
このチュートリアルでは、Debian11にApacheSparkをインストールする方法を紹介します。知らない人のために、ApacheSparkは無料のオープンソースの汎用です。クラスターコンピューティング用のフレームワーク。速度を上げるために特別に設計されており、複雑なSQLクエリに処理をストリーミングするための機械学習で使用されます。Java、Python、Scala、Rなどのストリーミング、グラフ処理用のいくつかのAPIをサポートしています。Sparkは主ににインストールされています。 Hadoopクラスターですが、スタンドアロンモードでsparkをインストールして構成することもできます。
この記事は、少なくともLinuxの基本的な知識があり、シェルの使用方法を知っていること、そして最も重要なこととして、サイトを独自のVPSでホストしていることを前提としています。インストールは非常に簡単で、ルートアカウントで実行されていますが、そうでない場合は、'sudoを追加する必要があります。 ルート権限を取得するコマンドに‘。 Debian 11(Bullseye)にApacheSparkを段階的にインストールする方法を紹介します。
前提条件
- 次のオペレーティングシステムのいずれかを実行しているサーバー:Debian 11(Bullseye)。
- 潜在的な問題を防ぐために、OSの新規インストールを使用することをお勧めします。
non-root sudo userまたはroot userへのアクセス 。non-root sudo userとして行動することをお勧めします ただし、ルートとして機能するときに注意しないと、システムに害を及ぼす可能性があるためです。
Debian11BullseyeにApacheSparkをインストールする
ステップ1.ソフトウェアをインストールする前に、次のaptを実行して、システムが最新であることを確認することが重要です。 ターミナルのコマンド:
sudo apt update sudo apt upgrade
ステップ2.Javaをインストールします。
以下のコマンドを実行して、Javaおよびその他の依存関係をインストールします。
sudo apt install default-jdk scala git
次のコマンドを使用してJavaのインストールを確認します:
java --version
ステップ3.Debian11にApacheSparkをインストールします。
次に、wgetを使用して公式ページから最新バージョンのApacheSparkをダウンロードします。 コマンド:
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
次に、ダウンロードしたファイルを抽出します:
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz mv spark-3.1.2-bin-hadoop3.2/ /opt/spark
その後、~/.bashrcを編集します ファイルを作成し、Sparkパス変数を追加します:
nano ~/.bashrc
次の行を追加します:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
ファイルを保存して閉じてから、以下のコマンドを使用してSpark環境変数をアクティブにします。
source ~/.bashrc
ステップ3.ApacheSparkマスターサーバーを起動します。
この時点で、Apache Sparkがインストールされています。次に、スクリプトを実行してスタンドアロンマスターサーバーを起動しましょう:
start-master.sh
デフォルトでは、Apache Sparkはポート8080でリッスンします。次のコマンドで確認できます:
ss -tunelp | grep 8080
ステップ4.ApacheSparkWebインターフェースへのアクセス。
正常に構成されたら、URL http://your-server-ip-address:8080を使用してApacheSparkWebインターフェースにアクセスします。 。次の画面にApacheSparkマスターおよびスレーブサービスが表示されます。
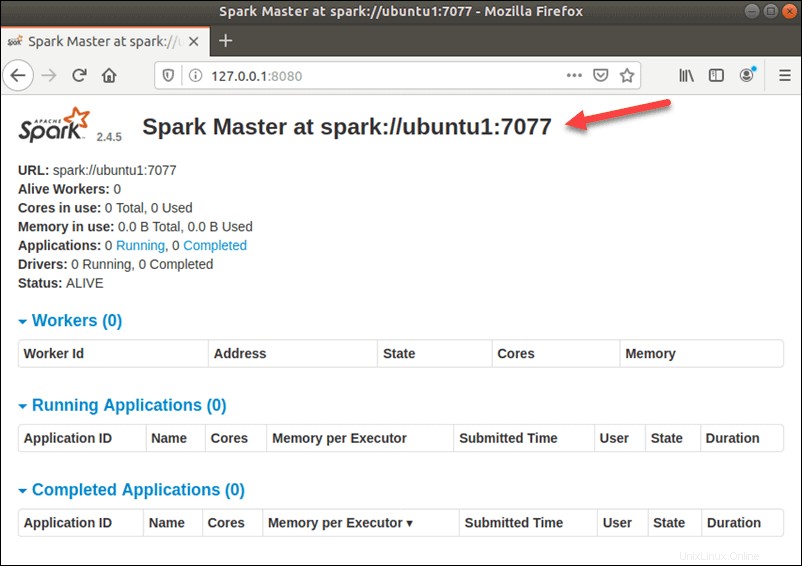
この単一サーバーのスタンドアロンセットアップでは、マスターサーバーとともに1つのスレーブサーバーを起動します。start-slave.sh このコマンドは、Sparkワーカープロセスを開始するために使用されます:
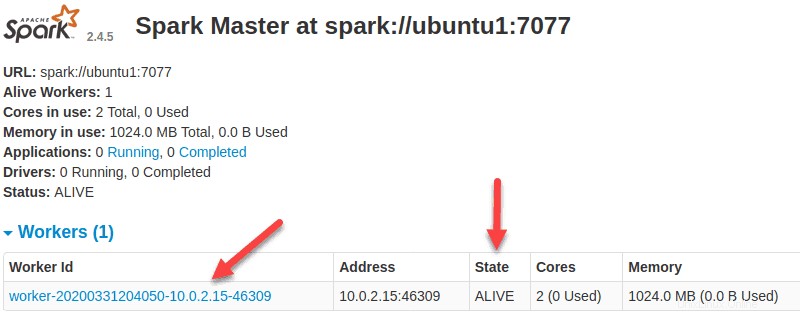
start-slave.sh spark://ubuntu1:7077
これでワーカーが稼働しているので、SparkMasterのWebUIをリロードすると、リストに表示されます。
構成が完了したら、マスターサーバーとスレーブサーバーを起動し、Sparkシェルが機能するかどうかをテストします。
spark-shell
次のインターフェースが表示されます:
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala> おめでとうございます!ApacheSparkが正常にインストールされました。Debian11Bullseyeに最新バージョンのApacheSparkをインストールするためにこのチュートリアルを使用していただきありがとうございます。追加のヘルプや役立つ情報については、公式を確認することをお勧めしますApacheSparkのWebサイト。