このチュートリアルでは、非常に重要な grepの使用方法を学習します。 Linuxのコマンド。このコマンドを習得することが重要である理由と、コマンドラインでの日常のタスクでこのコマンドをどのように利用できるかについて説明します。
説明と例をいくつか紹介してみましょう。
なぜgrepを使用するのですか?
Grepは、Linuxユーザーがテキストの文字列を検索するために使用するコマンドラインツールです。これを使用して、特定の単語または単語の組み合わせをファイルで検索したり、他のLinuxコマンドの出力をgrepにパイプ処理して、grepが表示する必要のある出力のみを表示したりできます。
いくつかの本当に一般的な例を見てみましょう。ディレクトリの内容をチェックして、特定のファイルがそこに存在するかどうかを確認する必要があるとします。これは、「ls」コマンドを使用するものです。
ただし、ディレクトリの内容をチェックするこのプロセス全体をさらに高速化するために、lsコマンドの出力をgrepコマンドにパイプすることができます。ホームディレクトリでDocumentsというフォルダを探しましょう。
それでは、ディレクトリをもう一度確認してみましょう。ただし、今回はgrepを使用してDocumentsフォルダを具体的に確認します。
$ ls | grep Documents
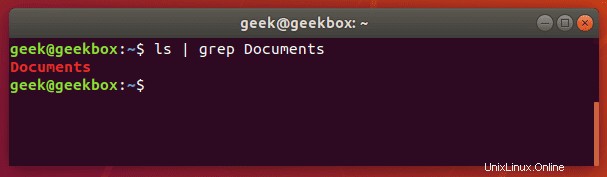
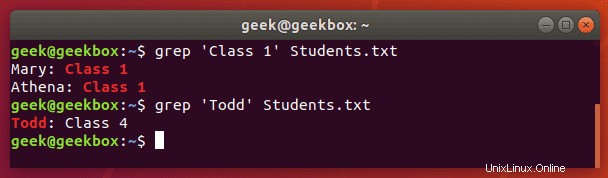
上のスクリーンショットでわかるように、grepコマンドを使用すると、検索した単語をlsコマンドが生成した残りの不要な出力からすばやく分離できるため、時間を節約できました。
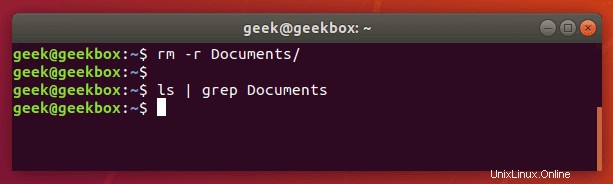
Documentsフォルダーが存在しなかった場合、grepは出力を返しませんでした。したがって、grepが何も返さない場合は、検索している単語が見つからなかったことを意味します。
文字列を検索
1つの単語だけでなく、テキストの文字列を検索する必要がある場合は、文字列を引用符で囲む必要があります。たとえば、1語の「Documents」ディレクトリではなく「MyDocuments」ディレクトリを検索する必要がある場合はどうなりますか?
$ ls | grep 'My Documents'
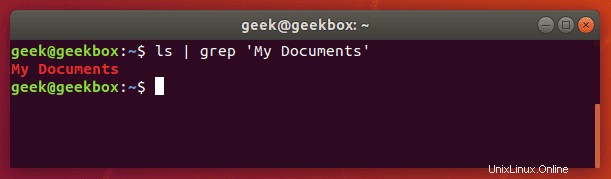
Grepは一重引用符と二重引用符の両方を受け入れるため、テキストの文字列をどちらかでラップします。
grepを使用して、他のコマンドラインツールからパイプされた出力を検索できますが、grepを使用してドキュメントを直接検索することもできます。これは、テキストドキュメントで文字列を検索する例です。
$ grep 'Class 1' Students.txt
複数の文字列を検索
grepを使用して、複数の単語または文字列を検索することもできます。 -eスイッチを使用して複数のパターンを指定できます。テキストドキュメントで2つの異なる文字列を検索してみましょう:
$ grep -e 'Class 1' -e Todd Students.txt
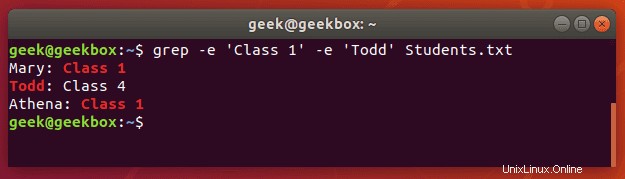
スペースを含む文字列を引用符で囲むだけでよいことに注意してください。
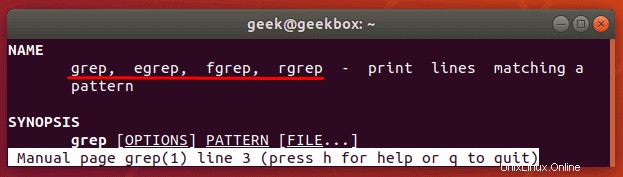
