はじめに
ClickHouse は、オープンソースの列指向データベース管理システムです。これは、リアルタイムで更新されるデータ分析に使用する、高速でスケーラブルで効率的なソフトウェアです。
不要なデータを処理する必要がないため、行指向のデータベースよりも少ないメモリとCPUを使用します。したがって、クエリの応答時間が速く、最終的に最適なパフォーマンスが得られます。さらに、SQLを理解するため、よりユーザーフレンドリーになります。
ClickHouseは非常に柔軟性があります。この管理システムは、ベアメタルサーバーからクラウドサーバーまで、およびLinux、MacOS、FreeBSDオペレーティングシステムのいずれでも実行できます。
このガイドでは、CentOS7サーバーにClickHouseをインストールして使用を開始する方法を説明します。

前提条件
- ターミナルウィンドウ/コマンドラインへのアクセス
- sudo権限でCentOS7を実行しているサーバー
- テキストエディタ(Nanoなど)
- リモートサーバーに接続するためのSSHサービス
SSH経由で接続して更新
1. ClickHouseをインストールする前に、リモートのCentOSサーバーにアクセスする必要があります。
次のコマンドを実行して、 your_usernameを置き換えます およびhost_ip_address それぞれの仕様で:
ssh [email protected]_ip_address2.サーバーに接続したら、次のコマンドを実行してシステムを更新してください。
sudo yum updateCentOSにClickHouseをインストールする
1.まず、pygpgme packageを含むソフトウェアの依存関係をインストールします (GPG署名の追加と検証用)および yum-utils (ソースRPM管理用):
sudo yum install -y pygpgme yum-utilshere2. ClickHouseの最新バージョンをインストールするには、ClickHouseのコンサルティング会社である Altinityが管理するYUMリポジトリにアクセスする必要があります。 。ただし、インストールパッケージがサーバーに害を及ぼさないようにする必要もあります。
選択したテキストエディタでリポジトリファイルを作成することから始めます(この例では、Nanoを使用しました):
sudo nano /etc/yum.repos.d/altinity_clickhouse.repo3.次に、新しく作成したファイルに次のコンテンツを追加します。
[altinity_clickhouse]
name=altinity_clickhouse
baseurl=https://packagecloud.io/altinity/clickhouse/el/7/$basearch
repo_gpgcheck=1
gpgcheck=0
enabled=1
gpgkey=https://packagecloud.io/altinity/clickhouse/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
[altinity_clickhouse-source]
name=altinity_clickhouse-source
baseurl=https://packagecloud.io/altinity/clickhouse/el/7/SRPMS
repo_gpgcheck=1
gpgcheck=0
enabled=1
gpgkey=https://packagecloud.io/altinity/clickhouse/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300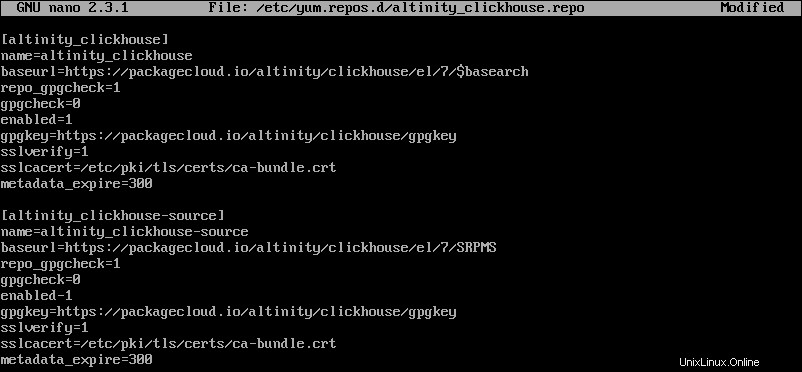
4.リポジトリファイルを保存して閉じます。
5.次に、次のコマンドでリポジトリを有効にします。
sudo yum -q makecache -y --disablerepo'*' --enablerepo='altinity_clickhouse'6.出力でGPGキーが追加されたことを確認したら、ClickHouseのインストールに進むことができます。次のコマンドを使用して、clickhouse-serverおよびclickhouse-clientパッケージをダウンロードします。
sudo yum install -y clickhouse-server clickhouse-client7.これで、CentOS7サーバーにClickHouseがインストールされました。
ClickHouseサービスの開始方法
systemd service clickhouse-serverによって作成されました パッケージは、データベースの開始、再起動、および停止を担当します。
開始 ClickHouseサーバーは次のコマンドを使用します:
sudo service clickhouse-server start here端末は次の出力を表示する必要があります:

次の方法で、サービスが正しく実行されているかどうかを確認することもできます。
sudo service clickhouse-server status受信するメッセージは、次の画像のようになります。

