Kubernetesは、コンテナ化されたワークロードとサービスを管理するためのオープンソースプラットフォームであり、宣言型の構成と自動化を容易にします。 Kubernetesという名前はギリシャ語に由来し、操舵手またはパイロットを意味します。ポータブルで拡張可能であり、急速に成長するエコシステムを備えています。 Kubernetesのサービスとツールは広く利用できます。
この記事では、Kubernetesの主要コンポーネントの10,000フィートのビューを、各コンテナーの構成から、ポッド内のコンテナーが各ワーカーにどのようにデプロイおよびスケジュールされるかについて説明します。コンテナ化されたアプリケーションのオーケストレーターとしてKubernetesに基づくソリューションをデプロイおよび設計できるようにするには、Kubernetesクラスターの詳細を完全に理解することが重要です。
この記事で取り上げる内容について簡単に説明します。
- コントロールパネルのコンポーネント
- Kubernetesワーカーのコンポーネント
- 基本的な構成要素としてのポッド
- Kubernetesサービス、ロードバランサー、Ingressコントローラー
- Kubernetesのデプロイとデーモンセット
- Kubernetesの永続ストレージ
Kubernetesコントロールプレーン
Kubernetesマスターノードは、コアコントロールプレーンサービスが存在する場所です。すべてのサービスが同じノードに存在する必要はありません。ただし、集中化と実用性のために、これらは多くの場合、この方法で展開されます。これは明らかにサービスの可用性の問題を引き起こします。ただし、複数のノードを用意し、負荷分散リクエストを提供して、可用性の高いマスターノードのセットを実現することで、簡単に克服できます。 。
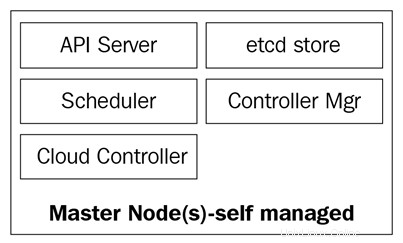
マスターノードは、次の4つの基本サービスで構成されています。
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- etcdデータベース
マスターノードは、ベアメタルサーバー、仮想マシン、またはプライベートクラウドまたはパブリッククラウドのいずれかで実行できますが、コンテナーワークロードを実行することはお勧めしません。これについては後で詳しく説明します。
次の図は、Kubernetesマスターノードのコンポーネントを示しています。
kube-apiserver
APIサーバーは、すべてを結び付けるものです。サービス、ポッド、イングレスなどのAPIオブジェクトを作成、更新、削除するためのマニフェストを受け取るのは、クラスターのフロントエンドRESTAPIです。
kube-apiserverは、私たちが話し合うべき唯一のサービスです。また、クラスターの状態を登録するためにetcdデータベースに書き込み、通信するのはこのデータベースだけです。 kubectlコマンドを使用して、コマンドを送信して操作します。 Kubernetesに関しては、これがスイスアーミーナイフになります。
kube-controller-manager
kube-controller-managerデーモンは、一言で言えば、単一のバイナリで簡単にするために出荷される一連の無限の制御ループです。クラスターの定義された望ましい状態を監視し、それを達成するために必要なすべてのビットとピースを移動することによって、それが達成され、満たされていることを確認します。 kube-controller-managerは1つのコントローラーだけではありません。これには、クラスター内のさまざまなコンポーネントを監視するいくつかの異なるループが含まれています。それらのいくつかは、サービスコントローラー、名前空間コントローラー、サービスアカウントコントローラー、およびその他の多くです。各コントローラーとその定義は、Kubernetes GitHubリポジトリ(https://github.com/kubernetes/kubernetes/tree/master/pkg/controller)にあります。
kube-scheduler
kube-schedulerは、新しく作成されたポッドを、ポッドのリソースニーズを満たすのに十分なスペースがあるノードにスケジュールします。基本的に、kube-apiserverとkube-controller-managerをリッスンして、キューに入れられ、スケジューラーによって使用可能なノードにスケジュールされた、新しく作成されたポッドを探します。 kube-schedulerの定義は、https://github.com/kubernetes/kubernetes/blob/master/pkg/schedulerにあります。
