はじめに
カット commandは、指定されたファイルまたはパイプされたデータのセクションを切り取り、その結果を標準出力に出力できるコマンドラインユーティリティです。このコマンドは、行の一部をフィールド、区切り文字、バイト位置、および文字で切り取ります。
このチュートリアルでは、カットについて学習します コマンドとその使用方法。

前提条件
- Linuxを実行しているシステム。
- 端末へのアクセス。
cutコマンド構文
カット コマンドは次の構文を取ります:
cut [option] [file]オプション
[option]を指定する 必要です。それ以外の場合、コマンドはエラーを出力します。使用可能なオプションについては、次のセクションで説明します。
ファイル
[file]の場合 、処理するファイルの名前を入力します。ファイル名を指定しないと、 cutに指示されます 標準入力から読み取るコマンド。この場合、 cut パイプラインをフィルタリングします。複数のファイル名を指定する場合は、 cut コマンドは、要求されたコンテンツを連結します。
cutコマンドオプション
カット コマンドオプションは、区切り文字の使用、バイト位置、フィールド、または文字による切り取りに関する指示を提供します。 カットごとに1つのオプションを使用します 実行するコマンド。
利用可能なオプションは次のとおりです。
| オプション | 説明 |
|---|---|
-f(--fields =LIST) | 指定されたフィールド、フィールドセット、またはフィールド範囲を使用して選択します。 |
-b(--bytes =LIST) | 指定されたバイト、バイトセット、またはバイト範囲を使用して選択します。 |
-c(--characters =LIST) | 指定した文字、文字セット、または文字範囲を使用して選択します。 |
-d(--delimiter) | デフォルトのTAB区切り文字の代わりに使用する区切り文字を指定するために使用されます。 |
-補完 | 指定すると、このオプションは cutに指示します 選択したものを除くすべてのバイト、文字、またはフィールドを表示します。 |
-s(--only-delimited) | デフォルト設定では、区切り文字を含まない行が印刷されます。 -sを指定する オプションは、区切り文字を含まない行を印刷しないようにcutに指示します。 |
-output-delimiter | デフォルトでは、カット 入力区切り文字を出力区切り文字として使用します。 -output-delimiterの指定 オプションを使用すると、別の出力区切り文字を指定できます。 |
-f 、 b 、および -c オプションはLISTを取ります 次のいずれかである引数:
- 整数
N1から始まるバイト、フィールド、または文字を表します。 - 複数の整数、カンマ区切り。
- 整数の範囲。
- 複数の整数範囲、カンマ区切り。
各範囲は、次のいずれかになります。
-
N--整数Nから始まります (フィールド、バイト、または文字)行末まで。 -
N-M-整数からN最大整数M、包括的。 -
