Linuxのheadコマンドは、最初のN行を読み取って標準出力に出力します。デフォルトでは、ファイルの最初の10行が標準出力に出力されます。ただし、これはコマンドラインで追加の引数を渡すことで変更できます。 「head」コマンドは、特定のファイルの最後のN行を出力するtailコマンドの反対です。このガイドでは、Linuxのheadコマンドに焦点を当て、コマンドのいくつかの使用例を紹介します。
構文:
headコマンドは次の構文を取ります:
$head[options]ファイル
1)ファイルの最初の10行を表示します
はじめに説明したように、headコマンドは、引数なしで、ファイルの最初の10行を表示します。以下の例では、アジア大陸の国のリストを含むサンプルテキストファイル(asian_countries.txt)があります。
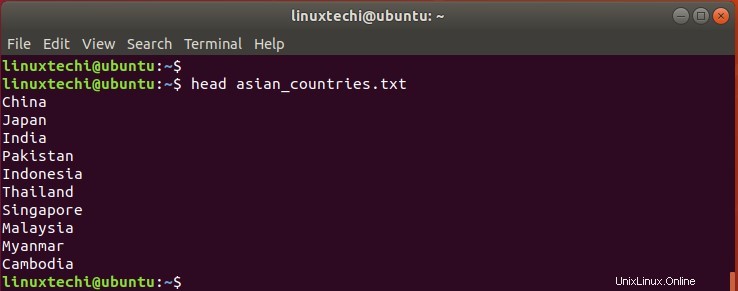
ファイルの最初の10か国を一覧表示するには、次のコマンドを実行します。
$ head asian_countries.txt
2)ファイル名タグを表示する
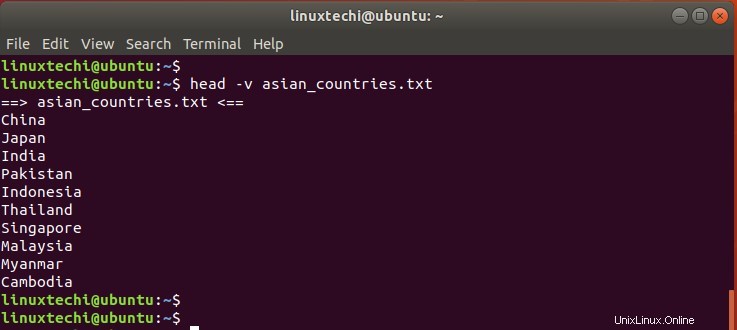
-vフラグを使用すると、次のようにファイルの行を印刷する前にファイル名タグを表示できます。
$ head -v asian_countries.txt
3)複数のファイルからの出力を表示する
さらに、以下に示すように、1つのコマンドで複数のファイルを渡すことができます。今回は、各テキストファイルの名前が最初に印刷され、最初のファイルの出力が次のファイルの前に表示されます。
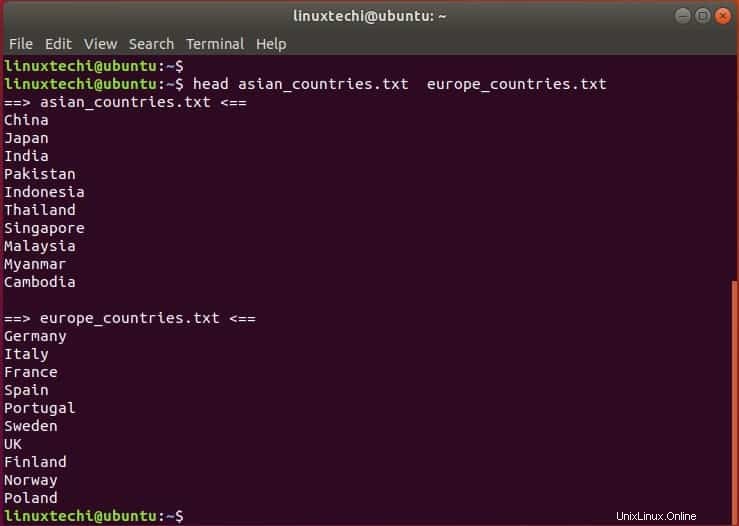