コンピューティングリソースに加えて、kube-schedulerはノードのアフィニティルールと非アフィニティルールを読み取り、ノードがそのポッドを実行できるかどうかを確認します。
etcdデータベースは、Kubernetesクラスタの状態を保存するために使用される、非常に信頼性の高い一貫性のあるKey-Valueストアです。これには、ノードが実行されているポッドの現在のステータス、クラスターに現在あるノードの数、それらのノードの状態、展開のレプリカの数、サービス名などが含まれます。
前述したように、kube-apiserverのみがetcdデータベースと通信します。 kube-controller-managerがクラスタの状態を確認する必要がある場合、etcdストアに直接クエリを実行する代わりに、etcdデータベースから状態を取得するためにAPIサーバーを経由します。ポッドが停止されたか、別のノードに割り当てられたことをスケジューラーが通知する必要がある場合、kube-schedulerでも同じことが起こります。 APIサーバーに通知し、APIサーバーは現在の状態をetcdデータベースに保存します。
etcdを使用して、Kubernetesマスターノードのすべての主要コンポーネントをカバーしたので、クラスターを管理する準備が整いました。しかし、クラスターはマスターだけで構成されているわけではありません。アプリケーションを実行することで手間のかかる作業を実行するノードが引き続き必要です。
Kubernetesワーカーノード
Kubernetesでこのタスクを実行するワーカーノードは、単にノードと呼ばれます。以前は2014年頃にミニオンと呼ばれていましたが、名前がソルトの用語と混同され、ソルトがKubernetesで主要な役割を果たしていると人々に思わせたため、この用語は後にノードのみに置き換えられました。
これらのノードは、クラスター全体を管理するために使用可能である必要があるため、マスターノードにコンテナーまたはロードを配置することは推奨されないため、ワークロードを実行する唯一の場所です。ノードはコンポーネントの点で非常に単純です。タスクを実行するために必要なサービスは3つだけです:
- Kubelet
- Kubeプロキシ
- コンテナランタイム
これらの3つのコンポーネントをもう少し詳しく見ていきましょう。
kubeletは低レベルのKubernetesコンポーネントであり、kube-apiserverに次ぐ最も重要なコンポーネントの1つです。これらのコンポーネントは両方とも、クラスター内のポッド/コンテナーのプロビジョニングに不可欠です。 kubeletは、Kubernetesノードで実行され、ポッド作成のためにAPIサーバーをリッスンするサービスです。 kubeletは、ポッド内のコンテナーの開始/停止と正常性の確認のみを担当します。 kubeletは、kubeletによって作成されていないコンテナを管理できなくなります。
kubeletは、コンテナランタイムインターフェース(CRI)を介してコンテナランタイムと通信することで、目標を達成します。 。 CRIは、さまざまなコンテナーランタイムと通信できるgRPCクライアントを介してkubeletにプラグイン可能性を提供します。先に述べたように、Kubernetesはコンテナをデプロイするために複数のコンテナランタイムをサポートしており、これがさまざまなエンジンに対するこのような多様なサポートを実現する方法です。
kubeletのソースコードはhttps://github.com/kubernetes/kubernetes/tree/master/pkg/kubeletで確認できます。
kube-proxy
kube-proxyは、クラスタの各ノードに存在するサービスであり、ポッド、コンテナ、ノード間の通信を可能にするサービスです。このサービスは、定義されたサービスの変更についてkube-apiserverを監視し(サービスはKubernetesの一種の論理ロードバランサーです。この記事の後半でサービスについて詳しく説明します)、トラフィックを転送するiptablesルールを介してネットワークを最新の状態に保ちます。正しいエンドポイント。 Kube-proxyは、サービスの背後にあるポッド間でランダムな負荷分散を行うiptablesのルールも設定します。
kube-proxyによって作成されたiptablesルールの例を次に示します。
