Bash スクリプトの実行に時間がかかることにうんざりしている場合は、このチュートリアルが最適です。多くの場合、スクリプトを並行して Bash できます。これにより、結果が劇的に高速化されます。どのように? Parallel とも呼ばれる GNU Parallel ユーティリティを、いくつかの便利な GNU Parallel の例とともに使用します!
Parallel は、マルチスレッドと呼ばれる概念を介して Bash スクリプトを並行して実行します。このユーティリティを使用すると、1 つの CPU だけではなく、CPU ごとに異なるジョブを実行できるため、スクリプトの実行時間を短縮できます。
このチュートリアルでは、多数の優れた GNU Parallel の例を使用して、マルチスレッド Bash スクリプトを学習します!
前提条件
このチュートリアルは、実践的なデモンストレーションでいっぱいです。従う場合は、次のものがあることを確認してください:
- Linux コンピュータ。どのディストリビューションでも機能します。このチュートリアルでは、Windows Subsystem for Linux (WSL) で実行されている Ubuntu 20.04 を使用しています。
- sudo 権限を持つユーザーでログインしている。
GNU パラレルのインストール
マルチスレッドで Bash スクリプトを高速化するには、まず Parallel をインストールする必要があります。それでは、ダウンロードしてインストールすることから始めましょう。
1. Bash ターミナルを開きます。
2. wget を実行します Parallel パッケージをダウンロードします。以下のコマンドは、最新バージョン (parallel-latest) をダウンロードします。 ) を現在の作業ディレクトリに追加します。
wget https://ftp.gnu.org/gnu/parallel/parallel-latest.tar.bz2古いバージョンの GNU Parallel を使用したい場合は、公式ダウンロード サイトですべてのパッケージを見つけることができます。
3. 次に、以下の tar コマンドを実行して、ダウンロードしたパッケージを解凍します。
以下、コマンドは x を使用します アーカイブを抽出するためのフラグ、j .bz2 でアーカイブをターゲットにしていることを指定する 拡張子、および f tar コマンドへの入力としてファイルを受け入れる。 sudo tar -xjf parallel-latest.tar.bz2
sudo tar -xjf parallel-latest.tar.bz2parallel- という名前のディレクトリが作成されます。 最新リリースの月、日、年と一緒に。
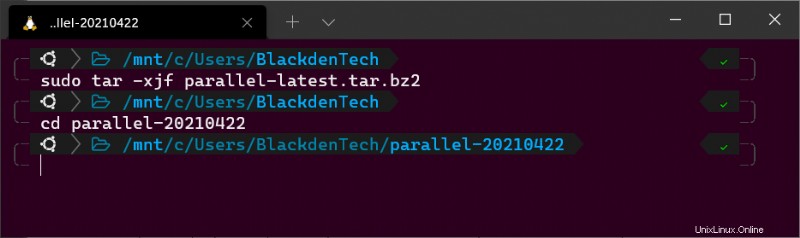
4. cd でパッケージ アーカイブ フォルダーに移動します。 .このチュートリアルでは、パッケージ アーカイブ フォルダーの名前は parallel-20210422 です。 、以下に示すように。
5. 次に、次のコマンドを実行して、GNU Parallel バイナリをビルドしてインストールします。
./configure
make
make install次に、インストールされているバージョンを確認して、Parallel が正しくインストールされていることを確認します。
parallel --version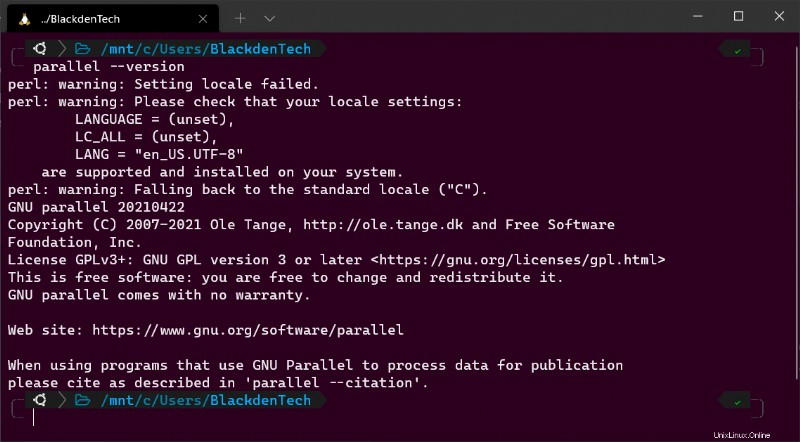
初めて Parallel を実行すると、
perl: warning:のようなテキストを表示する恐ろしい行がいくつか表示される場合があります。 .これらの警告メッセージは、Parallel が現在のロケールと言語の設定を検出できないことを示しています。ただし、今のところ、これらの警告について心配する必要はありません。これらの警告を修正する方法については後で説明します。
GNU 並列の構成
Parallel がインストールされたので、すぐに使用できます。ただし、開始する前に、いくつかのマイナーな設定を構成することが重要です。
まだ Bash ターミナルにいる間に、citation を指定することにより、学術研究で引用することを Parallel に伝える GNU Parallel 学術研究許可に同意します。 パラメータの後に will cite が続きます .
