はじめに
コンテナの導入により、確立されたソフトウェア開発手法が一変しました。新しいツールと手法が必要だったため、Googleは、アプリケーションの自動スケーリング、デプロイ、管理を行うためのオープンソースのコンテナオーケストレーションシステムであるKubernetesを開発しました。
複数のサーバーやプラットフォームにまたがる、最も複雑なシステムでも管理できる統合APIインターフェースを提供します。
Kubernetesがコンテナの管理とデプロイに不可欠なツールである理由をご覧ください。

コンテナオーケストレーションとは何ですか?
コンテナオーケストレーションツール 、Kubernetesなどは、絶えず変化する混沌とした環境でコンテナ管理を自動化します。その役割を完全に理解するために、コンテナ環境の複雑さを深く掘り下げます。
コンテナ 個々のメモリ、システムファイル、および処理スペースを備えた小さな仮想環境です。独自のオペレーティングシステムを必要とせず、従来の仮想マシンよりもはるかに軽量です。 。それらのサイズと自給自足により、さまざまなデバイスやオペレーティングシステム間でポータブルで無限にスケーラブルになります。
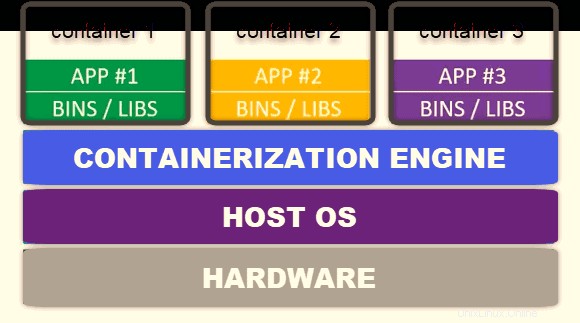
開発者は、アプリケーションをより小さな独立したマイクロサービスのセットとして設計できるようになりました。理想的には、単一のサービスは単一の機能のみを実行する必要があります。これらのマイクロサービスは、Kubernetesクラスターにすばやく簡単に結合およびデプロイされます。
Kubernetesはどのように機能しますか?
コンテナは可能な限り軽量になるように設計されています。結果として、それらは壊れやすく、一時的なものです。 Kubernetesは、個々のコンテナの耐久性を高める代わりに、コンテナの不安定な性質を利用して、その弱点を資産に変えます。
Kubernetesに必要なのは、クラスターをどのように見せたいかという一般的なフレームワークだけです。このフレームワークは通常、コマンドラインインターフェースツールを使用してKubernetesに提供する基本的なマニフェストファイルです。
デフォルトのKubernetesコマンドラインインターフェースはkubectlと呼ばれます 。 Kubectlは、クラスタリソースを直接管理し、KubernetesAPIサーバーに指示を提供するために使用されます。次に、APIサーバーはクラスター内のコンテナーを自動的に追加および削除して、定義された望ましい状態を確認します。 クラスタの実際の状態は常に一致します。
Kubernetesクラスタの主な要素は、マスターノードです。 、ワーカーノード 、およびポッド 。 APIサーバーなど、クラスターに関するグローバルな決定を行うコンポーネントは、マスターノードにあります。
Kubernetesマスターノード
ノードは物理マシンまたはVMです。マスターノードは、クラスターのコンテナーオーケストレーションレイヤーです。マスターノードのコンポーネントはワーカーノードを管理し、それぞれに個別のタスクを割り当てます。クラスタ内の通信の確立と維持、およびワークロードの負荷分散を担当します。
マスターノード
| APIサーバー | APIサーバーは、クラスター内のすべてのコンポーネントと通信します。 |
| Key-Valueストア(etcd) | すべてのクラスターデータを蓄積するために使用される軽量の分散型Key-Valueストア。 |
| コントローラー | APIサーバーを使用して、クラスターの状態を監視します。クラスタの実際の状態を移動して、マニフェストファイルから目的の状態に一致させようとします。 |
| スケジューラー | 新しく作成されたポッドをワーカーノードにスケジュールします。常にトラフィックが最も少ないノードを選択して、ワークロードのバランスを取ります。 |
Kubernetesワーカーノード
マスターノードコンポーネントは、ワーカーノードを制御します 。ワーカーノードには複数のインスタンスがあり、それぞれが割り当てられたタスクを実行します。これらのノードは、コンテナ化されたワークロードとストレージボリュームが展開されるマシンです。
ワーカーノード
| Kubelet | 各ノードで実行され、そのマシンでポッドを作成、破棄、監視するマスターの要求に応答するデーモン。 |
| コンテナランタイム | コンテナランタイム コンテナ画像レジストリから画像を取得します コンテナを開始および停止します。これは通常、Dockerなどのサードパーティのソフトウェアまたはプラグインです。 |
| Kube-プロキシ | クラスタ内またはクラスタ外からポッドへのネットワーク通信を維持するネットワークプロキシ。 |
| アドオン(DNS、Web UI ..) | 特定の機能を拡張するためにクラスターに追加できる追加機能。 |
| ポッド | ポッド Kubernetesでのスケジューリングの最小要素です。これは、アプリケーションコードを含むコンテナの「ラッパー」を表します。 Kubernetesクラスタ内でアプリをスケーリングする必要がある場合は、ポッドを追加または削除することによってのみスケーリングできます。ノードは複数のポッドをホストできます。 |
Kubernetesクラスタを管理する方法
Kubernetesには、ユーザーまたは内部コンポーネントがKubernetesクラスター内のオブジェクトを識別、管理、操作するために利用するいくつかの手段があります。
ラベル
ラベル ポッドに割り当てることができる単純なキーと値のペアです。割り当てられると、ポッドの識別と制御が容易になります。ラベルは、ポッドをユーザー定義のサブセットにグループ化して編成します。ポッドをグループ化して意味のある識別子を与える機能により、ユーザーによるクラスターの制御が向上します。
注釈