-A KUBE-SERVICES -d 10.0.162.61 / 32 -p tcp -m comment --comment "default / example:has no endpoints" -m tcp --dport 80 -j REJECT --reject-with icmp-port-unreachable
これはエンドポイントのない(背後にポッドがない)サービスであることに注意してください。
コンテナを起動できるようにするには、コンテナランタイムが必要です。 。これは、ポッドを実行するためにノードカーネルにコンテナを作成するベースエンジンです。 kubeletはこのランタイムと通信し、必要に応じてコンテナを起動または停止します。
現在、Kubernetesは、Docker、rkt、runc、runscなどのOCI準拠のコンテナランタイムをサポートしています。
このhttps://github.com/opencontainers/runtime-specを参照して、OCIGit-Hubページからすべての仕様の詳細を確認できます。
クラスタを形成するすべてのコアコンポーネントについて説明したので、次に、それらを使用して何ができるか、Kubernetesがコンテナ化されたアプリケーションのオーケストレーションと管理にどのように役立つかを見てみましょう。
Kubernetesオブジェクト
Kubernetesオブジェクトは、まさにそのとおりです。これらは、クラスタの状態を表す論理的な永続オブジェクトまたは抽象化です。あなたは、Kubernetesにそのオブジェクトの望ましい状態を伝えて、オブジェクトを維持し、オブジェクトが存在することを確認できるようにする責任があります。
オブジェクトを作成するには、ステータスと仕様の2つが必要です。ステータスはKubernetesによって提供され、オブジェクトの現在の状態です。 Kubernetesは、必要に応じてそのステータスを管理および更新し、目的の状態に合わせます。一方、スペックフィールドは、Kubernetesに提供するものであり、必要なオブジェクトを説明するために指定するものです。たとえば、コンテナを実行するイメージ、実行するそのイメージのコンテナの数などです。
各オブジェクトには、実行するタスクのタイプに固有の仕様フィールドがあり、kubectlを使用してkube-apiserverに送信されるYAMLファイルでこれらの仕様を提供します。これにより、オブジェクトがJSONに変換され、APIリクエストとして送信されます。 。この記事の後半で、各オブジェクトとそのスペックフィールドについて詳しく説明します。
kubectlに送信されたYAMLの例を次に示します。
猫<
オブジェクト定義の基本フィールドは最初のフィールドであり、これらのフィールドはオブジェクトごとに異なることはなく、非常に自明です。それらを簡単に見てみましょう:
これで、最もよく使用されるフィールドとその内容について説明しました。 Kuberntes APIの規約について詳しくは、https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md
オブジェクトの一部のフィールドは、オブジェクトの作成後に後で変更できますが、それはオブジェクトと変更するフィールドによって異なります。
以下は、作成できるさまざまなKubernetesオブジェクトの短いリストです。
そして、もっとたくさんあります。
これらの各アイテムを詳しく見ていきましょう。
ポッドはKubernetesで最も基本的なオブジェクトであり、最も重要なオブジェクトでもあります。すべてがそれらを中心に展開します。 Kubernetesはポッド用であると言えます。他のすべてのオブジェクトはそれらを提供するためにここにあり、それらが行うすべてのタスクは、ポッドに目的の状態を実現させることです。
では、ポッドとは何ですか。また、ポッドが非常に重要なのはなぜですか。
ポッドは、同じネットワーク名前空間、同じプロセス間通信(IPC)で1つ以上のコンテナを一緒に実行する論理オブジェクトです。 また、Kubernetesのバージョンによっては、同じプロセスID(PID) 名前空間。これは、コンテナを実行するためにコンテナが注目されるためです。 Kubernetesの要点は、コンテナオーケストレーターになることです。ポッドを使用すると、オーケストレーションが可能になります。
