はじめに
Apache Sparkは、ビッグデータを分析するためにクラスターコンピューティング環境で使用されるフレームワークです。 。このプラットフォームは、その使いやすさとHadoopよりも優れたデータ処理速度により、広く普及しました。
Apache Sparkは、クラスター内のコンピューターのグループ全体にワークロードを分散して、大量のデータセットをより効果的に処理することができます。このオープンソースエンジン 幅広いプログラミング言語をサポートします。これには、Java、Scala、Python、およびRが含まれます。
このチュートリアルでは、UbuntuマシンにSparkをインストールする方法を学習します。 。このガイドでは、マスターサーバーとスレーブサーバーを起動する方法と、ScalaシェルとPythonシェルをロードする方法を説明します。また、最も重要なSparkコマンドも提供します。

前提条件
- Ubuntuシステム。
- 端末またはコマンドラインへのアクセス。
- sudoまたはrootを持つユーザー 権限。
Sparkに必要なパッケージのインストール
Sparkをダウンロードして設定する前に、必要な依存関係をインストールする必要があります。この手順には、次のパッケージのインストールが含まれます。
- JDK
- Scala
- Git
ターミナルウィンドウを開き、次のコマンドを実行して、3つのパッケージすべてを一度にインストールします。
sudo apt install default-jdk scala git -yインストールされるパッケージが表示されます。
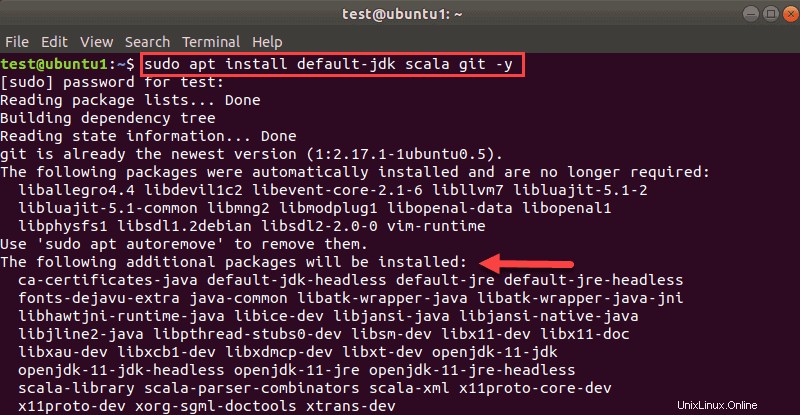
プロセスが完了したら、インストールされている依存関係を確認します 次のコマンドを実行します:
java -version; javac -version; scala -version; git --version
すべてのパッケージのインストールが正常に完了した場合、出力にバージョンが出力されます。
UbuntuでSparkをダウンロードしてセットアップする
ここで、必要なバージョンのSparkをダウンロードする必要があります 彼らのウェブサイトを形成します。 Spark 3.0.1に行きます Hadoop 2.7 この記事を書いている時点での最新バージョンです。
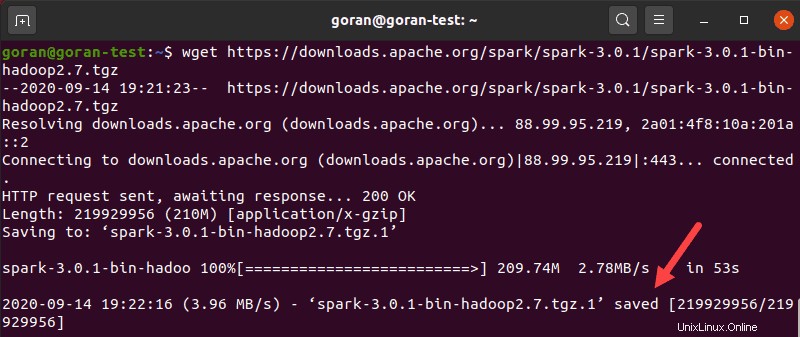
wgetを使用する コマンドとSparkアーカイブをダウンロードするための直接リンク:
wget https://downloads.apache.org/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgzダウンロードが完了すると、保存済みが表示されます メッセージ。
次に、tarを使用して保存したアーカイブを抽出します:
tar xvf spark-*プロセスを完了させます。出力には、アーカイブから解凍されているファイルが表示されます。
最後に、解凍したディレクトリ spark-3.0.1-bin-hadoop2.7を移動します opt / spark ディレクトリ。
mvを使用する そうするためのコマンド:
sudo mv spark-3.0.1-bin-hadoop2.7 /opt/sparkディレクトリの移動に成功した場合、端末は応答を返しません。名前を間違えると、次のようなメッセージが表示されます。
