はじめに
NoSQLデータベースを使用すると、大量のデータを保存し、どこからでも、どのデバイスからでもデータにアクセスできます。ただし、ニーズに最適なデータモデリング手法を決定することは困難です。幸い、すべてのユースケースに対応するデータモデリング手法があります。
このチュートリアルでは、NoSQLデータベースを構築するときに使用できるさまざまなNoSQLデータモデリング手法をすべて取り上げます。

NoSQLデータモデルとは何ですか?
NoSQLまたは「SQLだけではない」は、従来のSQLの期待とは大きく異なるデータモデルです。
主な違いは、NoSQLはリレーショナルデータモデリング手法を使用せず、柔軟な設計を重視していることです。スキーマの要件がないため、プロセスの設計がはるかに簡単で安価になります。これは、スキーマを完全に使用できないということではなく、スキーマの設計が非常に柔軟であるということです。
NoSQLデータモデルのもう1つの便利な機能は、1秒間に最大数百万のクエリを作成するという点で高効率と高速を実現するように構築されていることです。これは、すべてのデータを1つのテーブルに含めることで実現されるため、JOINSと相互参照のパフォーマンスはそれほど高くありません。
NoSQLは、水平方向にスケーラブルであるという点でもユニークです。 、垂直方向にのみスケーラブルなSQLと比較して。 NoSQLを使用すると、ハードウェアを追加購入するのではなく、安価な別のシャードを使用できます。
4種類のNoSQLデータベース
一般的に、NoSQLデータベースには4つの異なるタイプがあり、それらに基づく数十のデータモデルがあります。
Key-Valueストア
高性能要件のために特別に構築されており、おそらく最も一般的なデータモデルの1つであるキー値ストアは、ポインター付きのキー値を使用してデータを保存します。
このポインタは一意であり、情報に直接リンクします。情報は、任意の情報にすることができます。データベースによっては値の大きさに上限がありますが、必要に応じて空の文字列を値キーとして使用することもできます。
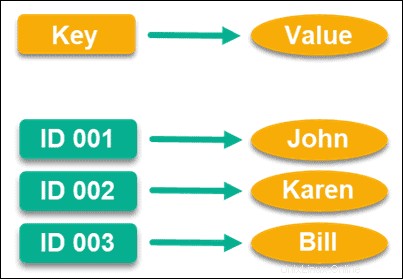
興味深いことに、このデータモデルを軌道に乗せるのを最初に支援したのはAmazonであり、DynamoDBに使用しています。それらが世界最大のオンラインマーケットプレイスの1つであることを考えると、このデータモデルがいかに高性能であるかがわかります。
ドキュメントベースのストア
SQLを使用すると、XMLとJSONが結びつく傾向があり、クエリの速度が低下し、プロセス全体が妨げられます。 NoSQLはリレーショナルモデルを使用しないため、ドキュメントベースのストアが登場する場所であるリレーショナルモデルを使用する必要はありません。
すべてのデータは1つのテーブルに保存されるため、相互参照の必要はなく、情報をテーブルに保存する代わりに、ドキュメントに保存されます。これはKey-Valueストアと非常によく似ており、その傘下で考えることもできますが、違いは、ドキュメントベースのNoSQLには通常XMLなどの何らかの形式のエンコーディングがあることです。
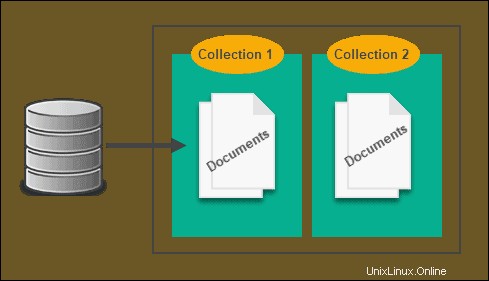
ドキュメントストアを使用するXML固有のNoSQLデータベースがあります。実際、StriderCDはMongoDBをバッキングストアとして使用しています。
列ベースのストア
このタイプのデータモデルは、SQLで一般的な行ではなく、列に情報を格納します。データは、ファミリにグループ化された列に格納され、これらのファミリはさらに多くの列にグループ化されます。これにより、基本的にほぼ無制限の列ネストデータモデルが作成されます。
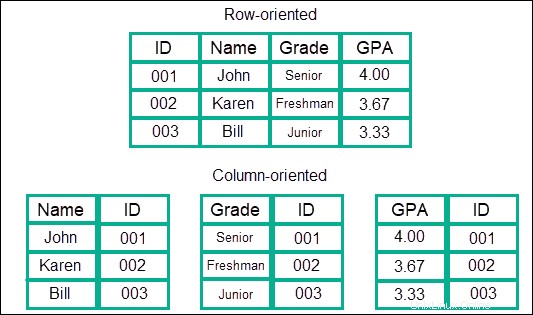
利点は、検索に関して、他のモデルやNoSQLと比較して驚くほど高速な速度を提供することです。データは1つの連続したエントリとして扱われるため、情報が保存されている行や別の領域をジャンプする必要はありません。
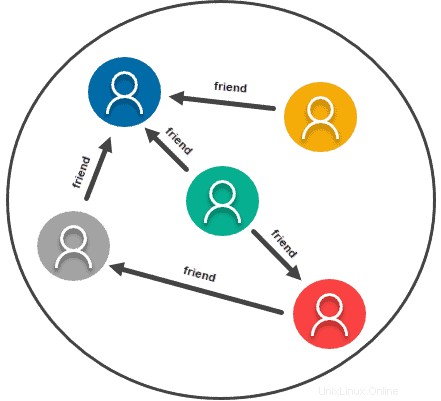
グラフベースのストア