データベースとテーブルを作成する方法
データベースとテーブルを作成するには、最初にクライアントセッションを開始する必要があります。プロンプトが開いたら、それを使用してSQLステートメントを実行できます。
clickhouse-client --multiline
clickhouse-client コマンドは、新しいセッション --multilineを開きます フラグを使用すると、複数行を占めるクエリを実行できます。
データベースの作成
データベースは基本的にテーブルのディレクトリです。データベースを作成するための構文は次のとおりです。
CREATE DATABASE db_name出力は、「わかりました。」というメッセージを表示して、データベースが作成されたことを確認します。 」、およびセット内の行数 と時間 作成するのに時間がかかりました。
クラスタからすべてのサーバーにデータベースを作成するには 、[ON CLUSTERcluster_id]句を基本構文に追加します:
CREATE DATABASE db_name [ON CLUSTER cluster_id]
リモートMySQLからデータを取得する サーバーを新しく作成したデータベースに追加します[ENGINE = engine(…)] 次のコマンドのように、句:
CREATE DATABASE db_name [ENGINE = engine(…)]テーブルを作成する
テーブルを作成するための構文は次のとおりです。
CREATE TABLE table_name
(
column_name1 column_type [options],
column_name2 column_type [options],
) ENGINE = engine
エンジンのタイプ 選択するのはアプリケーションによって異なります。 ClickHouseには、構成可能なテーブルエンジンとSQLダイアレクトをサポートするネイティブデータベースエンジンがあります。
一般的に、MergeTreeファミリーエンジンが最も広く使用されています。ただし、ClickHouseはMySQLもサポートしています。
テーブルを作成するときは、最初に変更するデータベースを開く必要があります。次のコマンドを使用します:
ch:) USE db_name出力は、指定されたデータベースにいることを確認します。
次に、必要なすべての列(および列タイプ)を含むテーブルを作成できます。この例では、クライアントを作成します 6つで構成されるテーブル (6)コマンドを使用する列:
ch:) CREATE TABLE Client (
ch:) ClientID UInt64,
ch:) FirstName String,
ch:) LastName String,
ch:) Address String,
ch:) City String,
ch:) BirthDate DateTime
ch:) ) ENGINE = MergeTree()
ch:) PRIMARY KEY ClientID
ch:) ORDER BY ClientID;名前 および列 タイプ 各列を定義します。この例の列タイプは次のとおりです。
- UInt64:0から18446744073709551615までの整数を格納するため
- 文字列:文字、数字、スペースを含むテキストを保存するため
- DateTime:日付と時刻をYYYY-MM-DD HH:MM:SSの形式で保存するため
この場合、ストレージエンジン 最も堅牢なClickHouseテーブルエンジン– MergeTree 。
次に、 PRIMERY KEY テーブルのすべてのレコードを識別するために使用する列を定義します。
最後に、注文者 句を使用すると、定義された列に基づいて結果を並べ替えることができます。
作成すると、出力は次のように表示されます。
CREATE TABLE Client
(
ClientID UInt64,
FirstName String,
LastName String,
Address String,
City String,
BirthDate DateTime
)
ENGINE = MergeTree()
PRIMARY KEY ClientID
ORDER BY ClientID
Ok.
0 rows in set. Elapsed: 0.010 sec.データと列の挿入、更新、削除
行を挿入するには テーブルでは、次のクエリ構文を使用します。
INSERT INTO table_name VALUES (column_1_value, column_2_value, ....);たとえば、以前に作成したClientテーブルに行を挿入する場合は、次のコマンドを実行します。
TO BE ADDED新しい列を追加する場合 テーブルにするには、次の構文を使用します:
ALTER TABLE table_name ADD COLUMN column_name column_type;たとえば、Profession列をClientテーブルに追加する場合、コマンドは次のようになります。
ALTER TABLE Client ADD COLUMN Profession String;複数の列を追加するには 構文の使用:
ALTER TABLE table_name ADD COLUMN column_1 column_type, column_2 column_type, column_3 column_type;ClickHouseデータベースは、非同期バッチ操作を含む、更新と削除に非標準のSQLクエリを使用します。次のコマンドは、バージョン18.12.14以降で使用できます。
更新の構文 は:
ALTER TABLE table_name UPDATE column_1 = value_1, column_2 = value_2 ... WHERE filter_conditions;行の削除の構文 は:
ALTER TABLE table_name DELETE WHERE filter_conditions;列の削除の構文 は:
ALTER TABLE table_name DROP COLUMN column_name;テーブルとデータベースの削除
テーブルを削除または削除するには、次の構文を使用します。
DROP TABLE table_nameClintテーブルを削除する場合は、次のコマンドを使用します。
DROP TABLE Clientデータベースを完全に削除するための構文 は:
DROP database db_nameデータのクエリまたは取得
SELECT句を使用して、行と列からデータを取得します。基本的な構文は次のとおりです。
SELECT func_1(column_1), func_2(column_2) FROM table_name WHERE filter_conditions row_options;複数の行と列の値を要約する単一の出力値を取得する場合は、集計関数を使用できます。
ClickHouseでサポートされている一般的な集計関数の例を次に示します。
•avg (平均):選択した列の平均ボリュームを計算します。数字にのみ使用
•カウント :指定された基準に一致する行数を計算します
•合計 (合計):数値列の合計を計算します。数字にのみ使用
•uniq :基準に一致する行のおおよその数を計算します。数字、文字列、日付に使用されます