以下の例では、asian_countries.txtとeurope_countries.txtの2つのテキストファイルがあります。 asian_countries.txtファイルの出力が最初に出力され、次にeurope_countries.txtファイルが出力されます。行の前にファイル名タグがあることに注意してください。
$ head asian_countries.txt europe_countries.txt
上記のheadコマンドは、各ファイルの最初の10行を表示します。
4)最初のN行を表示します
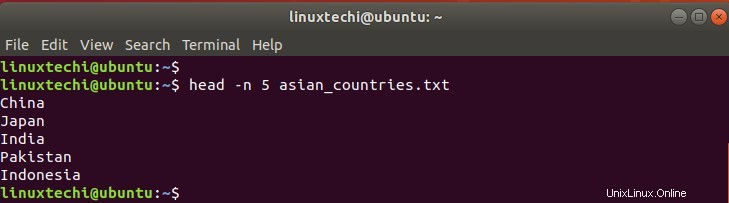
-nフラグに続けて印刷する行数を使用して、表示する行を定義できます。たとえば、最初の5行を印刷するには、次のコマンドを実行します。
$ head -n 5 asian_countries.txt
5)出力をテキストファイルにリダイレクトします
標準出力に出力する代わりに、リダイレクト演算子(>)を使用して、headコマンドの出力をテキストファイルまたはログファイルに保存できます。ファイルが存在しない場合は、ファイルが作成され、出力が保存されます。これにより、ファイル内のすべてが上書きされることに注意してください。
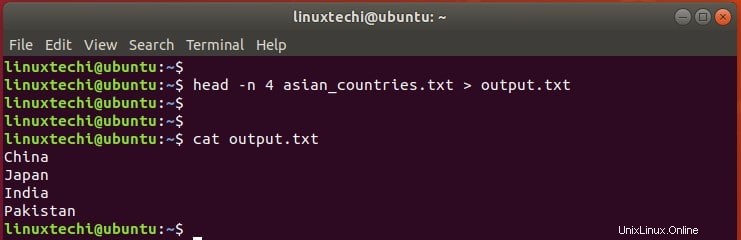
以下のコマンドは、asian_countriesテキストファイルの最初の4行の出力をoutput.txtファイルに保存します
$ head -n 4 asian_countries.txt > output.txt
ファイルが上書きされないようにするには、doubleより大きい演算子(>>)を使用して、出力をファイルに追加します。
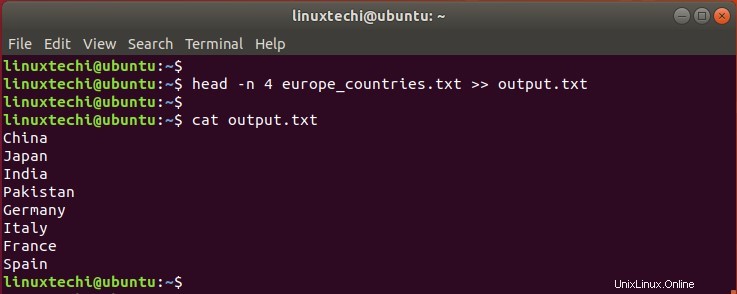