グラフまたはネットワークデータモデルは、基本的に、任意の2つの情報間の関係を、情報自体と同じくらい重要なものとして扱います。そのため、このタイプのデータモデルは、通常グラフで表すあらゆる情報のために実際に作成されています。関係とノードを使用し、データは情報自体であり、関係はノード間で形成されます。
データはNoSQLにどのように保存されますか?
NoSQLデータストレージは、使用するデータベースのタイプによって異なります。 NoSQLはスキーマを必要としないため、データの保存方法に関する青写真はなく、データベースによって異なります。
一般に、NoSQLデータストレージが機能する方法は2つあります。
- Bツリーを使用したディスク上 、その上部は永続的にRAMにあります。
- RB-Treesを使用してすべてがRAM上にあるメモリ内 ディスクに保存されているものはすべて単なる追加です。
NoSQLのスキーマ設計
NoSQLデータベースには実際には設定された構造がないため、開発とスキーマの設計は物理データモデルに重点を置く傾向があります。これは、NoSQLが得意とする、水平方向に拡張性のある大規模な環境向けに開発することを意味します。したがって、スケーラビリティに伴う特定の癖や問題が最前線にあります。
そのため、データアクセスの最適化は必須であり、ビジネスが何を望んでいるかを知ることによってのみ達成できるため、最初のステップはビジネス要件を定義することです。 データと関係があります。スキーマ設計は、ユースケースに関連付けられたワークフローを補完する必要があります。
主キーを選択する方法はいくつかありますが、最終的にはユーザー自身によって異なります。そうは言っても、一部のデータは、特にそのデータが照会される頻度に関して、より効率的なスキーマを示唆している可能性があります。
NoSQLデータモデリング手法
すべてのNoSQLデータモデリング手法は、次の3つの主要なグループにグループ化されています。
- 概念的なテクニック
- 一般的なモデリング手法
- 階層モデリング手法
以下では、すべてのNoSQLデータモデリング手法について簡単に説明します。
概念的なテクニック
NoSQLデータモデリングには、次の3つの概念的な手法があります。
- 非正規化 。非正規化は非常に一般的な手法であり、データを単純化するために複数のテーブルまたはフォームにデータをコピーする必要があります。非正規化を使用すると、クエリが必要なすべてのデータを1か所に簡単にグループ化できます。もちろん、これは、さまざまなパラメータでデータ量が増加することを意味します。これにより、データ量が大幅に増加します。
- 集計 。これにより、ユーザーは複雑な内部構造を持つネストされたエンティティを形成したり、特定の構造を変更したりできます。最終的に、集約は1対1の関係を最小化することにより、結合を減らします。
ほとんどのNoSQLデータモデルには、このソフトスキーマ手法の何らかの形式があります。たとえば、グラフおよびKey-Valueストアデータベースには、任意の形式の値があります。これらのデータモデルは、値に制約を課さないためです。同様に、BigTableなどの別の例では、列と列ファミリーを介した集計が行われます。 - アプリケーション側の結合。 NoSQLデータベースは質問指向であり、設計時に結合が行われるため、NoSQLは通常結合をサポートしていません。これは、クエリ実行時に実行されるリレーショナルデータベースと比較されます。もちろん、これはパフォーマンスの低下につながる傾向があり、避けられない場合もあります。
一般的なモデリング手法
NoSQLデータモデリングには5つの一般的な手法があります。
- 列挙可能なキー 。キーをハッシュするだけでエントリを複数の専用サーバーに分割できるため、ほとんどの場合、順序付けされていないキー値は非常に便利です。それでも、順序付けられたキーを使用して何らかの形式の並べ替え機能を追加すると、少し複雑になり、パフォーマンスが低下する可能性がありますが、便利です。
- 次元削減 。地理情報システムはR-Treeを使用する傾向があります インデックスを作成し、インプレースで更新する必要があります。これは、大量のデータを処理する場合にコストがかかる可能性があります。もう1つの従来のアプローチは、2D構造をフラット化して、Geohashで行われるような単純なリストにすることです。