前に述べたように、同じポッド上のコンテナは「バブル」内にあり、ローカルホストを介して相互にローカルであるため、相互に通信できます。ポッド内の1つのコンテナは、ネットワーク名前空間を共有しているため、他のコンテナと同じIPアドレスを持ちますが、ほとんどの場合、1対1で実行されます。つまり、ポッドごとに1つのコンテナが実行されます。 。ポッドごとに複数のコンテナが使用されるのは、アプリケーションがプライマリアプリケーションと高速かつ復元力のある方法で通信する必要があるデータプッシャーやプロキシなどのヘルパーを必要とする場合など、非常に特殊なシナリオでのみ使用されます。
ポッドを定義する方法は、他のKubernetesオブジェクトの場合と同じ方法です。つまり、すべてのポッドの仕様と定義を含むYAMLを使用します。
種類:PodapiVersion:v1metadata:name:hello-podlabels:hello:podspec:containers:-name:hello-container image:alpine args:--echo-"Hello World"
ポッドを作成するために、specフィールドで必要な基本的なポッド定義を確認してみましょう。
これらは、ポッドで宣言する最も基本的な仕様です。他の仕様では、それらの使用方法と、他のさまざまなKubernetesオブジェクトとの相互作用についてもう少し背景知識が必要になります。この記事の後半でそれらを再検討します。それらのいくつかは次のとおりです:
クラスタで現在実行されているポッドを表示するには、kubectlgetpodsを実行します。
[メールで保護]:〜$ kubectl get podsNAME READY STATUS RESTARTS AGEbusybox 1/1 Running 120 5d
または、ポッドを指定せずにkubectldescribepodsを実行することもできます。これにより、クラスターで実行されているすべてのポッドの説明が出力されます。この場合、現在実行されているのはビジーボックスポッドのみであるため、これはビジーボックスポッドのみになります。
[メールで保護]:〜$ kubectl describe podsName:busyboxNamespace:defaultPriority:0PriorityClassName:
ポッドは致命的です。一度死ぬか削除されると、それらを回復することはできません。そのIPとその上で実行されていたコンテナはなくなります。それらは完全に一時的なものです。ボリュームとしてマウントされているポッドのデータは、セットアップ方法に応じて、存続する場合と存続しない場合があります。ポッドが停止して失われた場合、すべてのマイクロサービスが実行されていることをどのように確認しますか?ええと、展開が答えです。
アプリケーションの複数のインスタンスを単一のポッドで実行することはあまり効率的ではないため、ポッド自体はあまり有用ではありません。アプリケーションの何百ものコピーを、それらすべてを探す方法がなくても、さまざまなポッドにプロビジョニングすると、すぐに手に負えなくなります。
ここで、展開が機能します。デプロイでは、コントローラーを使用してポッドを管理できます。これにより、実行する数を決定できるだけでなく、コンテナーが実行しているイメージのバージョンまたはイメージ自体を変更することで更新を管理することもできます。デプロイメントは、ほとんどの場合に使用するものです。デプロイ、ポッド、および前述したその他のオブジェクトでは、YAMLファイル内に独自の定義があります:
apiVersion:apps / v1kind:Deploymentmetadata:name:nginx-deploymentlabels:deployment:nginxspec:replicas:3セレクター:matchLabels:app:nginx template:metadata:labels:app:nginx spec:containers:-name:n x 1.7.9ポート:-containerPort:80
それらの定義を調べ始めましょう。
YAMLの最初には、apiVersion、kind、metadataなどのより一般的なフィールドがあります。ただし、仕様の下には、このAPIオブジェクトの特定のオプションがあります。
仕様の下で、次のフィールドを追加できます:
セレクター :[セレクター]フィールドを使用すると、デプロイメントは、変更が適用されたときにターゲットにするポッドを認識します。セレクターの下で使用するフィールドは、matchLabelsとmatchExpressionsの2つです。 matchLabelsを使用すると、セレクターはポッドのラベル(キーと値のペア)を使用します。ここで指定するすべてのラベルがANDで囲まれることに注意してください。つまり、ポッドには、matchLabelsで指定したすべてのラベルが含まれている必要があります。
