ほとんどのシステム管理者と一部の標準ユーザーでさえ、ファイルの編集、削除、ユーザーの作成と削除、IPアドレスの検索などの日常的なタスクにコマンドラインを好みます。これの理由の1つは、コマンドラインが高速であるためです。使用するリソースが少なくなります。ユーザーが頻繁に行うもう1つのことは、ファイルをダウンロードすることです。また、コマンドラインを使用して簡単かつ迅速に実行できます。 Wgetとcurlは、コマンドラインからファイルをダウンロードできるコマンドラインユーティリティです。
この投稿では、wgetおよびcurlユーティリティを使用してコマンドラインからUbuntuにファイルをダウンロードする方法について説明します。
注 : Ubuntu 20.04で手順を説明します システム。
Wgetを使用してファイルをダウンロード
Wgetは、Webからファイルをダウンロードするために使用されるコマンドラインツールです。 wgetを使用すると、単一のHTMLファイルまたはWebサイト全体をダウンロードできます。 HTTP、HTTPS、およびFTPプロトコルを使用したファイルのダウンロードをサポートします。ほとんどすべてのLinuxOSにインストールされています。ただし、システムで見つからない場合、または誤って削除された場合は、次のようにインストールできます。
$ sudo apt install wget
wgetコマンドの基本的な構文は次のとおりです。
$ wget [option]… [URL]…
コマンドラインからファイルをダウンロード
コマンドラインからファイルをダウンロードするには、 wgetと入力するだけです。 ダウンロードするファイルのURLが続きます。ネットワークトラフィックモニターパッケージ「vnstat-2.6.tar.gz」をWebサイトからダウンロードすると、コマンドは次のようになります。
$ wget https://humdi.net/vnstat/vnstat-2.6.tar.gz
Wgetがファイルのダウンロードを開始し、進行状況が表示されます。ファイルはターミナルの現在のディレクトリに保存されます。
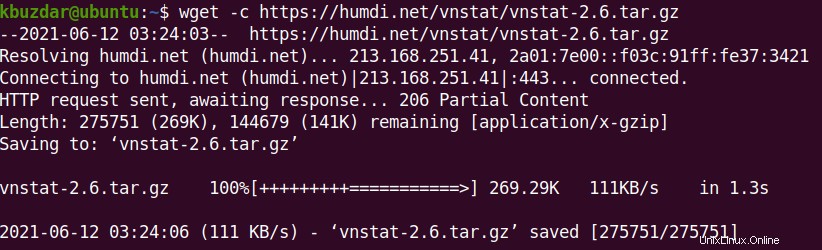
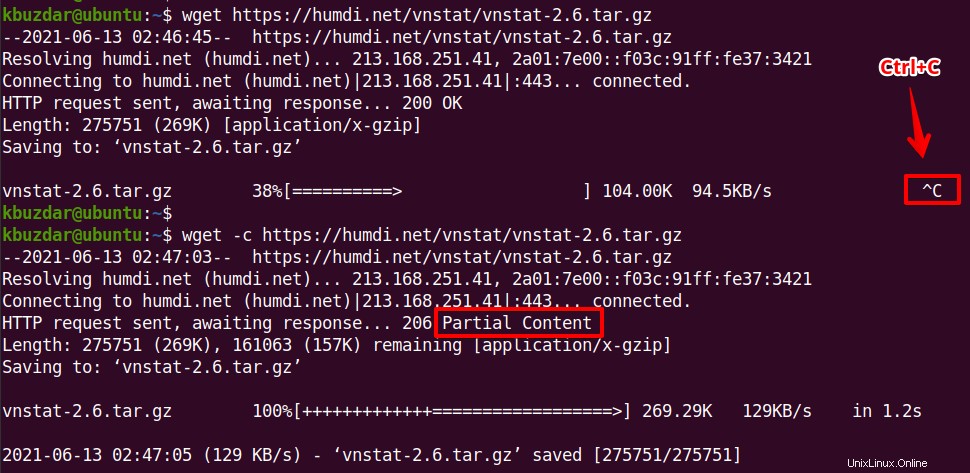
部分的にダウンロードされたファイルを再開します
何らかの理由でダウンロードが停止した場合、またはCtrl + Cを押して手動でダウンロードを停止した場合は、wgetコマンド -cを使用してダウンロードを再開できます。 オプション。このオプションを使用すると、部分的にダウンロードしたファイルを中断したところから続行できます。
$ wget -c <URL>
詳細出力をオフにする
デフォルトでは、wgetはダウンロードプロセスのすべての詳細を示す詳細な出力を表示します。必要に応じて、wget -nvを使用してこの出力を制限できます。 オプション。
$wget -nv <URL>
このオプションは、ダウンロードプロセスの基本情報のみを表示します。

