はじめに
Apache Spark より高速な計算結果を提供するためにis_createdされるオープンソース分散計算フレームワークです。
これはメモリ内の計算エンジンであり、データがメモリ内で処理されることを意味します。
スパーク ストリーミング、グラフ処理、SQL、MLLib用のさまざまなAPIをサポートします。また、優先言語としてJava、Python、Scala、およびRをサポートしています。 Sparkは主にHadoopクラスターにインストールされますが、スタンドアロンモードでSparkをインストールして構成することもできます。
この記事では、 Apache Sparkをインストールする方法を説明します。 Debian およびUbuntu ベースのディストリビューション。
UbuntuにJavaをインストールする
Apache Sparkをインストールするには Ubuntuでは、 Javaが必要です マシンにインストールされています。最新のディストリビューションのほとんどには、デフォルトでJavaがインストールされており、次のコマンドを使用して確認できます。
$ java -version
出力がない場合は、UbuntuにJavaをインストールする方法に関する記事を使用してJavaをインストールするか、次のコマンドを実行してUbuntuおよびDebianベースのディストリビューションにJavaをインストールできます。
$ sudo apt update
$ sudo apt install default-jre
$ java -versionUbuntuにScalaをインストールする
次に、 Scalaをインストールできます 次のコマンドを実行してaptリポジトリからscalaを検索し、インストールします。
パッケージを検索する
$ sudo apt search scalaパッケージをインストールする
$ sudo apt install scala -yScalaのインストールを確認するには 、次のコマンドを実行します。
$ scala -version 
UbuntuにApacheSparkをインストールする
次に、公式のApache Sparkダウンロードページにアクセスして、この記事の執筆時点で最新バージョン(3.1.2など)を入手してください。または、wgetコマンドを使用して、ターミナルに直接ファイルをダウンロードすることもできます。
$ wget https://apachemirror.wuchna.com/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