レプリカ :これは、レプリケーションコントローラーを介してデプロイを実行し続けるために必要なポッドの数を示します。たとえば、3つのレプリカを指定し、ポッドの1つが停止した場合、ポッドが停止してから現在のステータスが2になるため、レプリケーションコントローラーはレプリカの仕様を目的の状態として監視し、スケジューラーに新しいポッドをスケジュールするように通知します。
RevisionHistoryLimit :デプロイメントに変更を加えるたびに、この変更はデプロイメントのリビジョンとして保存され、後でその前の状態に戻すか、変更内容の記録を保持することができます。履歴は、kubectlのロールアウト履歴のデプロイ/<デプロイの名前>で確認できます。 RevisionHistoryLimitを使用すると、保存するレコードの数を示す数値を設定できます。
戦略 :これにより、更新または水平ポッドスケールをどのように処理するかを決定できます。デフォルトのrollingUpdateを上書きするには、typeキーを記述する必要があります。このキーでは、recreateまたはrollingUpdateの2つの値から選択できます。
再作成はデプロイを更新するための迅速な方法ですが、すべてのポッドを削除して新しいポッドに置き換えますが、このタイプの戦略ではシステムのダウンタイムが発生することを考慮する必要があることを意味します。一方、rollingUpdateはスムーズで低速であり、データのバランスを取り直すことができるステートフルアプリケーションに最適です。 rollingUpdateは、maxSurgeとmaxUnavailableの2つのフィールドへの扉を開きます。
1つ目は、更新を実行するときに必要な合計量を超えるポッドの数です。たとえば、100個のポッドと20%のmaxSurgeを使用したデプロイでは、更新中に最大120個のポッドまで拡張されます。次のオプションでは、100ポッドのシナリオでポッドを新しいものと交換するために、殺しても構わないと思っているポッドの数を選択できます。 maxUnavailableが20%の場合、残りのデプロイメントの置き換えを続行する前に、20個のポッドのみが強制終了され、新しいポッドに置き換えられます。
テンプレート :これは、デプロイが管理するポッドのすべての仕様とメタデータを含める、ネストされたポッド仕様フィールドです。
展開により、ポッドを管理し、ポッドを希望の状態に維持するのに役立ちます。これらのポッドはすべて、まだクラスターと呼ばれるものにあります ネットワーク 、これは、Kubernetesクラスタコンポーネントのみが相互に通信できるクローズドネットワークであり、独自のIP範囲のセットを持っている場合でも同様です。外部からポッドとどのように話しますか?アプリケーションに到達するにはどうすればよいですか?ここでサービスが役立ちます。
サービス :
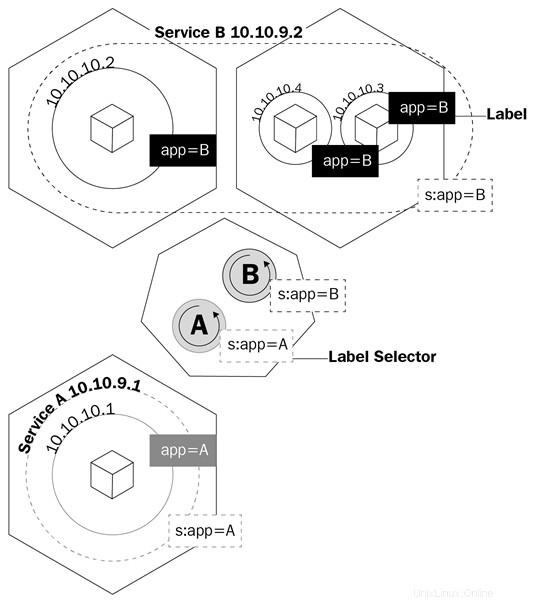
名前サービス Kubernetesで実際にサービスが行うことを完全には説明していません。 Kubernetesサービスは、トラフィックをポッドにルーティングするものです。サービスはポッドを結び付けるものであると言えます。
フロントエンドポッドがポッドのIPアドレスを介してバックエンドポッドと通信する、典型的なフロントエンド/バックエンドタイプのアプリケーションがあると想像してみてください。バックエンドのポッドが停止すると、バックエンドとの通信が失われます。これは、新しいポッドが停止したポッドと同じIPアドレスを持たないためだけでなく、新しいIPアドレスを使用するようにアプリを再構成する必要があるためです。この問題と同様の問題はサービスで解決されます。
サービスは、サービスの背後にあるポッドに基づいてiptablesルールを作成するようにkubeプロキシに指示する論理オブジェクトです。サービスはエンドポイントを構成します。これは、サービスの背後にあるポッドが呼び出される方法です。これは、デプロイが制御するポッド、セレクタフィールド、ポッドのラベルを認識するのと同じ方法です。
この図は、サービスがラベルを使用してトラフィックを管理する方法を示しています。
サービスは、kube-proxyにトラフィックをルーティングするためのルールを作成させるだけではありません。また、kube-dnsと呼ばれるものもトリガーされます。