ラベルと同じように、アノテーション キーと値のペアでもあり、メタデータをオブジェクトに添付するために使用できます。ただし、Kubernetesは注釈を使用してオブジェクトを選択および識別しません。
アノテーションには、Kubernetesの内部リソースで使用することを意図していない情報が保存されます。管理者の連絡先情報、一般的なイメージまたはビルド情報、特定のデータの場所、またはログ記録のヒントが含まれている可能性があります。アノテーションを使用すると、この有用な情報を外部リソースに保存する必要がなくなり、パフォーマンスが向上します。
Kubernetesの名前空間
Kubernetesクラスタ内のすべてのオブジェクトには、一意のIDと名前があります これは、そのリソースタイプを示します。 名前空間 リソースのグループを分離するために使用されます。各名前 名前空間内は、名前の衝突の問題を防ぐために一意である必要があります。異なる名前空間で同じ名前を使用する場合、そのような制限はありません。
この特徴的な機能により、同じオブジェクトのデタッチされたインスタンスを同じ名前で分散環境に保持できます。
クラスタ内の既存の名前空間を一覧表示するには、コマンドラインインターフェイスで次のコマンドを入力します。
kubectl get namespacesレプリケーションコントローラー
マイクロサービスの概念は、特定のサービスの複数のインスタンスをデプロイして同時に実行する必要があることを暗黙的に意味します。 レプリケーションコントローラー ポッドの特定のインスタンスのレプリカの数を管理します。レプリケーションコントローラーをユーザー定義のラベルと組み合わせることで、適切なラベルを使用してクラスター内のポッドの数を簡単に管理できます。
たとえば、構成ファイル内のレプリカの数を5に設定できます。現在実行中のレプリカが3つしかない場合、Kubernetesは目的の状態に一致するようにさらに2つスピンアップします。 10個のレプリカが実行されている場合、Kubernetesはそのうちの5個を終了します。
Kubernetesは、レプリカの数を構成ファイルで定義された数と調和させるために継続的に機能します。
展開
d雇用 は、ユーザーの定義に従ってポッドが稼働、更新、またはロールバックされることを保証するテンプレートをレイアウトするメカニズムです。展開は単一のポッドを超え、複数のポッドに分散する場合があります。
レプリケーションコントローラーは、サービスのレプリカの数を制御します。ポッドはクラスターに定期的に追加またはクラスターから削除されます。このプロセス中、ポッドはクラスター内を移動し、別のノードにデプロイされることもあります。このため、ポッドのIPアドレスは一定ではありません。 Kubernetesサービス ラベルセレクターを使用してポッドをグループ化し、これらのポッドを検出して操作するために使用される単一の仮想IPでポッドを抽象化します。
なぜKubernetesが必要なのですか?
効率的なリソースの使用
Kubernetesのようなコンテナオーケストレーションツールは、人間よりも効率的にリソースを節約します。 Kubernetesはクラスタを監視し、ノードで現在消費されているリソースに基づいてコンテナを起動する場所を選択します。
コンテナの通信と同期
アプリには複数のコンテナが必要になることが多いため、Kubernetesはマルチコンテナアプリケーションをデプロイして、すべてのコンテナが同期され、相互に通信していることを確認できます。
Kubernetesは、アプリケーションの正常性に関する洞察を提供します。コンテナーとクラスターの重要な情報とメトリックを提供できます。アプリケーションがダウンすると、Kubernetesは、システムリソースを最適に使用して、最小限のダウンタイムで別のコンテナーを回転させることにより、アプリケーションを自動的に回復します。
効率的に適応
オーケストレーションツールがないと、アプリケーションのスケーリングは時間のかかるプロセスになります。組織は、瞬間的なワークロードに応じてコンテナを追加または削除することで、市場のニーズに迅速に適応できるようになりました。たとえば、オンライン小売業者は、需要の増加に応じてアプリケーションの容量を即座に増やすことができます。需要が少ない時期には、管理者はアプリケーションをすばやく縮小できます。
Kubernetesの使用を開始する方法
Kubernetesはコンテナを設定および調整するためのシステムであるため、Kubernetesを使用するための前提条件は、コンテナ化エンジンを備えていることです。 。
Dockerを含む多くのコンテナソリューションがあります 今日最も人気があります。他のコンテナプロバイダーには、 AWS、LXDが含まれます 、Javaコンテナ 、Hyper-Vコンテナ 、およびWindowsServerコンテナ 。
コンテナとは別に、Kubernetesがユーザーに完全なエクスペリエンスを提供するために依存している他のプロジェクトとサポートがあります。それらのいくつかは次のとおりです:
- DockerまたはAtomicレジストリ(公式レジストリ用)
- Ansible(自動化用)
- OpenvSwitchとインテリジェントエッジルーティング(ネットワーキング用)
- マルチテナンシーレイヤーを備えたLDAP、SELinux、RBAC、OAUTH(Kubernetesセキュリティ用)
- Heapster、Kibana、Hawkular、Elastic(テレメトリ用)
複数のコンテナをデプロイした経験がまだない初心者向けに、 Minikube 始めるのに最適な方法です。 Minikubeは、シングルノードクラスターをローカルで実行するためのシステムであり、Kubernetesに進む前に基本を学ぶのに最適です。
AnsibleとKubernetesの詳細については、AnsibleとKubernetesの違いに関する記事をご覧ください。