次に、ターミナルを開き、ダウンロードしたファイルが配置されている場所に切り替え、次のコマンドを実行してApacheSparktarファイルを抽出します。
$ tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz 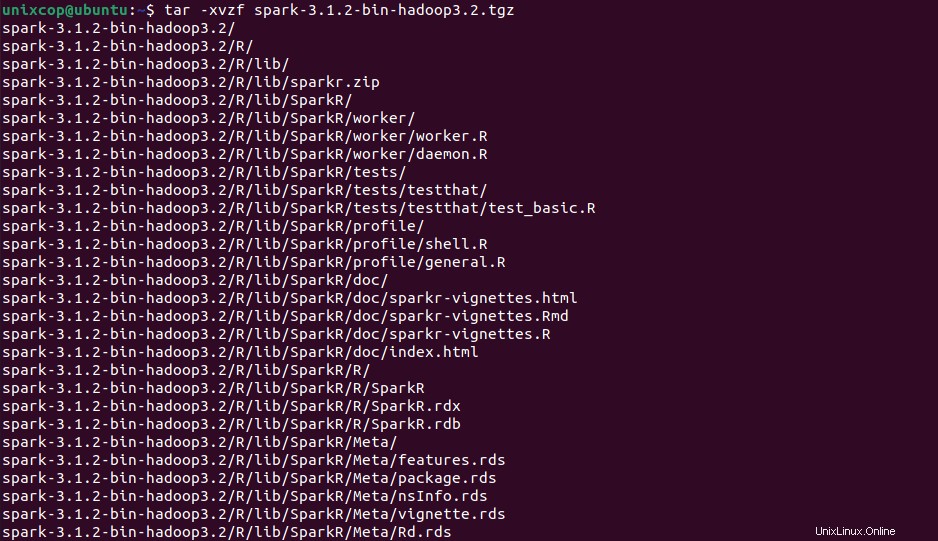
最後に、抽出したスパークを移動します / optへのディレクトリ ディレクトリ。
sudo mv spark-3.1.2-bin-hadoop3.2 /opt/sparkSparkの変数を構成する
次に、 .profileにいくつかの環境変数を設定する必要があります スパークを起動する前にファイルします。
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile
$ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
$ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profileこれらの新しい環境変数がシェル内で到達可能であり、Apache Sparkで利用可能であることを確認するには、次のコマンドを実行して最近の変更を有効にすることも必須です。
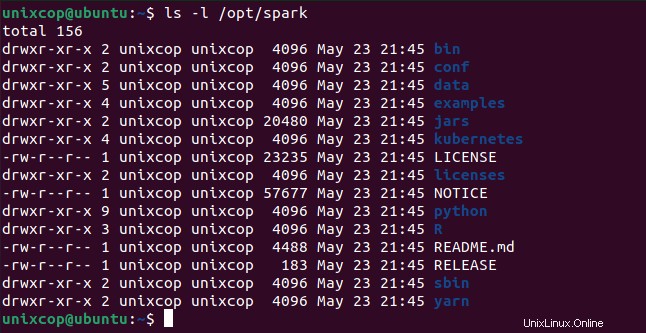
$ source ~/.profileサービスを開始および停止するためのすべてのスパーク関連のバイナリは、 sbinの下にあります。 フォルダ。
$ ls -l /opt/spark
UbuntuでApacheSparkを起動する
次のコマンドを実行して、スパークを開始します マスターサービスとスレーブサービス。
$ start-master.sh
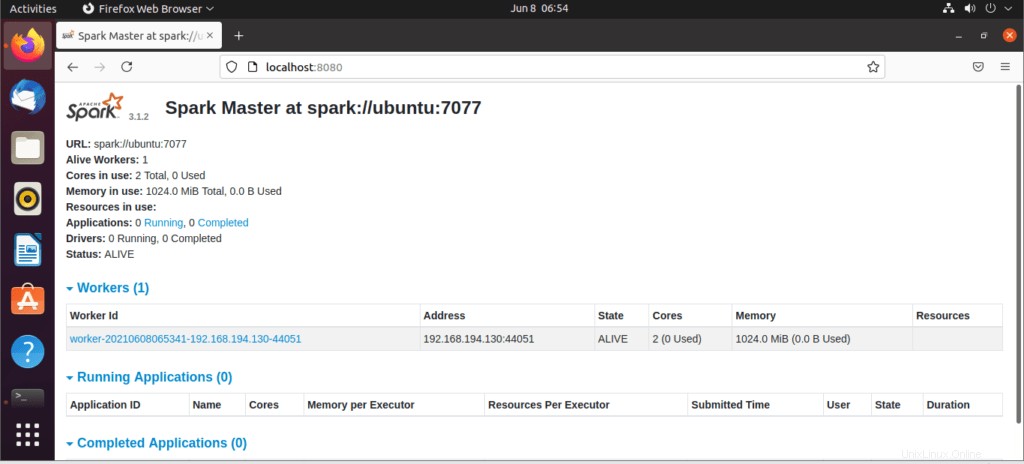
サービスが開始したら、ブラウザに移動して、次のURLアクセススパークページを入力します。このページから、私のマスターサービスが開始されていることがわかります。
http://localhost:8080/次に、次のコマンドでワーカーを追加できます:
$ start-workers.sh spark://localhost:7077
ワーカーは次のように追加されます:
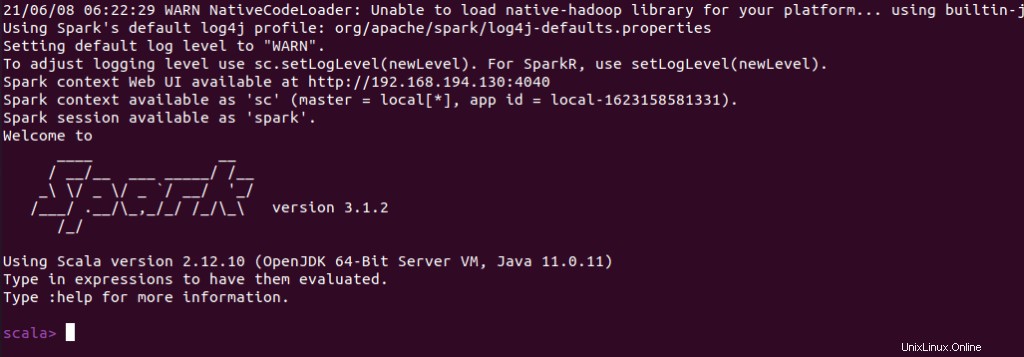
スパークシェルかどうかを確認することもできます スパークシェルを起動すると正常に動作します コマンド。
$ spark-shell