はじめに
MySQLは、重複を避けるために異なるテーブルの行と列にデータを格納するデータベースアプリケーションです。重複する値が発生する可能性があり、MySQLのパフォーマンスに影響を与える可能性があります。
このガイドでは、MySQLデータベースで重複する値を見つける方法を説明します 。

前提条件
- MySQLの既存のインストール
- MySQLのrootユーザーアカウントのクレデンシャル
- コマンドライン/ターミナルウィンドウ
サンプルテーブルの設定(オプション)
この手順は、操作するサンプルテーブルを作成するのに役立ちます。作業するデータベースがすでにある場合は、次のセクションにスキップしてください。
ターミナルウィンドウを開き、MySQLシェルに切り替えます:
mysql –u root –p既存のデータベースを一覧表示する:
SHOW databases;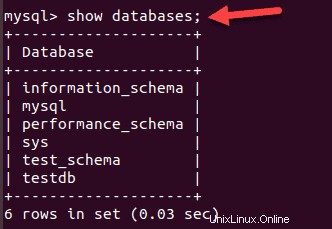
まだ存在していない新しいデータベースを作成します:
CREATE database sampledb;作成したテーブルを選択します:
USE sampledb;次のフィールドを使用して新しいテーブルを作成します。
CREATE TABLE dbtable (
id INT PRIMARY KEY AUTO_INCREMENT,
date_x VARCHAR(10) NOT NULL,
system_x VARCHAR(50) NOT NULL,
test VARCHAR(50) NOT NULL
);テーブルに行を挿入します:
INSERT INTO dbtable (date_x,system_x,test)
VALUES ('01/03/2020','system1','hard_drive'),
('01/04/2020','system2','memory'),
('01/10/2020','system2','processor'),
('01/14/2020','system3','hard drive'),
('01/10/2020','system2','processor'),
('01/20/2020','system4','hard drive'),
('01/24/2020','system5','memory'),
('01/29/2020','system6','hard drive'),
('02/02/2020','system7','motherboard'),
('02/04/2020','system8','graphics card'),
('02/02/2020','system7','motherboard'),
('02/08/2020','system9','hard drive');次のSQLクエリを実行します:
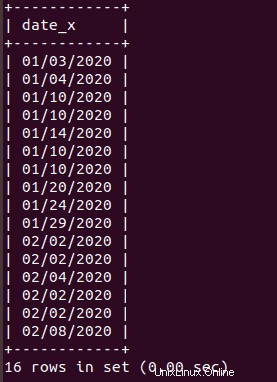
SELECT * FROM dbtable
ORDER BY date_x;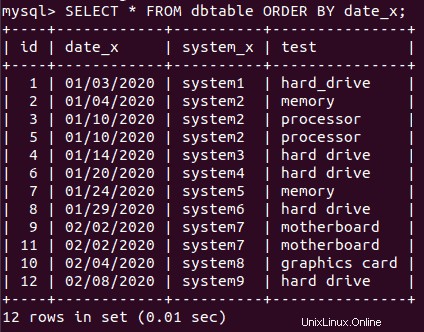
MySQLで重複を見つける
単一の列で重複する値を見つける
GROUP BYを使用します 1つの列のすべての同一のエントリを識別する関数。 COUNT() HAVINGでフォローアップします 複数のエントリを持つすべてのグループを一覧表示する関数。
SELECT
test,
COUNT(test)
FROM
dbtable
GROUP BY test
HAVING COUNT(test) > 1;
複数の列で重複する値を見つける
3つの列すべてに同じ情報を含めて、完全に重複するものをリストすることをお勧めします。
SELECT
date_x, COUNT(date_x),
system_x, COUNT(system_x),
test, COUNT(test)
FROM
dbtable
GROUP BY
date_x,
system_x,
test
HAVING COUNT(date_x)>1
AND COUNT(system_x)>1
AND COUNT(test)>1;

このクエリは、> 1を選択してテストすることで機能します 3列すべての条件。その結果、重複する値を持つ行のみが出力に返されます。
内部結合を使用して複数のテーブルの重複をチェックする
INNER JOIN関数を使用して、複数のテーブルに存在する重複を検索します。
INNER JOINのサンプル構文 関数は次のようになります:
SELECT column_name
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column name;
この例をテストするには、 sampledbから複製された情報を含む2番目のテーブルが必要です。 上で作成したテーブル。
SELECT dbtable.date_x
FROM dbtable
INNER JOIN new_table
ON dbtable.date_x = new_table.date_x;
これにより、既存のデータと new_tableの間に存在する重複する日付が表示されます。 。