Apache Kafkaとは何ですか?
Kafkaは、大量のデータをリアルタイムで収集して処理するメッセージングシステムであり、Kubernetesクラスターで実行されるアプリケーションの重要な統合コンポーネントになります。クラスタにデプロイされたアプリケーションの効率は、 Apache Kafkaなどのイベントストリーミングプラットフォームでさらに強化できます。 。
この詳細なチュートリアルでは、KubernetesクラスタでKafkaサーバーを設定する方法を紹介します。

Apache Kafkaはどのように機能しますか?
Apache Kafkaは、パブリッシュ/サブスクライブモデルに基づいています:
- プロデューサー メッセージを作成し、トピックに公開します 。
- Kafkaはメッセージをトピックに分類します 不変になるように保存します。
- 消費者は特定のトピックに登録します プロデューサーから提供されたメッセージを吸収します。
このコンテキストでのプロデューサーとコンシューマーは、イベント駆動型メッセージを生成するアプリケーションと、それらのメッセージを消費するアプリケーションを表します。メッセージはKafkaブローカーに保存され、ユーザー定義のトピックで並べ替えられます 。
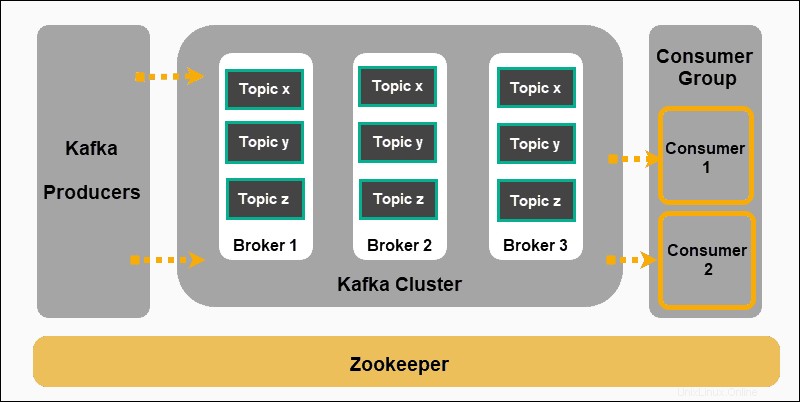
Zookeeperは、Kafka構成の不可欠なコンポーネントです。 Kafkaのプロデューサー、ブローカー、コンシューマー、クラスターメンバーシップを調整します。
Zookeeperをデプロイする
KafkaはZookeeperなしでは機能できません。 Kafkaサービスは、動作しているZookeeperデプロイメントが検出されるまで再起動し続けます。
YAMLファイルzookeeper.yml を作成して、事前にZookeeperをデプロイします 。このファイルは、KubernetesクラスターでZookeeperポッドをスケジュールするサービスとデプロイを開始します。
好みのテキストエディタを使用して、次のフィールドを zookeeper.ymlに追加します :
apiVersion: v1
kind: Service
metadata:
name: zk-s
labels:
app: zk-1
spec:
ports:
- name: client
port: 2181
protocol: TCP
- name: follower
port: 2888
protocol: TCP
- name: leader
port: 3888
protocol: TCP
selector:
app: zk-1
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: zk-deployment-1
spec:
template:
metadata:
labels:
app: zk-1
spec:
containers:
- name: zk1
image: bitnami/zookeeper
ports:
- containerPort: 2181
env:
- name: ZOOKEEPER_ID
value: "1"
- name: ZOOKEEPER_SERVER_1
value: zk1
Kubernetesクラスタで次のコマンドを実行して、定義ファイルを作成します。
kubectl create -f zookeeper.ymlKafkaサービスの作成
次に、Kafkaサービス定義ファイルを作成する必要があります。このファイルは、新しいKafkaポッドの負荷分散によってKafkaBrokerのデプロイメントを管理します。基本的なkafka-service.yml ファイルには次の要素が含まれています:
apiVersion: v1
kind: Service
metadata:
labels:
app: kafkaApp
name: kafka
spec:
ports:
-
port: 9092
targetPort: 9092
protocol: TCP
-
port: 2181
targetPort: 2181
selector:
app: kafkaApp
type: LoadBalancer
ファイルを保存したら、次のコマンドを入力してサービスを作成します。
kubectl create -f kafka-service.ymlKafkaレプリケーションコントローラーの定義
追加の.ymlを作成します Kafkaのレプリケーションコントローラーとして機能するファイル。レプリケーションコントローラーファイル、この例では kafka-repcon.yml、 次のフィールドが含まれています:
---
apiVersion: v1
kind: ReplicationController
metadata:
labels:
app: kafkaApp
name: kafka-repcon
spec:
replicas: 1
selector:
app: kafkaApp
template:
metadata:
labels:
app: kafkaApp
spec:
containers:
-
command:
- zookeeper-server-start.sh
- /config/zookeeper.properties
image: "wurstmeister/kafka"
name: zk1
ports:
-
containerPort: 2181
レプリケーションコントローラー定義ファイルを保存し、次のコマンドを使用して作成します。
kubectl create -f kafka-repcon.ymlKafkaサーバーを起動します
Kafkaサーバーの構成プロパティは、 config / server.propertiesで定義されています。 ファイル。 Zookeeperサーバーはすでに構成されているため、次のコマンドでKafkaサーバーを起動します。
kafka-server-start.sh config/server.propertiesカフカトピックの作成方法
Kafkaには、 kafka-topics.shというコマンドラインユーティリティがあります。 。このユーティリティを使用して、サーバー上にトピックを作成します。新しいターミナルウィンドウを開き、次のように入力します。
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Topic-NameTopic-Nameという名前のトピックを作成しました 単一のパーティションと1つのレプリカインスタンスを使用します。
カフカプロデューサーを始める方法
config / server.properties ファイルにはブローカーポートIDが含まれています。この例のブローカーは、ポート9092でリッスンしています。コマンドラインを使用して、リスニングポートを直接指定できます。
kafka-console-producer.sh --topic kafka-on-kubernetes --broker-list localhost:9092 --topic Topic-Name 次に、ターミナルを使用して数行のメッセージを追加します。
Kafkaコンシューマーを開始する方法
Producerプロパティと同様に、デフォルトのConsumer設定は config / Consumer.propertiesで指定されます。 ファイル。新しいターミナルウィンドウを開き、メッセージを消費するためのコマンドを入力します。
kafka-console-consumer.sh --topic Topic-Name --from-beginning --zookeeper localhost:2181
--from-beginning コマンドはメッセージを時系列で一覧表示します。これで、プロデューサーの端末からメッセージを入力して、それらがコンシューマーの端末に表示されるのを確認できます。
Kafkaクラスターをスケーリングする方法
コマンドターミナルを使用し、 kubectlを使用してKafkaクラスターを直接管理します。 。次のコマンドを入力し、ポッドの数を1から6に増やして、Kafkaクラスターをすばやくスケーリングします。
kubectl scale rc kafka-rc --replicas=6