大量のデータを処理するストリーミング プラットフォームが必要ですか? Linux 上の Apache Kafka について聞いたことがあるでしょう。 Apache Kafka はリアルタイムのデータ処理に最適であり、ますます人気が高まっています。 Linux に Apache Kafka をインストールするのは少し難しいかもしれませんが、心配はいりません。このチュートリアルで説明されています。
このチュートリアルでは、Apache Kafka をインストールして構成する方法を学習します。これにより、プロのようにデータの処理を開始して、ビジネスの効率と生産性を高めることができます。
今すぐ Apache Kafka でデータのストリーミングを開始してください!
前提条件
このチュートリアルは実践的なデモンストレーションです。フォローしたい場合は、次のものがあることを確認してください。
- Linux マシン – このデモでは Debian 10 を使用していますが、どの Linux ディストリビューションでも動作します。
- Kafka を実行するために必要な、sudo 権限を持つ、
kafkaという名前の非 root ユーザー アカウント - Kafka 専用の sudo ユーザー – このチュートリアルでは、kafka という sudo ユーザーを使用します。
- Java – Java は Apache Kafka のインストールに不可欠です。
- Git – このチュートリアルでは、Git を使用して Apache Kafka Unit ファイルをダウンロードします。
Apache Kafka のインストール
データをストリーミングする前に、まずマシンに Apache Kafka をインストールする必要があります。 Kafka 専用のアカウントを持っているので、システムを壊す心配なく Kafka をインストールできます。
1. mkdir を実行します 以下のコマンドで /home/kafka/Downloads を作成します ディレクトリ。ディレクトリには好きな名前を付けることができますが、ディレクトリの名前は Downloads です。 このデモのために。このディレクトリには、Kafka バイナリが格納されます。このアクションにより、Kafka のすべてのファイルが kafka で利用できるようになります。 ユーザー。
mkdir Downloads
2. 次に、以下の apt update を実行します コマンドを使用して、システムのパッケージ インデックスを更新します。
sudo apt update -yプロンプトが表示されたら、kafka ユーザーのパスワードを入力します。
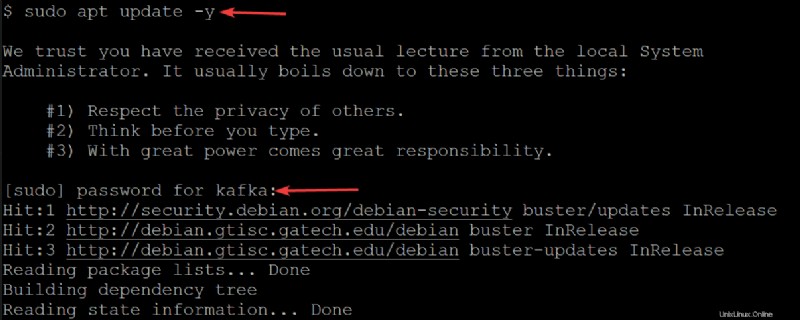
3. curl を実行します 以下のコマンドを実行して、Apache Foundation Web サイトから Kafka バイナリをダウンロードして出力します (-o ) をバイナリ ファイル (kafka.tgz ) ~/Downloads で ディレクトリ。このバイナリ ファイルを使用して、Kafka をインストールします。
kafka/3.1.0/kafka_2.13-3.1.0.tgz を最新バージョンの Kafka バイナリに置き換えてください。これを書いている時点で、現在の Kafka のバージョンは 3.1.0 です。
curl "https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz" -o ~/Downloads/kafka.tgz
4. tar を実行します。 以下のコマンドで抽出します (-x ) Kafka バイナリ (~/Downloads/kafka.tgz ) 自動的に作成された kafka に ディレクトリ。 tar のオプション コマンドは以下を実行します:
tar のオプション コマンドは以下を実行します:
-v–tarに伝える 抽出されたすべてのファイルを一覧表示するコマンド
-z–tarに伝える コマンドを使用して、アーカイブが解凍されているときにアーカイブを gzip します。この場合、この動作は必須ではありませんが、移動するためにすばやく圧縮/zip ファイルが必要な場合は特に、優れたオプションです。
-f–tarに伝える 抽出するアーカイブ ファイルのコマンド
-strip 1-tarを指示します コマンドを使用して、ファイル名リストからディレクトリの最初のレベルを取り除きます。その結果、kafka という名前のサブディレクトリが自動的に作成されます。~/Downloads/kafka.tgzから抽出されたすべてのファイルを含む ファイル。
tar -xvzf ~/Downloads/kafka.tgz --strip 1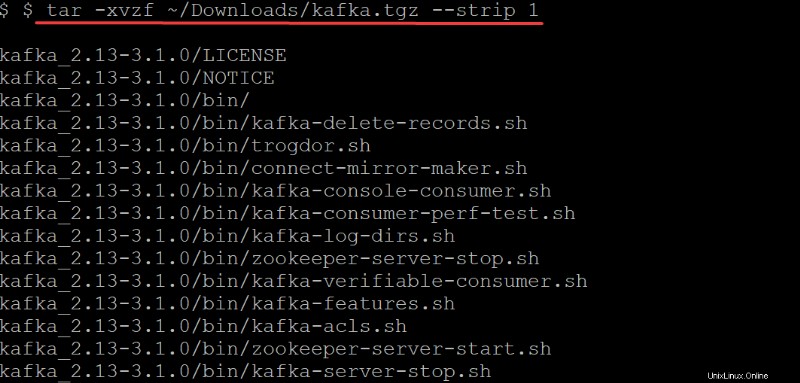
Apache Kafka サーバーの構成
