13 11:14:03-- https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz Resolving archive.apache.org (archive.apache.org)... 163.172.17.199 Connecting to archive.apache.org (archive.apache.org)|163.172.17.199|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 246543928 (235M) [application/x-gzip] Saving to: ‘hadoop-2.8.5.tar.gz’ hadoop-2.8.5.tar.gz 100%[=====================================================================================>] 235.12M 1.47MB/s in 2m 53s 2019-04-13 11:16:57 (1.36 MB/s) - ‘hadoop-2.8.5.tar.gz’ saved [246543928/246543928]
環境変数の設定
bashrcを編集します 次のHadoop環境変数を設定することによるHadoopユーザーの場合:
export HADOOP_HOME=/home/hadoop/hadoop-2.8.5
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
.bashrcを入手する 現在のログインセッションで。
$ source ~/.bashrc
hadoop-env.shを編集します /etc/hadoopにあるファイル Hadoopインストールディレクトリ内で次の変更を行い、他の構成を変更するかどうかを確認します。
export JAVA_HOME=${JAVA_HOME:-"/usr/java/jdk1.8.0_202-amd64"}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/home/hadoop/hadoop-2.8.5/etc/hadoop"}
core-site.xmlファイルの構成変更
core-site.xmlを編集します vimを使用するか、任意のエディターを使用できます。ファイルは/etc/hadoopの下にあります hadoopの内部 ホームディレクトリに移動し、次のエントリを追加します。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop.sandbox.com:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadooptmpdata</value>
</property>
</configuration>
さらに、hadoopの下にディレクトリを作成します ホームフォルダ。
$ mkdir hadooptmpdata
hdfs-site.xmlファイルの構成変更
hdfs-site.xmlを編集します これは同じ場所、つまり/etc/hadoopの下にあります hadoopの内部 インストールディレクトリを作成し、Namenode/Datanodeを作成します hadoopの下のディレクトリ ユーザーのホームディレクトリ。
$ mkdir -p hdfs/namenode $ mkdir -p hdfs/datanode
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
mapred-site.xmlファイルの構成変更
mapred-site.xmlをコピーします mapred-site.xml.templateから cpを使用する コマンドを実行してから、mapred-site.xmlを編集します /etc/hadoopに配置 hadoopの下 以下の変更を加えた点滴ディレクトリ。
$ cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xmlファイルの構成変更
yarn-site.xmlを編集します 次のエントリを使用します。
<configuration>
<property>
<name>mapreduceyarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Hadoopクラスターの開始
初めて使用する前に、namenodeをフォーマットしてください。 hadoopユーザーとして、以下のコマンドを実行してNamenodeをフォーマットします。
$ hdfs namenode -format
[hadoop@hadoop ~]$ hdfs namenode -format 19/04/13 11:54:10 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: user = hadoop STARTUP_MSG: host = hadoop.sandbox.com/192.168.1.108 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.8.5 19/04/13 11:54:17 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 19/04/13 11:54:17 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0 19/04/13 11:54:17 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000 19/04/13 11:54:18 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 19/04/13 11:54:18 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 19/04/13 11:54:18 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 19/04/13 11:54:18 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 19/04/13 11:54:18 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 19/04/13 11:54:18 INFO util.GSet: Computing capacity for map NameNodeRetryCache 19/04/13 11:54:18 INFO util.GSet: VM type = 64-bit 19/04/13 11:54:18 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB 19/04/13 11:54:18 INFO util.GSet: capacity = 2^15 = 32768 entries 19/04/13 11:54:18 INFO namenode.FSImage: Allocated new BlockPoolId: BP-415167234-192.168.1.108-1555142058167 19/04/13 11:54:18 INFO common.Storage: Storage directory /home/hadoop/hdfs/namenode has been successfully formatted. 19/04/13 11:54:18 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 19/04/13 11:54:18 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 323 bytes saved in 0 seconds. 