grep、egrep fgrep、pgrep、zgrepの違い
さまざまなgrepスイッチが歴史的にさまざまなバイナリに含まれていました。最近のLinuxシステムでは、これらのスイッチはbase grepコマンドで使用できますが、ディストリビューションが他のコマンドもサポートしているのが一般的です。
grepのマニュアルページから:
egrepはgrep-E
と同等ですこのスイッチは、パターンを拡張正規表現として解釈します。これを使用して実行できることはたくさんありますが、grepで正規表現を使用するとどのように見えるかの例を次に示します。
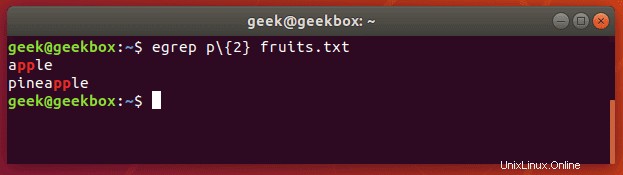
テキストドキュメントで、2つの連続する「p」文字を含む文字列を検索してみましょう。
$ egrep p\{2} fruits.txt または
$ grep -E p\{2} fruits.txt
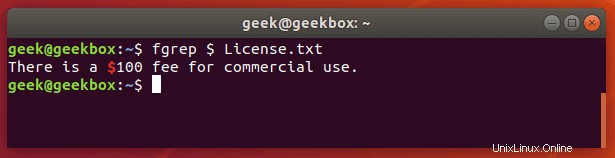
fgrepはgrep-F
と同等ですこのスイッチは、パターンを固定文字列のリストとして解釈し、それらのいずれかに一致させようとします。正規表現の文字を検索する必要がある場合に便利です。これは、通常のgrepのように特殊文字をエスケープする必要がないことを意味します。
pgrepは、システムで実行中のプロセスの名前を検索し、それぞれのプロセスIDを返すコマンドです。たとえば、これを使用してSSHデーモンのプロセスIDを見つけることができます。
$ pgrep sshd
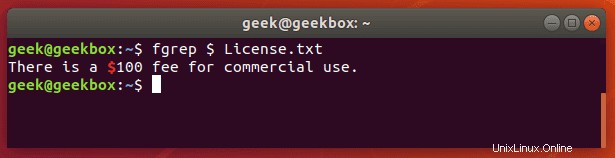
これは、「ps」コマンドの出力をgrepにパイプするだけの機能に似ています。
この情報を使用して、実行中のプロセスを強制終了したり、システムで実行されているサービスの問題をトラブルシューティングしたりできます。
zgrepを使用して、圧縮ファイルでパターンを検索できます。これにより、最初にアーカイブを解凍しなくても、圧縮されたアーカイブ内のファイルを検索できるため、基本的に1、2ステップ余分に節約できます。
$ zgrep apple fruits.txt.gz
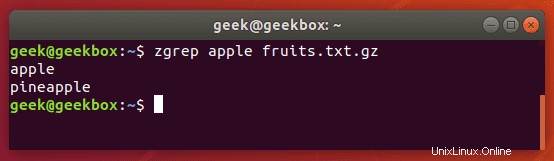
zgrepはtarファイルでも機能しますが、一致するものを見つけることができたかどうかを通知するだけのようです。
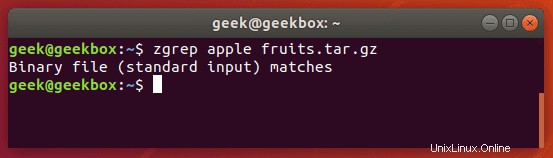
gzipで圧縮されたファイルは、非常に一般的にtarアーカイブであるため、これについて言及します。
findとgrepの違い
Linuxコマンドラインを使い始めたばかりの人にとって、findとgrepは、ユーザーが指定したものを「検索」するために両方を使用しますが、2つの非常に異なる機能を持つ2つのコマンドであることを覚えておくことが重要です。
チュートリアルの最初の例で示したように、ファイルを使用してlsコマンドの出力を検索する場合は、grepを使用してファイルを見つけると便利です。
ただし、ファイルの名前を再帰的に検索する必要がある場合、またはワイルドカード(アスタリスク)を使用する場合はファイル名の一部を検索する必要がある場合は、「検索」コマンドを使用する方がはるかに先です。
$ find /path/to/search -name name-of-file