以下のコマンドでは、europe_countriesテキストファイルの最初の4行の出力を、上書きせずにoutput.txtファイルに追加しています。
$ head -n 4 europe_countries.txt >> output.txt
catコマンドを使用して、ファイルにアジアの国とヨーロッパの国の出力がどのように含まれているかを観察します。
6)パイプでheadコマンドを使用します
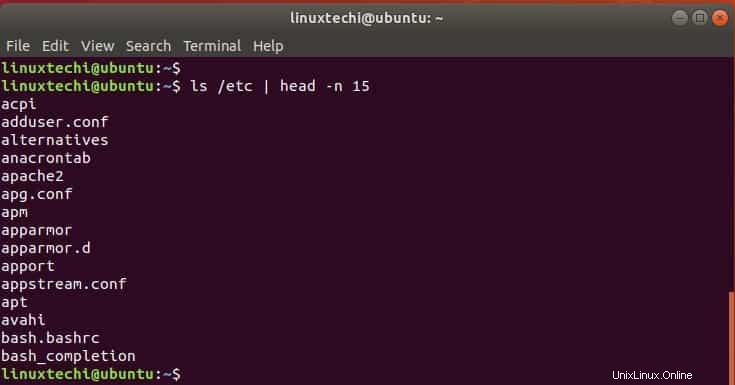
コマンドをヘッドにパイプして、N行を印刷できます。たとえば、次のように/etcディレクトリの最初の15エントリを出力できます。
$ ls /etc | head -n 15
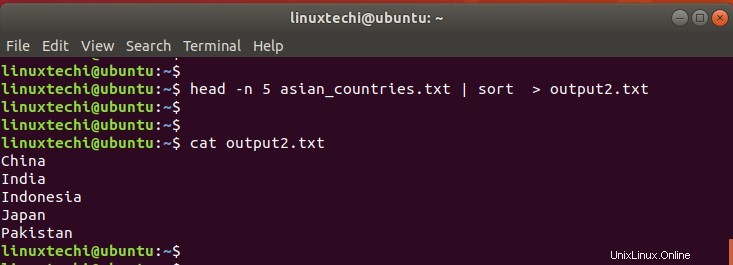
また、headコマンドの出力をsortコマンドなどの他のコマンドにパイプして、フォーマットを改善することもできます。
$ head -n 5 asian_countries.txt | sort > output2.txt
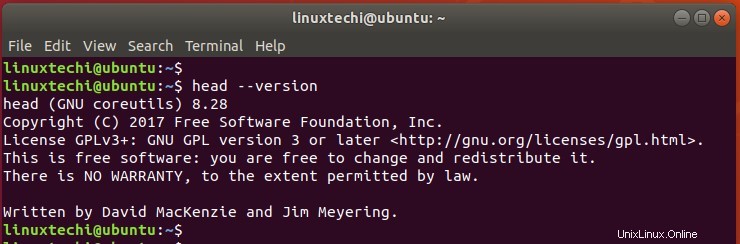
7)headコマンドのバージョンを確認してください
headコマンドのバージョンを確認するには、以下のコマンドを呼び出します。
$ head --version
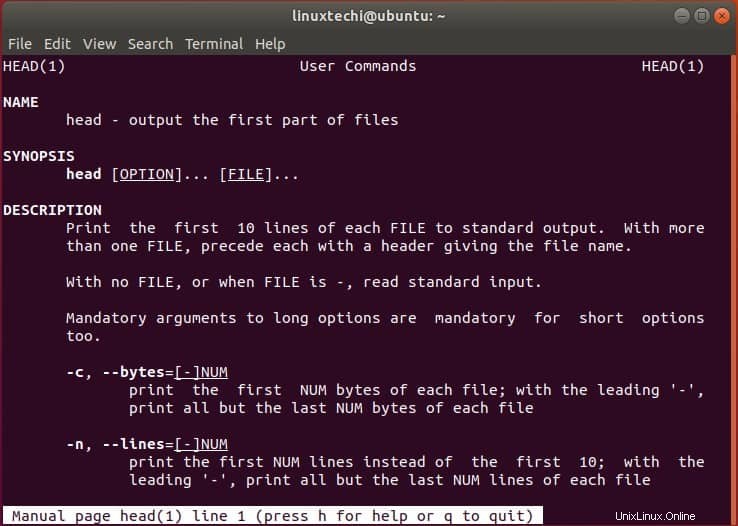
8)追加のオプションを取得する
コマンドの使用法についてヘルプが必要な場合は、図のようにマニュアルページにアクセスしてください。
$ man head
ここまで来てくれてありがとう。このチュートリアルが明らかになり、Linuxのheadコマンドの使用に関する混乱がなくなることを願っています。
また読む :Linuxでの9つのteeコマンドの例