Kube-dnsは、クラスタ上で実行されるSkyDNSコンテナを備えたポッドのセットであり、DNSサーバーとフォワーダーを提供します。これにより、サービスのレコードが作成され、場合によってはポッドが使いやすくなります。サービスを作成するたびに、サービスの内部クラスタIPアドレスを指すDNSレコードが、service-name.namespace.svc.cluster.localの形式で作成されます。 Kubernetes DNS仕様の詳細については、https://github.com/kubernetes/dns/blob/master/docs/specification.mdをご覧ください。
例に戻ると、サービスと通信するようにアプリケーションを構成するだけで済みます。完全修飾ドメイン名(FQDN) バックエンドポッドと通信するため。このように、ポッドとサービスがどのIPアドレスを持っているかは関係ありません。サービスの背後にあるポッドが停止した場合、すべてのトラフィックをmy-svcにルーティングするようにフロントエンドに指示できるため、サービスはAレコードを使用してすべてを処理します。サービスのロジックが他のすべてを処理します。
Kubernetesで作成するオブジェクトを宣言するときはいつでも、作成できるサービスにはいくつかの種類があります。それらを調べて、必要な作業の種類に最適なものを確認しましょう。
ClusterIP :これはデフォルトのサービスです。 ClusterIPサービスを作成すると、Kubernetesクラスター内でのみルーティング可能なクラスター内部IPアドレスを使用してサービスが作成されます。このタイプは、相互に通信するだけでクラスターの外に出ないポッドに最適です。
NodePort :このタイプのサービスを作成すると、デフォルトで30000から32767までのランダムなポートが割り当てられ、サービスのエンドポイントポッドにトラフィックが転送されます。ポート配列でノードポートを指定することで、この動作をオーバーライドできます。これが定義されると、
LoadBalancer :ほとんどの場合、クラウドプロバイダーでKubernetesを実行します。 LoadBalancerタイプは、クラウドプロバイダーのAPIを介してパブリックIPアドレスをサービスに割り当てることができるため、これらの状況に最適です。これは、クラスターの外部からポッドと通信する場合に理想的なサービスです。 LoadBalancerを使用すると、パブリックIPアドレスを割り当てるだけでなく、Azureを使用して、仮想プライベートネットワークからプライベートIPアドレスを割り当てることができます。したがって、インターネットから、またはプライベートサブネットの内部でポッドと通信できます。
YAMLのサービスの定義を確認しましょう:
apiVersion:v1kind:Servicemetadata:name:my-servicespec:selector:app:フロントエンドタイプ:NodePortポート:-name:httpポート:80 targetPort:8080 nodePort:30024プロトコル:TCP
サービスのYAMLは非常に単純であり、作成するサービスのタイプに応じて仕様が異なります。しかし、考慮しなければならない最も重要なことは、ポートの定義です。これらを見てみましょう:
クラスタ内のポッドと通信する方法は理解できましたが、ポッドが終了するたびにデータが失われるという問題をどのように管理するかを理解する必要があります。ここが永続的です ボリューム ( PV )が使用されるようになります。
コンテナの世界での永続的なストレージは深刻な問題です。コンテナの実行全体で永続する唯一のストレージはイメージのレイヤーであり、それらは読み取り専用です。コンテナーが実行されるレイヤーは読み取り/書き込みですが、コンテナーが停止すると、このレイヤーのすべてのデータが削除されます。ポッドの場合、これは同じです。コンテナが停止すると、コンテナに書き込まれたデータは失われます。
Kubernetesには、ポッド間のストレージを処理するためのオブジェクトのセットがあります。最初に説明するのはボリュームです。
ボリュームは、永続ストレージに関して最大の問題の1つを解決します。まず第一に、ボリュームは実際にはオブジェクトではなく、ポッドの仕様の定義です。ポッドを作成するときに、ポッドのスペックフィールドでボリュームを定義できます。このポッド内のコンテナーは、マウント名前空間にボリュームをマウントでき、コンテナーの再起動またはクラッシュ時にボリュームを使用できるようになります。ただし、ボリュームはポッドに関連付けられており、ポッドが削除されると、ボリュームも削除されます。ボリュームのデータは別の話です。データの永続性は、そのボリュームのバックエンドに依存します。