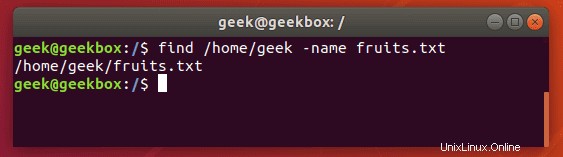
上記の出力は、findコマンドが検索したファイルを正常に見つけることができたことを示しています。
再帰的に検索
grepで-rスイッチを使用すると、ディレクトリ内のすべてのファイルとそのサブディレクトリで指定されたパターンを再帰的に検索できます。
$ grep -r pattern /directory/to/search
ディレクトリを指定しない場合、grepは現在の作業ディレクトリを検索するだけです。以下のスクリーンショットで、grepはパターンに一致する2つのファイルを見つけ、それらのファイル名とそれらが存在するディレクトリを返します。

キャッチスペースまたはタブ
文字列の検索方法の説明で前述したように、スペースが含まれている場合は、テキストを引用符で囲むことができます。同じ方法がタブでも機能しますが、grepコマンドにタブを配置する方法をすぐに説明します。
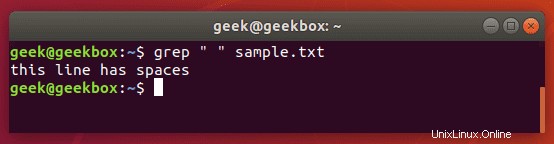
引用符の中に1つまたは複数のスペースを入れて、grepでその文字を検索します。
$ grep " " sample.txt
grepを使用してタブを検索する方法はいくつかありますが、ほとんどの方法は実験的なものであるか、さまざまなディストリビューション間で一貫性がない可能性があります。
最も簡単な方法は、タブ文字自体を検索することです。これは、キーボードのctrl + vを押してから、Tabキーを押すことで作成できます。
通常、ターミナルウィンドウでタブを押すと、コマンドをオートコンプリートするようにターミナルに通知されますが、事前にctrl + vの組み合わせを押すと、テキストエディタで通常期待されるようにタブ文字が書き出されます。 。
$ grep " " sample.txt
タブはコマンドを値から分離するために頻繁に使用されるため、この小さなトリックを知っていると、Linuxで構成ファイルを調べるときに特に役立ちます。
正規表現の使用
Grepの機能は正規表現を使用してさらに拡張され、検索の柔軟性が高まります。いくつか存在しますが、以下の例で最も一般的なものをいくつか見ていきます。
[]ブラケット 一連の文字のいずれかに一致するために使用されます。
$ grep "Class [123]" Students.txt
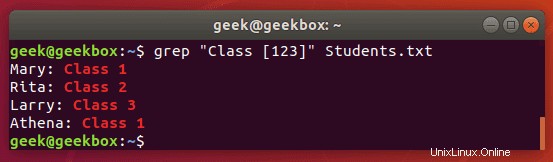
このコマンドは、「Class 1」、「Class2」、または「Class3」という行を返します。
[-]ハイフン付きの角かっこ 数字またはアルファベットの文字範囲を指定するために使用できます。
$ grep "Class [1-3]" Students.txt
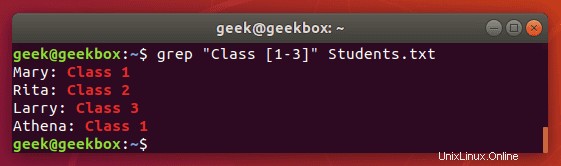
以前と同じ出力が得られますが、特に数字や文字の範囲が広い場合は、コマンドの入力がはるかに簡単になります。
^ キャレット 行の先頭でのみ発生するパターンを検索するために使用されます。
$ grep "^Class" Students.txt
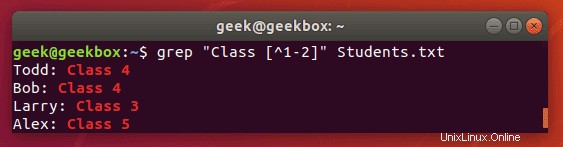
[^]キャレット付きブラケット 検索パターンから文字を除外するために使用されます。
$ grep "Class [^1-2]" Students.txt