次元削減を使用すると、多次元データを単純なKey-Valueモデルまたは非多次元モデルにマッピングできます。
次元削減を使用して、多次元データをKey-Valueモデルまたは別の非多次元モデルにマッピングします。 - インデックステーブル。 インデックステーブルを使用すると、必ずしも内部でサポートされていないストアのインデックスを利用できます。特定のアクセスパターンに従うキーを使用して、一意のテーブルを作成して維持することを目指します。たとえば、ユーザーIDでアクセスするためのユーザーアカウントを格納するマスターテーブル。
- 複合キーインデックス 。やや一般的な手法ですが、順序付けされたキーを使用する場合、複合キーは非常に便利です。これを取得してセカンダリキーと組み合わせると、前述の次元削減手法と非常によく似た多次元インデックスを作成できます。
- 逆検索–直接集計。 この手法の背後にある概念は、特定の基準セットを満たすインデックスを使用し、そのデータをフルスキャンまたは何らかの形式の元の表現で集約することです。
これはデータモデリングというよりもデータ処理パターンですが、データモデルはこのタイプの処理パターンを使用することで確かに影響を受けます。この手法に必要なレコードのランダムな取得は非効率的であることを考慮に入れてください。この問題を軽減するには、クエリ処理をバッチで使用します。
階層モデリング手法
NoSQLデータには7つの階層モデリング手法があります:
- ツリーの集約。 ツリー集約は、基本的にデータを単一のドキュメントとしてモデル化することです。これは、TwitterスレッドやReddit投稿など、常に一度にアクセスされるレコードに関しては非常に効率的です。もちろん、問題は、個々のエントリへのランダムアクセスが非効率的であるということです。
- 隣接リスト。 これは、ノードが直接の祖先を持つ配列の独立したレコードとしてモデル化される単純な手法です。これは、親または子でノードを検索できるという複雑な言い方です。ただし、ツリーの集約と同様に、特定のノードのサブツリー全体を取得するには非常に非効率的です。
- マテリアライズドパス。 この手法は一種の非正規化であり、ツリー構造での再帰的な走査を回避するために使用されます。主に、親または子を各ノードに帰属させたいので、トラバーサルを気にせずにノードの先行または子孫を判別するのに役立ちます。ちなみに、マテリアライズされたパスは、セットまたは単一の文字列としてIDとして保存できます。
- ネストされたセット 。リレーショナルデータベースのツリーのような構造の標準的な手法であり、NoSQLやKey-Valueまたはドキュメントデータベースにも同様に適用できます。目標は、ツリーリーフを配列として格納し、開始/終了インデックスを使用して各非リーフノードをリーフの範囲にマップすることです。
この方法でモデル化することは、少量のメモリしか必要とせず、必ずしもトラバーサルを使用する必要がないため、不変のデータを処理するための効率的な方法です。とはいえ、更新にはインデックスの更新が必要なため、費用がかかります。 - ネストされたドキュメントのフラット化:番号付きフィールド名。 ほとんどの検索エンジンは、複雑な内部構造を持つものではなく、フィールドと値のフラットリストであるドキュメントを処理する傾向があります。そのため、このデータモデリング手法では、これらの複雑な構造をプレーンドキュメントにマッピングしようとします。たとえば、階層構造でドキュメントをマッピングします。これは、よくある問題です。
もちろん、このタイプの作業は骨の折れる作業であり、特にネストされた構造が増えるにつれて、簡単に拡張することはできません。 - ネストされたドキュメントのフラット化:近接クエリ。 番号付きフィールド名データモデリング手法の潜在的な問題を解決する1つの方法は、近接クエリと呼ばれる同様の手法を使用することです。 これらは、ドキュメント内の単語間の距離を制限し、パフォーマンスを向上させ、クエリ速度への影響を軽減するのに役立ちます。
- バッチグラフ処理。 バッチグラフ処理は、ノードの上下の関係を数ステップで調査するための優れた手法です。これは費用のかかるプロセスであり、必ずしも適切に拡張できるとは限りません。メッセージパッシングとMapReduceを使用することで、このタイプのグラフ処理を実行できます。