19/04/13 11:54:18 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 19/04/13 11:54:18 INFO util.ExitUtil: Exiting with status 0 19/04/13 11:54:18 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop.sandbox.com/192.168.1.108 ************************************************************/
Namenodeがフォーマットされたら、start-dfs.shを使用してHDFSを開始します。 スクリプト。
$ start-dfs.sh
[hadoop@hadoop ~]$ start-dfs.sh Starting namenodes on [hadoop.sandbox.com] hadoop.sandbox.com: starting namenode, logging to /home/hadoop/hadoop-2.8.5/logs/hadoop-hadoop-namenode-hadoop.sandbox.com.out hadoop.sandbox.com: starting datanode, logging to /home/hadoop/hadoop-2.8.5/logs/hadoop-hadoop-datanode-hadoop.sandbox.com.out Starting secondary namenodes [0.0.0.0] The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established. ECDSA key fingerprint is SHA256:e+NfCeK/kvnignWDHgFvIkHjBWwghIIjJkfjygR7NkI. Are you sure you want to continue connecting (yes/no)? yes 0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts. hadoop@0.0.0.0's password: 0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.8.5/logs/hadoop-hadoop-secondarynamenode-hadoop.sandbox.com.out
YARNサービスを開始するには、yarn startスクリプト(start-yarn.sh)を実行する必要があります。
$ start-yarn.sh
[hadoop@hadoop ~]$ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.8.5/logs/yarn-hadoop-resourcemanager-hadoop.sandbox.com.out hadoop.sandbox.com: starting nodemanager, logging to /home/hadoop/hadoop-2.8.5/logs/yarn-hadoop-nodemanager-hadoop.sandbox.com.outにログインします
すべてのHadoopサービス/デーモンが正常に開始されたことを確認するには、jpsを使用できます。 コマンド。
$ jps 2033 NameNode 2340 SecondaryNameNode 2566 ResourceManager 2983 Jps 2139 DataNode 2671 NodeManager
これで、以下のコマンドで使用できる現在のHadoopバージョンを確認できます:
$ hadoop version
または
$ hdfs version