mv: cannot stat 'spark-3.0.1-bin-hadoop2.7': No such file or directory.Spark環境の構成
マスターサーバーを起動する前に、環境変数を構成する必要があります。ユーザープロファイルに追加する必要のあるSparkホームパスがいくつかあります。
echoを使用する これらの3行を.profileに追加するコマンド :
echo "export SPARK_HOME=/opt/spark" >> ~/.profile
echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.profile
echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile.profile を編集して、エクスポートパスを追加することもできます。 nanoやvimなど、選択したエディターでファイルを作成します。
たとえば、nanoを使用するには、次のように入力します。
nano .profileプロファイルが読み込まれたら、ファイルの一番下までスクロールします。
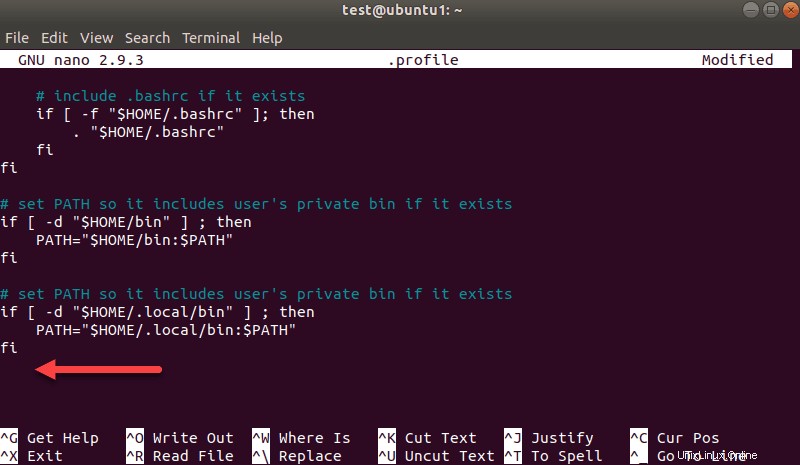
次に、次の3行を追加します。
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/usr/bin/python3プロンプトが表示されたら、終了して変更を保存します。
パスの追加が完了したら、 .profileをロードします 次のように入力して、コマンドラインでファイルを作成します。
source ~/.profileスタンドアロンSparkマスターサーバーを起動します
Sparkの環境の構成が完了したので、マスターサーバーを起動できます。
ターミナルで次のように入力します:
start-master.shSpark Webユーザーインターフェイスを表示するには、Webブラウザーを開き、ポート8080にローカルホストIPアドレスを入力します。
http://127.0.0.1:8080/このページには、スパークURLが表示されます 、ワーカーのステータス情報、ハードウェアリソースの使用率など。
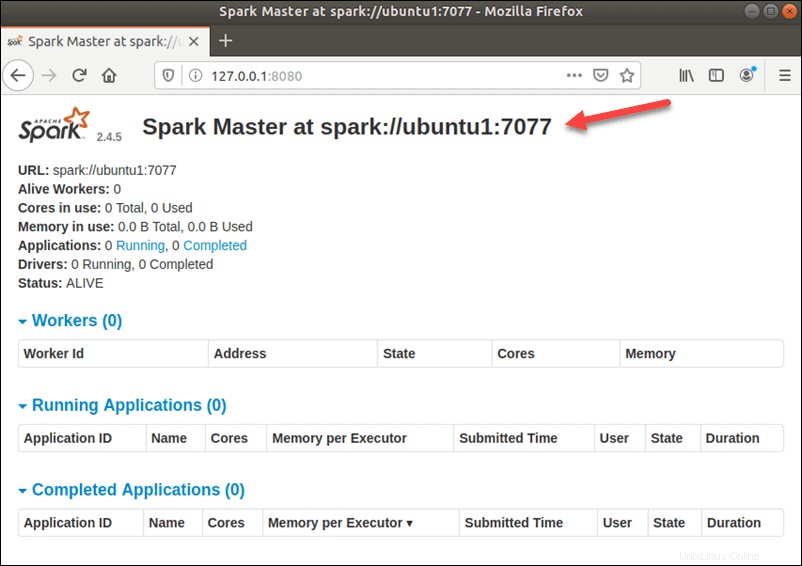
Spark MasterのURLは、ポート8080のデバイスの名前です。この場合、これは ubuntu1:8080 です。 。したがって、SparkMasterのWebUIをロードする方法は3つあります。
- 127.0.0.1:8080
- localhost:8080
- deviceName :8080
Spark Slave Serverを起動します(ワーカープロセスを開始します)
この単一サーバーのスタンドアロンセットアップでは、マスターサーバーとともに1台のスレーブサーバーを起動します。
これを行うには、次のコマンドをこの形式で実行します。
start-slave.sh spark://master:port
master コマンド内のIPまたはホスト名を指定できます。
私たちの場合はubuntu1 :
start-slave.sh spark://ubuntu1:7077
ワーカーが稼働しているので、SparkMasterのWebUIをリロードすると、リストに表示されます。
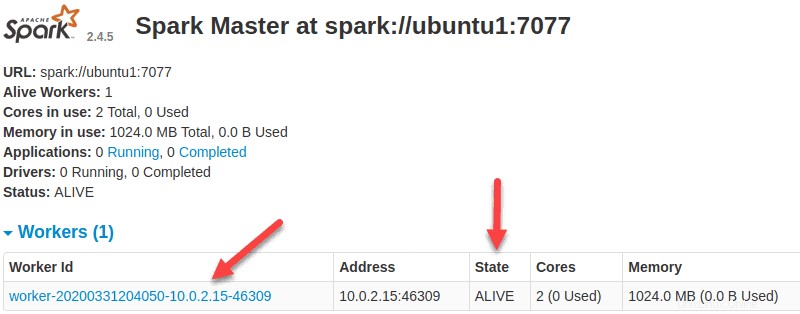
ワーカーのリソース割り当てを指定する
