テキストを選択してコピーできる優れたPDFビューアがUbuntuソースにありますか? Okular for KDEは、Document Viewerよりもはるかに多くのツールを備えているため、優れたアプリです。リポジトリにOkularがあるようですが、それに付属するすべてのKDE依存関係をインストールすることは避けたいと思います。ただし、実際に行う必要があるのは、PDFからテキストを選択してコピーすることだけです。何がこれを可能にしますか?
承認された回答:
コメントで述べたように、PDFドキュメントのテキストが選択可能の場合 テキストとしてかどうかは、テキストが画像としてドキュメント内にあるかどうかによって異なります。 またはテキストとして 。後者の場合、すべてのpdf 視聴者は、私の知る限り、テキストの選択をサポートしています。
PDF画像にテキストを含むオプションはありませんか?
ただし、ドキュメント内のテキストを「読み取り可能」にするためのオプションがいくつかあります
比較的不明なものの1つですが、pdfを(また)変換するための非常に優れたオプションです。 テキストへの画像はgimageReaderです :
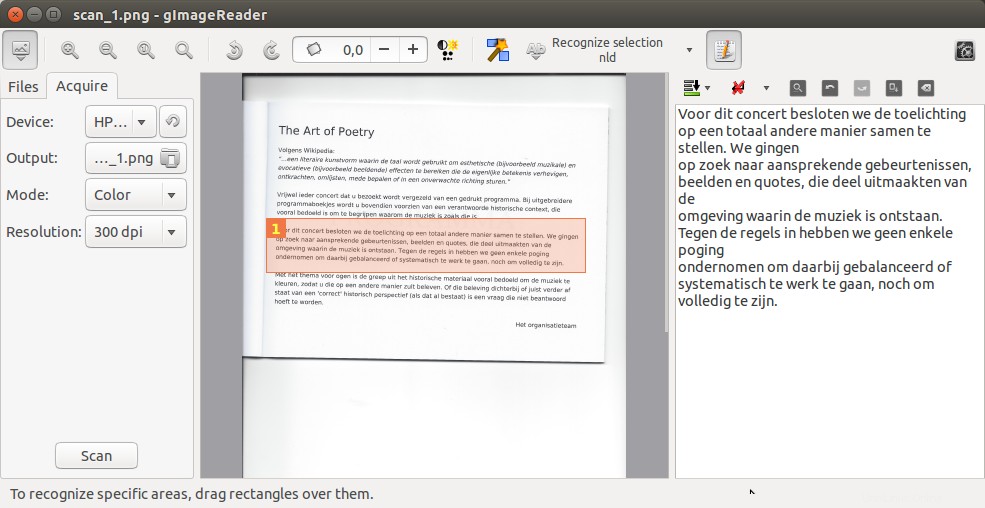
優れたインターフェイスを備えており、PDFドキュメントの横に表示される選択したテキストを読み取ります。
インストールするには、そのppaを使用します:
sudo add-apt-repository ppa:sandromani/gimagereader
sudo apt-get update
sudo apt-get install gimagereader
注
tesseractを追加でインストールする必要がある/必要な場合があります 使用する特定の言語用のocrツール:
sudo apt-get install tesseract-ocr
および特定の言語、例:
sudo apt-get install tesseract-ocr-eng
synapticを使用して、特定の言語を簡単に選択することもできます 。
編集
(少なくとも)18.04以降、gImageReaderはリポジトリにあるため、ppaを手動で追加する必要はありません。