[hadoop@hadoop ~]$ hadoop version Hadoop 2.8.5 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8 Compiled by jdu on 2018-09-10T03:32Z Compiled with protoc 2.5.0 From source with checksum 9942ca5c745417c14e318835f420733 This command was run using /home/hadoop/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.jar [hadoop@hadoop ~]$ hdfs version Hadoop 2.8.5 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8 Compiled by jdu on 2018-09-10T03:32Z Compiled with protoc 2.5.0 From source with checksum 9942ca5c745417c14e318835f420733 This command was run using /home/hadoop/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.jar [hadoop@hadoop ~]$
HDFSコマンドラインインターフェイス
HDFSにアクセスし、DFSの最上位にいくつかのディレクトリを作成するには、HDFSCLIを使用できます。
$ hdfs dfs -mkdir /testdata $ hdfs dfs -mkdir /hadoopdata $ hdfs dfs -ls /
[hadoop@hadoop ~]$ hdfs dfs -ls / Found 2 items drwxr-xr-x - hadoop supergroup 0 2019-04-13 11:58 /hadoopdata drwxr-xr-x - hadoop supergroup 0 2019-04-13 11:59 /testdata
ブラウザからNamenodeとYARNにアクセスする
NameNodeのWebUIとYARNResourceManagerの両方に、Google Chrome /MozillaFirefoxなどのブラウザからアクセスできます。
Namenode Web UI – http://<hadoop cluster hostname/IP address>:50070
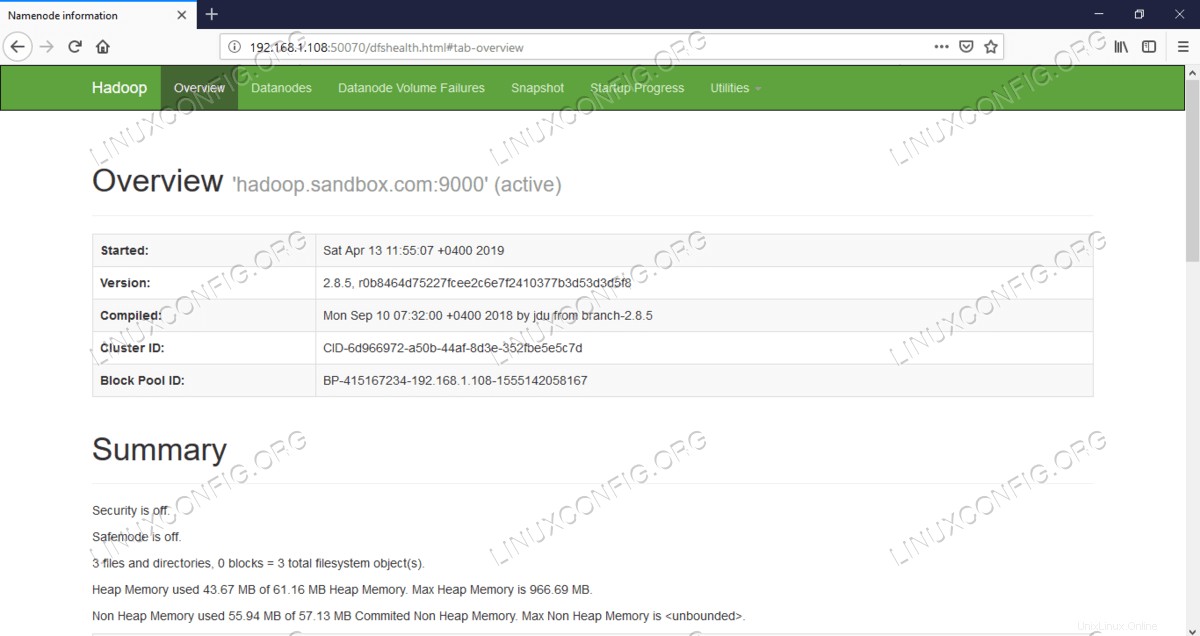 NamenodeWebユーザーインターフェイス。
NamenodeWebユーザーインターフェイス。 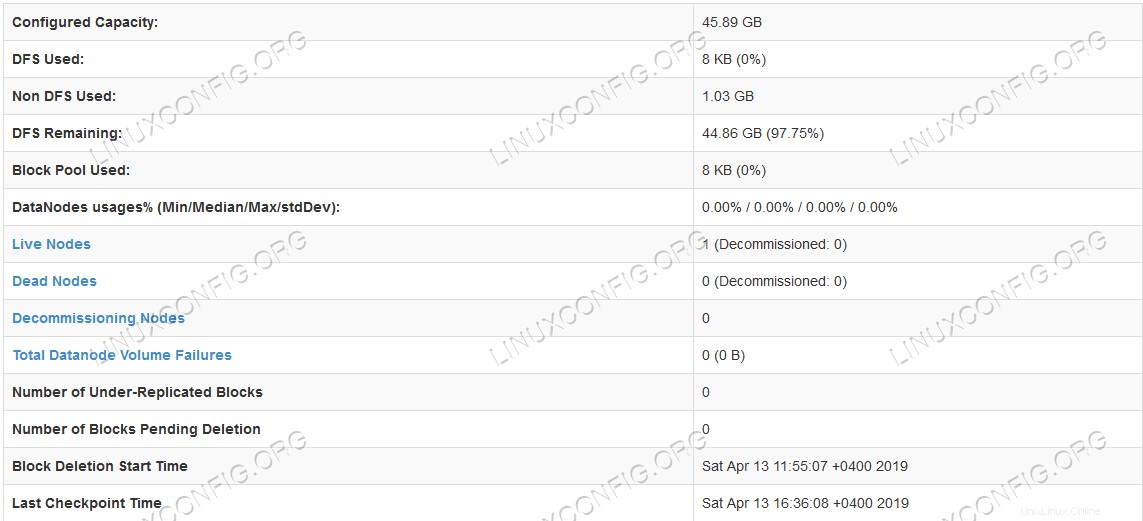 HDFS詳細情報。
HDFS詳細情報。 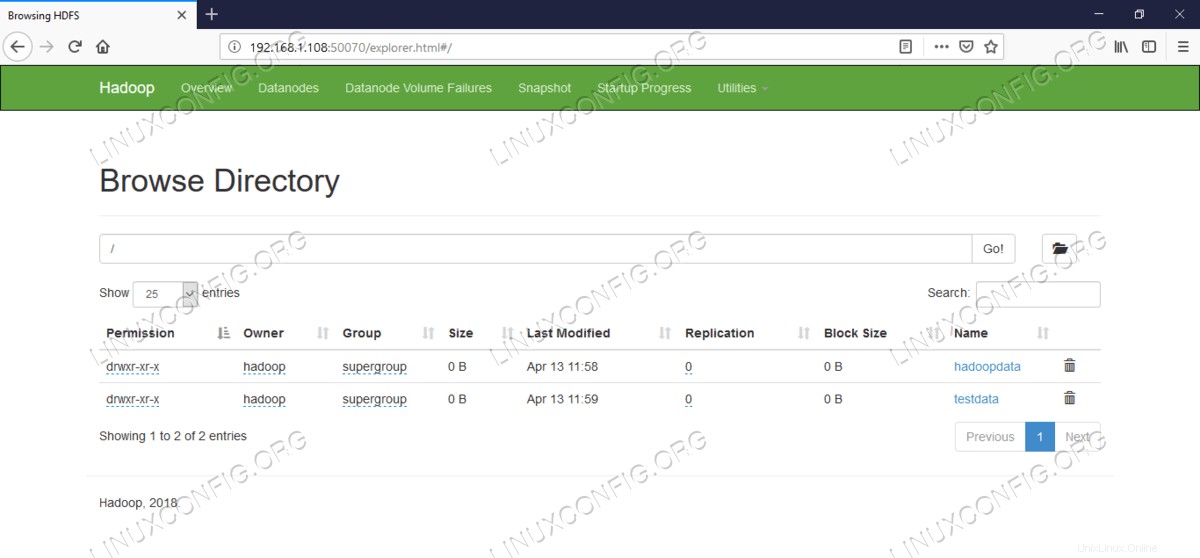 HDFSディレクトリの閲覧。
HDFSディレクトリの閲覧。 YARN Resource Manager(RM)Webインターフェースは、現在のHadoopクラスターで実行中のすべてのジョブを表示します。
Resource Manager Web UI – http://<hadoop cluster hostname/IP address>:8088
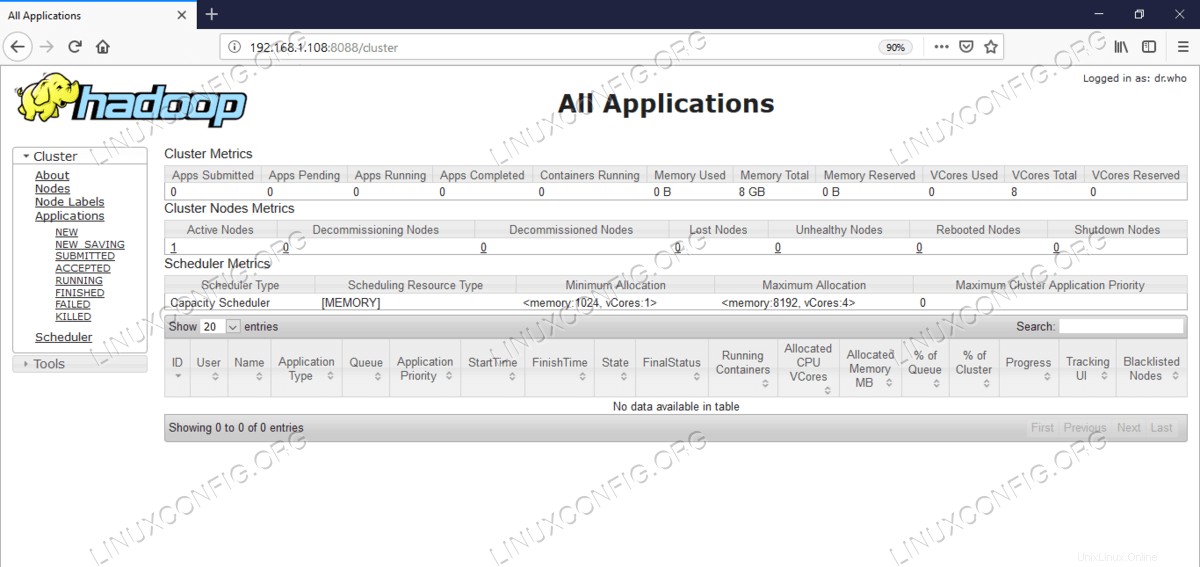 Resource Manager(YARN)Webユーザーインターフェイス。
Resource Manager(YARN)Webユーザーインターフェイス。 結論
世界は現在の運営方法を変えており、ビッグデータはこのフェーズで主要な役割を果たしています。 Hadoopは、大量のデータセットで作業しているときにlifを簡単にするフレームワークです。すべての面で改善があります。未来はエキサイティングです。