マシンでワーカーを起動するときのデフォルト設定は、使用可能なすべてのCPUコアを使用することです。 -cを渡すことで、コアの数を指定できます start-slaveへのフラグ コマンド。
たとえば、ワーカーを起動して1つのCPUコアのみを割り当てる これに、次のコマンドを入力します:
start-slave.sh -c 1 spark://ubuntu1:7077SparkMasterのWebUIをリロードして、ワーカーの構成を確認します。

同様に、ワーカーを起動するときに特定の量のメモリを割り当てることができます。デフォルト設定では、マシンに搭載されているRAMの量から1GBを引いた量を使用します。
ワーカーを起動して特定のメモリ量を割り当てるには、 -mを追加します オプションと番号。ギガバイトの場合は、 Gを使用します メガバイトの場合は、 Mを使用します 。
たとえば、512MBのメモリでワーカーを起動するには、次のコマンドを入力します。
start-slave.sh -m 512M spark://ubuntu1:7077Spark Master Web UIをリロードして、ワーカーのステータスを表示し、構成を確認します。

スパークシェルのテスト
構成を完了し、マスターサーバーとスレーブサーバーを起動したら、Sparkシェルが機能するかどうかをテストします。
次のように入力してシェルをロードします:
spark-shell通知とSpark情報が表示された画面が表示されます。 Scalaはデフォルトのインターフェースであるため、 spark-shellを実行するとシェルが読み込まれます 。
このガイドを書いている時点で使用しているバージョンの出力の終わりは次のようになります:
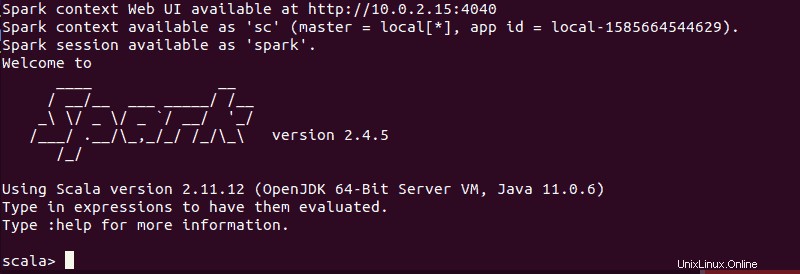
:qと入力します Enterを押します Scalaを終了します。
SparkでPythonをテストする
デフォルトのScalaインターフェースを使用したくない場合は、Pythonに切り替えることができます。
必ずScalaを終了してから、次のコマンドを実行してください:
pyspark結果の出力は、前の出力と同様になります。下部に、Pythonのバージョンが表示されます。
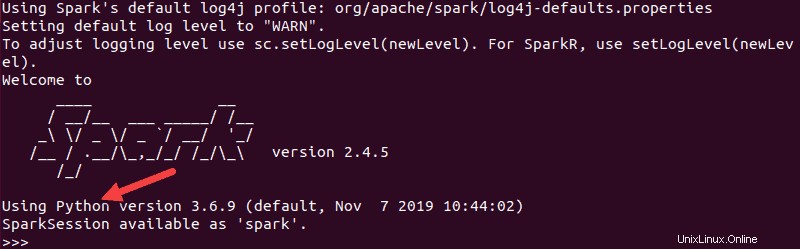
このシェルを終了するには、 quit()と入力します Enterを押します 。
マスターサーバーとワーカーを起動および停止するための基本コマンド
以下は、ApacheSparkマスターサーバーとワーカーを起動および停止するための基本的なコマンドです。この設定は1台のマシンのみを対象としているため、実行するスクリプトはデフォルトでローカルホストになります。
開始する マスター サーバー 現在のマシンのインスタンスで、ガイドの前半で使用したコマンドを実行します:
start-master.shマスターを停止するには 上記のスクリプトを実行してインスタンスを開始し、次を実行します:
stop-master.sh実行中のワーカーを停止するには プロセス、次のコマンドを入力します:
stop-slave.shこの場合、Sparkマスターページには、ワーカーのステータスがDEADとして表示されます。

マスターとサーバーの両方を起動できます start-allコマンドを使用したインスタンス:
start-all.sh同様に、すべてのインスタンスを停止できます 次のコマンドを使用して:
stop-all.sh