GNU またはそのメンテナーをサポートしたくない場合は、GNU Parallel を使用するために引用に同意する必要はありません。
parallel --citation
will cite以下のコード行を実行して次の環境変数を設定し、ロケールを変更します。このようにロケールと言語の環境変数を設定することは必須ではありません。しかし、GNU Parallel は実行するたびにそれらをチェックします。
環境変数が存在しない場合、前のセクションで見たように、Parallel は毎回エラーを出します。
このチュートリアルは、あなたが英語を話すことを前提としています。他の言語もサポートされています。
export LC_ALL=C man
export LANGUAGE=en_US
export LANG=en_US.UTF-8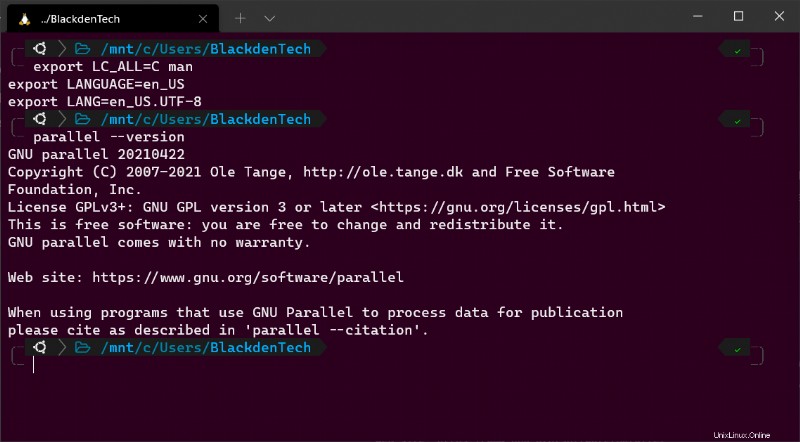
アドホック シェル コマンドの実行
それでは、GNU Parallel を使い始めましょう!まず、基本的な構文を学びます。構文に慣れたら、後で便利な GNU Parallel の例に取り掛かります。
まず、1 ~ 5 の数字をエコーするだけの非常に単純な例を取り上げましょう。
1. Bash ターミナルで、次のコマンドを実行します。わくわくしますよね? Bash は echo コマンドを使用して、1 から 5 の数字を端末に送信します。これらの各コマンドをスクリプトに入れると、Bash はそれぞれを順番に実行し、前のコマンドが終了するのを待ちます。
この例では、ほとんど時間がかからない 5 つのコマンドを実行しています。しかし、これらのコマンドが Bash スクリプトであり、実際には何か有用なことを実行したとしても、実行に時間がかかると想像してみてください。
echo 1
echo 2
echo 3
echo 4
echo 5
次に、以下のように Parallel でこれらの各コマンドを同時に実行します。この例では、Parallel は ::: で指定された echo コマンドを実行します。 、そのコマンドに引数 1 を渡します 、 2 、 3 、 4 、 5 . 3 つのコロンは、パイプラインではなくコマンド ラインを介して入力を提供していることを Parallel に伝えます (詳細は後述)。
以下の例では、単一のコマンドをオプションなしで Parallel に渡しました。ここで、すべての Parallel の例と同様に、Parallel は異なる CPU コアを使用して各コマンドの新しいプロセスを開始しました。
# From the command line
parallel echo ::: 1 2 3 4 5すべての並列コマンドは構文
parallel [Options]に従います .