-M-最初のフィールド、バイト、または文字から、指定されたMまで フィールド、バイト、または文字。
Linuxカットの例
以下は、最も一般的なカットです。 コマンドの使用例。
重要: 処理しているファイル/コマンド出力のロケールに注意してください。問題の文字が1バイトより長い場合、英語以外の言語で文字またはバイトを切り取ると、誤った出力が生成される可能性があります。
バイト単位でカット
-b オプションを使用すると、バイトを使用してデータを抽出できます。構文は次のとおりです。
cut -b [LIST] [file]
[LIST] 引数は、 [file]の各行から抽出するバイトです。 。
抽出する対象に応じて、1バイト、複数バイト、またはバイト範囲を切り取ることができます。特定のファイルから切り取るには、コマンドの最後にファイル名を指定します。たとえば、 employees.txtを使用します テスト用:
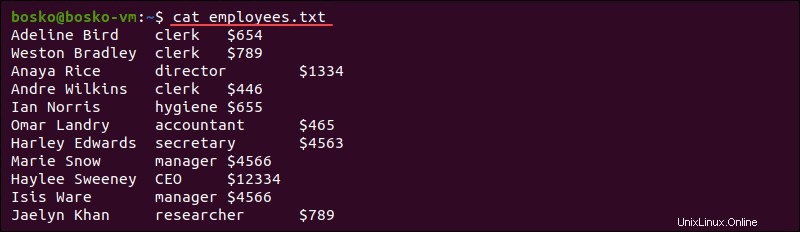
各入力行から最初のバイトを抽出するには、次のコマンドを実行します。
cut -b 1 employees.txt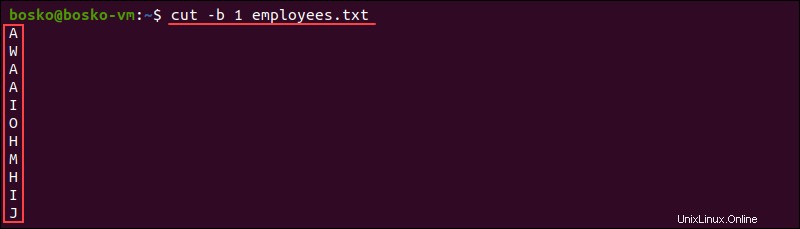
このコマンドは、各ファイル入力行の最初のバイトのみを出力します。
次の例は、whoコマンドにパイプして、出力から最初の5バイトを抽出する方法を示しています。
who | cut -b -5
文字による切り取り
文字で切り取るには、 -cを指定します オプション。文字による切り取りは、バイトによる切り取りと似ていますが、バイト位置ではなく文字位置を指定する必要がある点が異なります。構文は次のとおりです。
cut -c [LIST] [file]
[LIST] 引数は、 [file]の各行から抽出される文字を指定します 。
例:
cut -c 10- employees.txt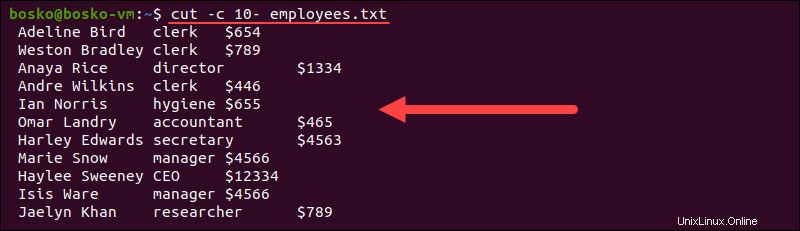
このコマンドは、 employees.txt の各行から、文字10から行末までのすべてを抽出します。 。結果は標準出力で印刷されます。
次の例は、ファイルが指定されておらず、 cutの場合の結果を示しています。 標準入力から入力を読み取ります。 誰がを見てください コマンド出力:

出力は、1人のユーザーが現在ログインしていることを示しています。 cutを使用してください whoからログインユーザーのユーザー名を抽出するコマンド コマンドの出力:
who | cut -c 1-8
上記の例では、 cutに指示します 入力の各行から文字1から8を抽出します。複数の結果がある場合は、コマンドに|を追加して結果を並べ替えます。並べ替え 。
さらに、 cutを使用します 行から複数の異なる文字を抽出します。たとえば、ログインしているすべてのユーザーのユーザー名とログイン時間を表示します。
who | cut -c 1-8,18-
区切り文字に基づくカット
フィールドがデフォルトのタブ文字で区切られていない場合は、 -dを使用します 別の区切り文字を指定するオプション。これは、 -dの後に指定された文字を意味します オプションは、行の区切り文字と見なされます。構文は次のとおりです。