この時点で、Kafka バイナリを ~/Downloads にダウンロードしてインストールしました ディレクトリ。デフォルトでは、Kafka では、ログ メッセージを整理するために必要なカテゴリであるトピックの削除や変更が許可されていないため、まだ Kafka サーバーを使用することはできません。
Kafka サーバーを構成するには、Kafka 構成ファイル (/etc/kafka/server.properties) を編集する必要があります。
1. Kafka 構成ファイルを開きます (/etc/kafka/server.properties ) を好みのテキスト エディターで編集します。
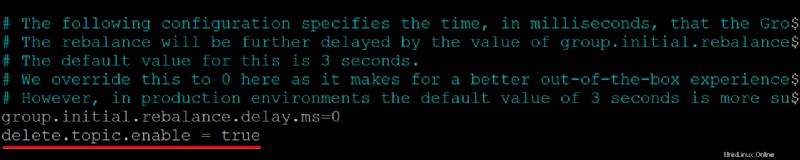
2. 次に、delete.topic.enable =true を追加します /kafka/config/server.properties の一番下の行 ファイルの内容を確認し、変更を保存してエディターを閉じます。
この構成プロパティにより、トピックを削除または変更する権限が付与されるため、トピックを削除する前に何をしているのかを確認してください。トピックを削除すると、そのトピックのパーティションも削除されます。これらのパーティションに保存されているデータは、削除されるとアクセスできなくなります。
各行の先頭にスペースがないことを確認してください。そうしないと、ファイルが認識されず、Kafka サーバーが動作しません。
3. git を実行します 以下のコマンドを clone に ata-kafka プロジェクトをローカル マシンにコピーして、Kafka サービスのユニット ファイルとして使用するために変更できるようにします。
sudo git clone https://github.com/Adam-the-Automator/apache-kafka.git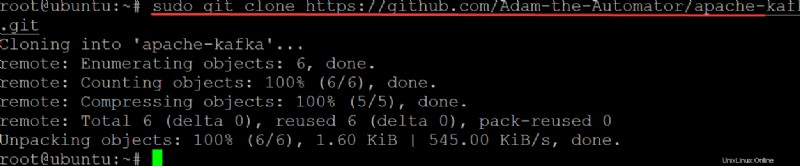
次に、以下のコマンドを実行して apache-kafka に移動します ディレクトリを開き、その中のファイルを一覧表示します。
cd apache-kafka
lsこれで ata-kafka に入りました 以下に示すように、ディレクトリ内に kafka.service と Zookeeper.service の 2 つのファイルがあることがわかります。

5. zookeeper.service を開きます 好みのテキスト エディターでファイルします。このファイルを参照として使用して、kafka.service を作成します。 ファイル。
zookeeper.service で以下の各セクションをカスタマイズします ファイル、必要に応じて。ただし、このデモでは、このファイルを変更せずにそのまま使用します。
[Unit]セクションは、このユニットの起動プロパティを構成します。このセクションは、zookeeper サービスを開始するときに何を使用するかを systemd に指示します。
- [Service] セクションでは、kafka-server-start.sh を使用して Kafka サービスを開始する方法、時期、場所を定義します。 脚本。このセクションでは、名前、説明、コマンドライン引数 (ExecStart=に続くもの) などの基本情報も定義します。
[Install]セクションは、マルチユーザー モードに入ったときにサービスを開始するランレベルを設定します。
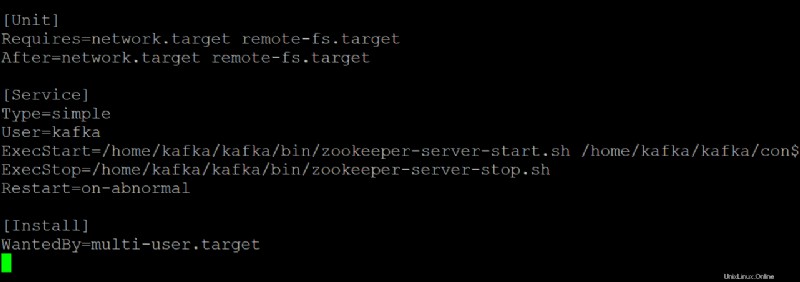
6. kafka.service を開きます 任意のテキスト エディターでファイルを作成し、systemd サービスとして実行されているときに Kafka サーバーがどのように見えるかを構成します。
このデモでは、kafka.service にあるデフォルト値を使用します ファイルですが、必要に応じてファイルをカスタマイズできます。このファイルは zookeeper.service を参照していることに注意してください
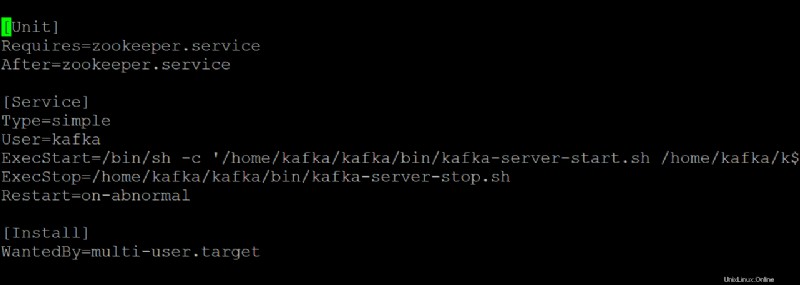
7. 以下のコマンドを start に実行します kafka サービス。
sudo systemctl start kafkaKafka サーバーをサービスとして停止して開始することを忘れないでください。そうしないと、プロセスはメモリに残り、強制終了することによってのみプロセスを停止できます。プロセスのシャットダウン時に書き込み中または更新中のトピックがある場合、この動作によりデータが失われる可能性があります。
kafka.service を作成したので、 zookeeper.service 以下のコマンドのいずれかを実行して、systemd ベースの Kafka サーバーを停止または再起動することもできます。
sudo systemctl stop kafka
sudo systemctl restart kafka