$ドル記号 行末でのみ発生するパターンを検索するために使用されます。
$ grep "1$" Students.txt
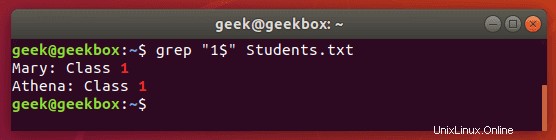
。ドット は任意の1文字に一致するために使用されるため、ワイルドカードですが、1文字のみです。
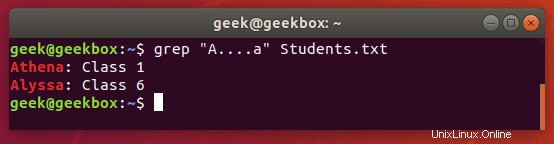
$ grep "A….a" Students.txt
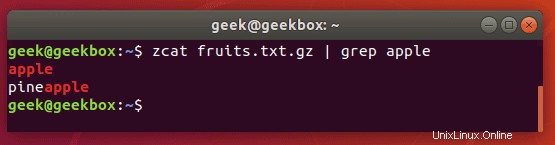
解凍せずにgrepgzファイル
前に示したように、zgrepコマンドを使用すると、最初に解凍しなくても圧縮ファイルを検索できます。
$ zgrep word-to-search /path/to/file.gz
zcatコマンドを使用してgzファイルの内容を表示し、その出力をgrepにパイプして、検索文字列を含む行を分離することもできます。
$ zcat file.gz | grep word-to-search
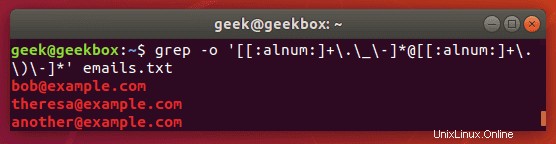
zipファイルからのGrepメールアドレス
派手な正規表現を使用して、zipファイルからすべてのメールアドレスを抽出できます。
$ grep -o '[[:alnum:]+\.\_\-]*@[[:alnum:]+\.\_\-]*' emails.txt
-oフラグは、メールアドレスをのみ抽出します。 、電子メールアドレスを含む行全体を表示するのではなく。これにより、出力がよりクリーンになります。
Linuxのほとんどのものと同様に、これを行うには複数の方法があります。 egrepと別の式のセットを使用することもできます。ただし、上記の例は問題なく機能し、メールアドレスを抽出して他のすべてを無視する非常に簡単な方法です。
GrepIPアドレス
ドットで区切られた4つの数字を検索するようにgrepに指示することはできないため、IPアドレスの取得は少し複雑になる可能性があります。できます ただし、そのコマンドは無効なIPアドレスも返す可能性があります。
次のコマンドは、のみを検索して分離します 有効なIPv4アドレス:
$ grep -E -o "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" /var/log/auth.log
これをUbuntuサーバーで使用して、最新のSSH試行がどこから行われたかを確認しました。
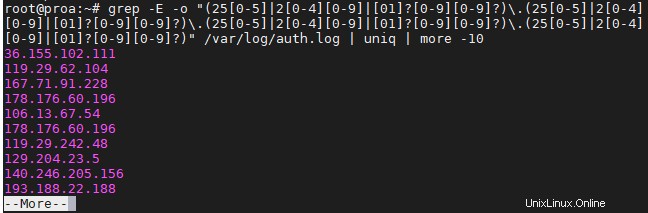
情報の繰り返しを避け、画面がいっぱいになるのを防ぐために、上のスクリーンショットで行ったように、grepコマンドを「uniq」と「more」にパイプすることをお勧めします。
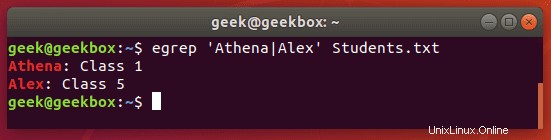
grepまたは状態
grepでor条件を使用する方法はいくつかありますが、必要なキーストロークが最も少なく、覚えやすい方法を紹介します。
$ grep -E 'string1|string2' filename
または、技術的にはegrepを使用すると、キーストロークがさらに少なくなります。
$ egrep 'string1|string2' filename
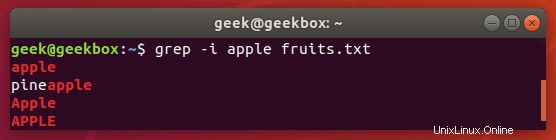
大文字と小文字の区別を無視する