3. Bash パイプラインからの並列受信入力を示すために、count_file.txt という名前のファイルを作成します。 以下のように。各数字は、echo コマンドに渡す引数を表します。
1
2
3
4
5
4. cat を実行します。 以下に示すように、コマンドを使用してそのファイルを読み取り、出力を Parallel に渡します。この例では、{} Parallel に渡される各引数 (1 ~ 5) を表します。
# From the pipeline cat count_file.txt | parallel echo {}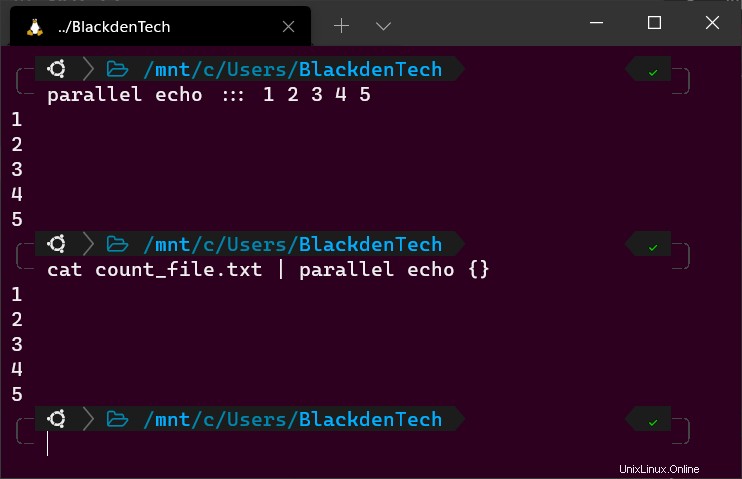
Bash と GNU Parallel の比較
現在、Parallel を使用することは、Bash コマンドを実行するための複雑な方法のように思えるかもしれません。しかし、あなたにとっての本当のメリットは時間の節約です。 Bash は 1 つの CPU コアでのみ実行されますが、GNU Parallel は一度に複数で実行されます。
1. 順次 Bash コマンドと並列の違いを示すために、test.sh という名前の Bash スクリプトを作成します。 次のコードで。このスクリプトは、count_file.txt を作成したのと同じディレクトリに作成します。 以前に。
以下の Bash スクリプトは count_file.txt を読み取ります ファイルを作成し、1、2、3、4、および 5 秒間スリープし、スリープの長さを端末にエコーして終了します。
#!/bin/bash
nums=$(cat count_file.txt) # Read count_file.txt
for num in $nums # For each line in the file, start a loop
do
sleep $num # Read the line and wait that many seconds
echo $num # Print the line
done
2. time を使用してスクリプトを実行します。 コマンドを使用して、スクリプトの完了にかかる時間を測定します。 15秒かかります。
time ./test.sh
3. 次に、time を使用します コマンドをもう一度実行して同じタスクを実行しますが、今回は Parallel を使用して実行します。
以下のコマンドは同じタスクを実行しますが、今回は最初のループが完了するのを待ってから次のループを開始するのではなく、各 CPU コアで 1 つずつ実行し、同時にできるだけ多くのループを開始します。
time cat count_file.txt | parallel "sleep {}; echo {}"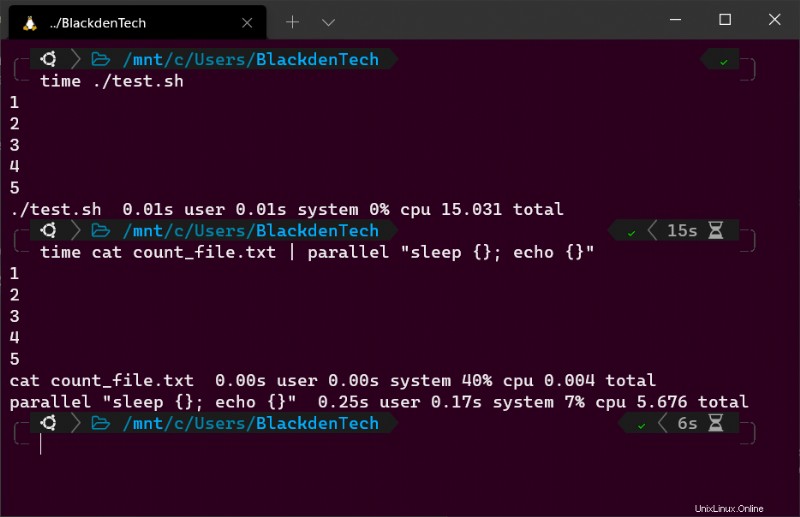
予行演習を知ろう!