8. journalctl を実行します。 以下のコマンドを実行して、サービスが正常に起動したことを確認します。
このコマンドは、kafka サービスのすべてのログを一覧表示します。
sudo journalctl -u kafkaすべてを正しく構成すると、以下に示すように、「kafka.service を開始しました」というメッセージが表示されます。おめでとう!これで、systemd サービスとして実行される完全に機能する Kafka サーバーが完成しました。

Kafka ユーザーの制限
この時点で、Kafka サービスは kafka ユーザーとして実行されます。 kafka ユーザーはシステムレベルのユーザーであり、Kafka に接続するユーザーには公開しないでください。
このブローカーを介して Kafka に接続するすべてのクライアントは、実質的にブローカー マシンでルート レベルのアクセス権を持つことになりますが、これはお勧めできません。リスクを軽減するために、sudoers ファイルから kafka ユーザーを削除し、kafka ユーザーのパスワードを無効にします。
1. exit を実行します 以下のコマンドを実行して、通常のユーザー アカウントに戻します。
exit
2. 次に、sudo deluser kafka sudo を実行します Enter を押します kafka を削除することを確認する sudoers からのユーザー。
sudo deluser kafka sudo
3. 以下のコマンドを実行して、kafka ユーザーのパスワードを無効にします。そうすることで、Kafka インストールのセキュリティがさらに向上します。
sudo passwd kafka -l
4. 次に、次のコマンドを再実行して、sudoers リストから kafka ユーザーを削除します。
sudo deluser kafka sudo
5. 以下の su を実行します root ユーザーなどの許可されたユーザーのみが kafka としてコマンドを実行できるように設定するコマンド ユーザー。
sudo su - kafka
6. 次に、以下のコマンドを実行して、ATA という名前の新しい Kafka トピックを作成します。 Kafka サーバーが正しく実行されていることを確認します。
Kafka トピックは、サーバーとの間のメッセージのフィードであり、Kafka サーバーに乱雑で整理されていないデータがあるという複雑さを排除するのに役立ちます
cd /usr/local/kafka-server && bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic ATA
7. 以下のコマンドを実行して、kafka-console-producer.sh を使用して Kafka プロデューサーを作成します。 脚本。 Kafka プロデューサーはデータをトピックに書き込みます。
echo "Hello World, this sample provided by ATA" | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic ATA > /dev/null
8. 最後に、以下のコマンドを実行して、kafka-console-consumer.sh を使用して kafka コンシューマーを作成します。 脚本。このコマンドは、kafka トピック内のすべてのメッセージを消費します (--topic ATA ) メッセージ値を出力します。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ATA --from-beginning以下に示すように、メッセージは ATA Kafka トピックから Kafka コンソール コンシューマーによって出力されるため、以下の出力にメッセージが表示されます。コンシューマー スクリプトはこの時点で引き続き実行され、さらにメッセージを待ちます。
別のターミナルを開いてトピックにメッセージを追加し、テストが完了したら Ctrl+C を押してコンシューマ スクリプトを停止できます。

結論
このチュートリアルを通じて、マシンで Apache Kafka をセットアップして構成する方法を学習しました。また、Kafka プロデューサーによって生成された Kafka トピックからのメッセージの消費についても触れました。これにより、効果的なイベント ログ管理が実現します。
さて、メッセージの配信と管理を改善するために、Kafka と Flume をインストールして、この新たな知識を構築してみませんか?また、Kafka の Streams API を調べて、Kafka にデータを読み書きするアプリケーションを構築することもできます。これにより、必要に応じてデータが変換されてから、HDFS、HBase、Elasticsearch などの別のシステムに書き出されます。