デフォルトでは、grepでは大文字と小文字が区別されます。つまり、検索文字列の大文字と小文字を正確に指定する必要があります。 -iスイッチを使用してケースを無視するようにgrepに指示することで、これを回避できます。
$ grep -i string filename
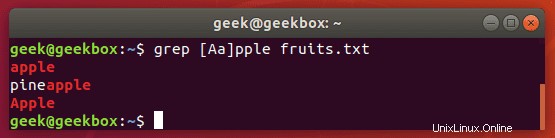
大文字と小文字を区別して検索
最初の文字列は大文字または小文字にすることができますが、残りの文字列は小文字にする必要がある文字列を検索する場合はどうなりますか?この場合、-iスイッチで大文字と小文字を区別しないと機能しないため、ブラケットを使用するのが簡単な方法です。
$ grep [Ss]tring filename
このコマンドは、最初の文字を除いて大文字と小文字を区別するようにgrepに指示します。
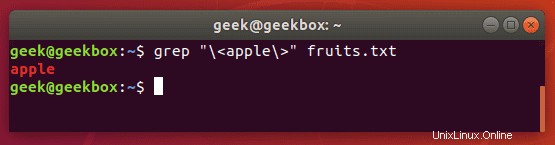
Grepの完全一致
上記の例では、ドキュメントで文字列「apple」を検索するたびに、grepは出力の一部として「pineapple」も返します。これを回避し、厳密に「アップル」を検索するには、次のコマンドを使用できます。
$ grep "\<apple\>" fruits.txt
-wスイッチを使用することもできます。これにより、文字列が行全体と一致する必要があることがgrepに通知されます。明らかに、これは、行の残りの部分にテキストがまったく含まれていないと予想される状況でのみ機能します。
パターンを除外する
ファイルの内容を表示し、出力からパターンを除外するには、-vスイッチを使用できます。
$ grep -v string-to-exclude filename
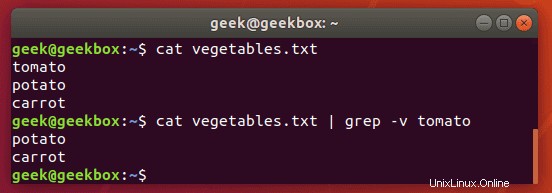
スクリーンショットでわかるように、-vスイッチを使用して同じコマンドを実行すると、除外した文字列は表示されなくなります。
grepと置換
sedにパイプされたgrepコマンドを使用して、ファイル内の文字列のすべてのインスタンスを置き換えることができます。このコマンドは、現在の作業ディレクトリに関連するすべてのファイルで「string1」を「string2」に置き換えます。
$ grep -rl 'string1' ./ | xargs sed -i 's/string1/string2/g'
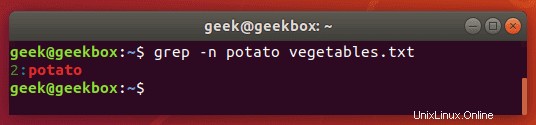
行番号付きのGrep
文字列を含む行番号を表示するには、-nスイッチを使用します。
$ grep -n string filename
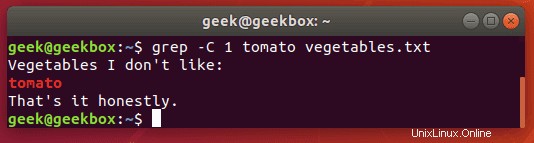
前後の線を表示
grep出力にもう少しコンテキストが必要な場合は、-cスイッチを使用して、指定した検索文字列の前後に1行を表示できます。
$ grep -c 1 string filename
表示する行数を指定します。この例では1行のみを実行しました。
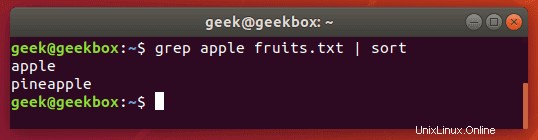
結果を並べ替える
greps出力をsortコマンドにパイプして、結果をある種の順序で並べ替えます。デフォルトはアルファベット順です。
$ grep string filename | sort
チュートリアルがお役に立てば幸いです。戻ってきてください。