Kubernetesは、ローカルノードのファイルシステムマップ、クラウドプロバイダーの仮想ディスク、ソフトウェア定義のストレージバックアップボリュームなど、いくつかのタイプのボリュームまたはボリュームソースとそれらがAPI仕様で呼び出される方法をサポートしています。ローカルファイルシステムのマウントは、通常のボリュームに関して最も一般的なものです。ローカルノードファイルシステムを使用することの欠点は、データがクラスターのすべてのノードで利用できるわけではなく、ポッドがスケジュールされたノードでのみ利用できることです。
ボリュームのあるポッドがYAMLでどのように定義されているかを調べてみましょう:
apiVersion:v1kind:Podmetadata:name:test-pdspec:containers:-image:k8s.gcr.io/test-webserver name:test-container volumeMounts:-mountPath:/ test-pd name:test-volume volume:-name: test-volume hostPath:path:/ data type:Directory
仕様に基づいてボリュームと呼ばれるフィールドがあり、次にボリュームマウントと呼ばれるフィールドがあることに注意してください。
最初のフィールド(ボリューム)は、そのポッド用に作成するボリュームを定義する場所です。このフィールドには常に名前が必要で、次にボリュームソースが必要です。ソースに応じて、要件は異なります。この例では、ソースはノードのローカルファイルシステムであるhostPathになります。 hostPathは、ディレクトリ、ファイル、ブロックデバイス、さらにはUnixソケットに至るまで、いくつかのタイプのマッピングをサポートしています。
2番目のフィールドvolumeMountsの下に、mountPathがあります。これは、ボリュームをマウントするコンテナ内のパスを定義する場所です。 nameパラメータは、使用するボリュームをポッドに指定する方法です。ボリュームの下に複数のタイプのボリュームを定義できるため、これは重要です。名前は、ポッドがどれを知るための唯一の方法になります
さまざまなタイプのボリュームについて詳しくは、https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumesとKubernetes APIリファレンスドキュメント(https://kubernetes.io/docs)をご覧ください。 /reference/generated/kubernetes-api/v1.11/#volume-v1-core)。
ボリュームがポッドで死ぬのは理想的ではありません。持続するストレージが必要であり、これがPVの必要性につながった理由です。
ボリュームとPVの主な違いは、ボリュームとは異なり、PVは実際にはKubernetes APIオブジェクトであるため、個別のエンティティのように個別に管理できるため、ポッドが削除された後も存続することです。
このサブセクションにPVがあり、永続的である理由について疑問に思われるかもしれませんが、 ボリューム 主張 (PVC )、ストレージクラスはすべて混在しています。これは、すべてが相互に依存しているためです。ポッドのストレージをプロビジョニングするには、ストレージクラスが相互にどのように相互作用するかを理解することが重要です。
PVとPVCから始めましょう。 Like volumes, PVs have a storage source, so the same mechanism that volumes have applies here. You will either have a software-defined storage cluster providing a logical unit number (LUN ), a cloud provider giving virtual disks, or even a local filesystem to the Kubernetes node, but here, instead of being called volume sources, they are called persistent volume types instead.