いよいよ、実際の GNU Parallel の例に取り掛かります。ただし、その前に、まず --dryrun について知っておく必要があります。 国旗。このフラグは、Parallel が実際に実行せずに何が起こるかを確認したい場合に便利です。
--dryrun flag は、思ったように動作しないコマンドを実行する前の最終的な健全性チェックになる可能性があります。残念ながら、システムに損害を与えるコマンドを入力した場合、GNU Parallel が支援する唯一のことはシステムに損害を与えることだけです!
parallel --dryrun "rm rf {}"GNU 並列例 #1:Web からのファイルのダウンロード
このタスクでは、Web 上のさまざまな URL からファイルのリストをダウンロードします。たとえば、これらの URL は、保存する Web ページ、画像、または FTP サーバーからのファイルのリストを表すことができます。
この例では、GNU parallel の FTP サーバーからアーカイブ パッケージ (および SIG ファイル) のリストをダウンロードします。
1. download_items.txt という名前のファイルを作成します。 公式ダウンロード サイトからいくつかのダウンロード リンクを取得し、新しい行で区切ってファイルに追加します。
https://ftp.gnu.org/gnu/parallel/parallel-20120122.tar.bz2
https://ftp.gnu.org/gnu/parallel/parallel-20120122.tar.bz2.sig
https://ftp.gnu.org/gnu/parallel/parallel-20120222.tar.bz2
https://ftp.gnu.org/gnu/parallel/parallel-20120222.tar.bz2.sigPython の Beautiful Soup ライブラリを使用してダウンロード ページからすべてのリンクをスクレイピングすると、時間を節約できます。
2. download_items.txt からすべての URL を読み取ります wget を呼び出す Parallel に渡します。 各 URL を渡します。
cat download_items.txt | parallel wget {}
{}であることを忘れないでください 並列コマンドでは、入力文字列のプレースホルダーです!
3. おそらく、GNU Parallel が一度に使用するスレッドの数を制御する必要があります。その場合は、--jobs を追加します または -j コマンドにパラメーターを追加します。 --jobs パラメータは、同時に実行できるスレッドの数を指定した数に制限します。
たとえば、一度に 5 つの URL をダウンロードするように Parallel を制限するには、コマンドは次のようになります。
#!/bin/bash
cat download_items.txt | parallel --jobs 5 wget {}
--jobs上記のコマンドのパラメーターを調整して、実行しているコンピューターにそれらを処理するための多くの CPU がある限り、任意の数のファイルをダウンロードできます。
4. --jobs の効果を実証する パラメータ、ジョブ数を調整して time を実行 コマンドを使用して、各実行にかかる時間を測定します。
time cat download_items.txt | parallel --jobs 5 wget {}
time cat download_items.txt | parallel --jobs 10 wget {}GNU Parallel の例 #2:アーカイブ パッケージの解凍
前の例からこれらのアーカイブ ファイルをすべてダウンロードしたので、アーカイブを解除する必要があります。
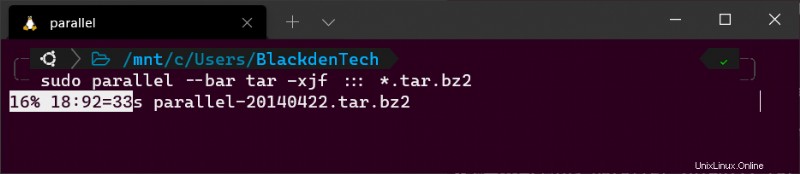
アーカイブ パッケージと同じディレクトリで、次の Parallel コマンドを実行します。ワイルドカード (*) の使用に注意してください )。このディレクトリには両方のアーカイブ パッケージが含まれているため、と .tar.bz2 のみを処理するよう Parallel に指示する必要があります。 ファイル。
sudo parallel tar -xjf ::: *.tar.bz2
ボーナス! GNU 並列を対話的に (スクリプトではなく) 使用している場合は、--bar を追加します。 タスクの実行中に Parallel にプログレス バーを表示させるフラグ
GNU 並列例 #3:ファイルの削除
例 1 と 2 に従った場合、作業ディレクトリに多くのフォルダがあり、スペースを占有しているはずです。それでは、これらのファイルをすべて並行して削除しましょう!
parallel- で始まるすべてのフォルダを削除するには Parallel を使用して、ls -d ですべてのフォルダーを一覧表示します これらの各フォルダー パスを Parallel にパイプし、rm -rf を呼び出します。 以下に示すように、各フォルダーに。
--dryrunを思い出してください フラグ!
ls -d parallel-*/ | parallel "rm -rf {}"結論
Bash を使用してタスクを自動化し、多くの時間を節約できるようになりました。その時間に何をするかはあなた次第です。時間を節約するということは、少し早く仕事を終えることでも、別の ATA ブログ投稿を読むことでもあります。時間はあなたの時代に戻っています。
ここで、環境内で長時間実行されるすべてのスクリプトについて考えてみましょう。 Parallel で高速化できるのはどれですか?