cut -d[delimiter] [file]
[delimiter]の代わりに 引数には、必要な区切り文字を指定します。任意の文字を区切り文字として使用できます。 cutを使用する -dを指定せずにファイルからフィールドを抽出するコマンド オプションは、デフォルトの区切り文字がタブ文字であることを意味します 。
次の例では、区切り文字として空白を使用し、2番目のフィールドを出力します。
echo "phoenixNAP is a global IT services provider" | cut -d ' ' -f 2
フィールドによる切り取り
出力の形式が固定されていないコマンド(例: who )にパイプする場合 コマンド)、 -c オプションは役に立ちません。 -fを使用する その場合、フィールドで区切るオプションの方が適しています。
例:
cut -f 2 employees.txt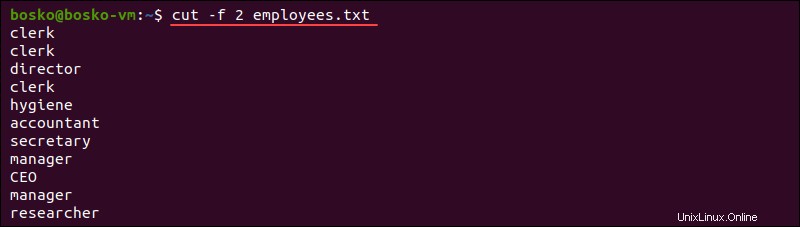
上記の例では、 -fを使用しました employees.txtから2番目のフィールドを抽出するオプション ファイル。
ファイルから特定のフィールドを切り取るには、別の区切り文字を指定します。たとえば、 / etc / passwd ファイル出力には、システム上のすべてのユーザー、ID番号、ホームディレクトリなどが含まれます。
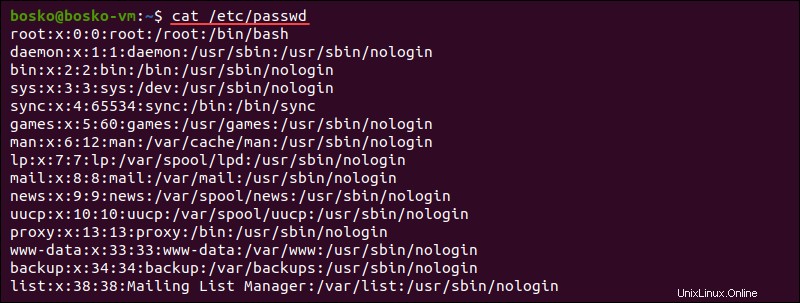
/ etc / passwdのデータ ファイルは、 whoのデータと同じように配置されていません コマンド出力。したがって、文字番号に依存してシステム上のすべてのユーザーを抽出することはできません。
ただし、 / etc / passwdのフィールド ファイルはコロンで区切られます。したがって、同じフィールドを抽出するためにコロンの数を数えます。例:
cut -d: -f1,6 /etc/passwd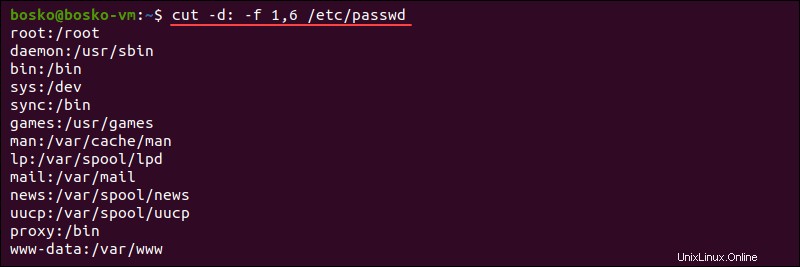
出力には、システム内の各ユーザーと、それぞれフィールド1と6に対応するホームディレクトリが返されます。
選択を補完する
-complement オプションは、指定された位置の文字/バイト/フィールドを除くすべてを出力します。たとえば、次のコマンドは、1番目と3番目を除くすべてのフィールドを出力します。
cut employees.txt -f 1 --complement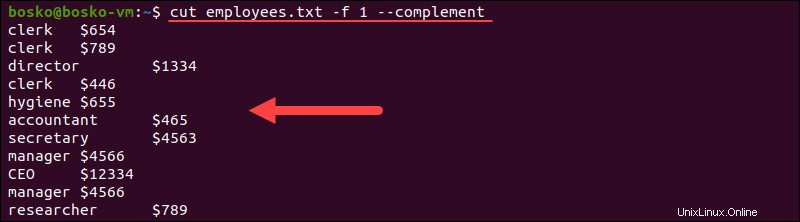
出力区切り文字を指定する
複数の文字/バイト/フィールドを指定する場合、 cut コマンドは、区切り文字なしで出力を連結します。 -output-delimiter を使用して、出力に区切り文字を指定します オプション。
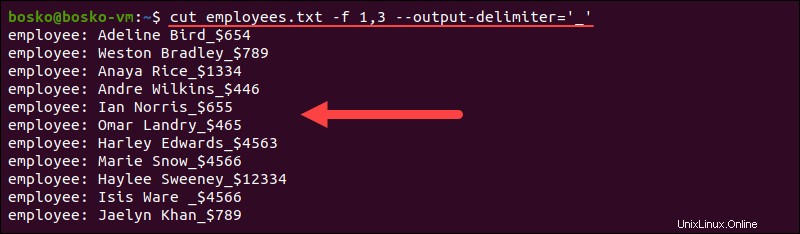
たとえば、出力区切り文字を _に設定します (アンダースコア)、使用:
cut employees.txt -f 1,3 --output-delimiter='_'