PVs are pretty much like LUNs in a storage array:you create them, but without a mapping; they are just a bunch of allocated storage waiting to be used. PVCs are like LUN mappings:they are backed or bound to a PV and also are what you actually define, relate, and make available to the pod that it can then use for its containers.
The way you use PVCs on pods is exactly the same as with normal volumes. You have two fields:one to specify which PVC you want to use, and the other one to tell the pod on which container to use that PVC.
The YAML for a PVC API object definition should have the following code:
apiVersion:v1kind:PersistentVolumeClaimmetadata:name:gluster-pvc spec:accessModes:- ReadWriteMany resources: requests: storage:1Gi
The YAML for pod should have the following code:
kind:PodapiVersion:v1metadata:name:mypodspec:containers: - name:myfrontend image:nginx volumeMounts: - mountPath:"/mnt/gluster" name:volume volumes: - name:volume persistentVolumeClaim: claimName:gluster-pvc
When a Kubernetes administrator creates PVC, there are two ways that this request is satisfied:
Storage classes are like a way of tiering your storage. You can create a class that provisions slow storage volumes, or another one with hyper-fast SSD drives. However, storage classes are a little bit more complex than just tiering. As we mentioned in the two ways of creating PVC, storage classes are what make dynamic provisioning possible. When working on a cloud environment, you don't want to be manually creating every backend disk for every PV. Storage classes will set up something called a provisioner , which invokes the volume plug-in that's necessary to talk to your cloud provider's API. Every provisioner has its own settings so that it can talk to the specified cloud provider or storage provider.
You can provision storage classes in the following way; this is an example of a storage class using Azure-disk as a disk provisioner:
kind:StorageClassapiVersion:storage.k8s.io/v1metadata:name:my-storage-classprovisioner:kubernetes.io/azure-diskparameters:storageaccounttype:Standard_LRS kind:Shared
Each storage class provisioner and PV type will have different requirements and parameters, as well as volumes, and we have already had a general overview of how they work and what we can use them for. Learning about specific storage classes and PV types will depend on your environment; you can learn more about each one of them by clicking on the following links:
In this article, we learned about what Kubernetes is, its components, and what are the advantages of using orchestration are. With this, identifying each of Kubernetes API objects, their purpose and their use cases should be easy. You should now be able to understand how the master nodes control the cluster and the scheduling of the containers in the worker nodes.
If you found this article useful, ‘ Hands-On Linux for Architects ’ should be helpful for you. With this book, you will be covering everything from Linux components and functionalities to hardware and software support, which will help you implementing and tuning effective Linux-based solutions. You will be taken through an overview of Linux design methodology and core concepts of designing a solution. If you’re a Linux system administrator, Linux support engineer, DevOps engineer, Linux consultant or anyone looking to learn or expand their knowledge in architecting, this book is for you.
ポッド–Kubernetesの基盤
Kubernetesと永続ストレージ
永続ボリューム、永続ボリュームクレーム、およびストレージクラス