詳細出力を完全にオフにするには、 -qを使用します オプション:
$ wget -q <URL>

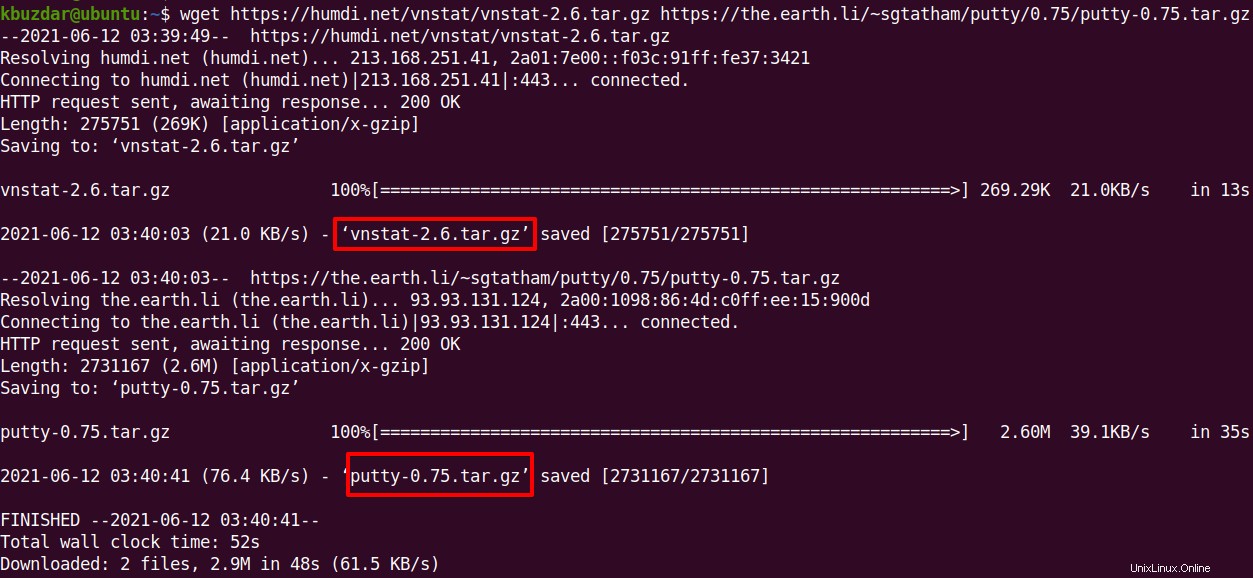
複数のファイルをダウンロード
複数のファイルをダウンロードするには、 wgetと入力します その後にすべてのファイルのURLが続きます。
$ wget <URL1> <URL2>
wgetコマンドは両方のファイルをダウンロードし、現在のターミナルディレクトリに保存します。
複数のファイルをダウンロードする別の方法は、wget -iを使用することです。 オプション。大量のファイルをダウンロードする必要があるとしましょう。必要なのは、テキストファイルを作成し、このファイル内のすべてのURLを一覧表示することです(1行に1つのURL)。次に、 wgetと入力します 続いて-i オプションとURLのリストを含むファイル名:
$ wget -i <filename>

注 :上記の出力では、 -nvを使用しています 詳細出力をオフにするオプション。
Curlを使用してファイルをダウンロード
Curlは、サーバーとの間でファイルをダウンロードおよびアップロードするために使用されるコマンドラインツールです。 FTP、HTTP、HTTPS、TFTP、IMAP、LDAPなどを含む20を超えるプロトコルをサポートします
Curlは、ほぼすべてのLinuxOSにインストールされています。ただし、システムで見つからない場合、または誤って削除された場合は、次のようにインストールできます。
$ sudo apt install curl
curlコマンドの基本的な構文は次のとおりです。
$ curl [option]… [URL]…
基本的なcurlコマンドの使用法
curlコマンドの基本的な使用法は、単一のファイルまたはWebページのコンテンツをダウンロードすることです。たとえば、ウェブページ「index.html」をダウンロードするには、 curlと入力します。 WebページのURLが続きます:
$ curl <URL>
このコマンドは、指定されたファイルを現在のディレクトリにダウンロードします。

上記のcurlコマンドを実行すると、次のようなHTMLコンテンツが画面に表示されます。 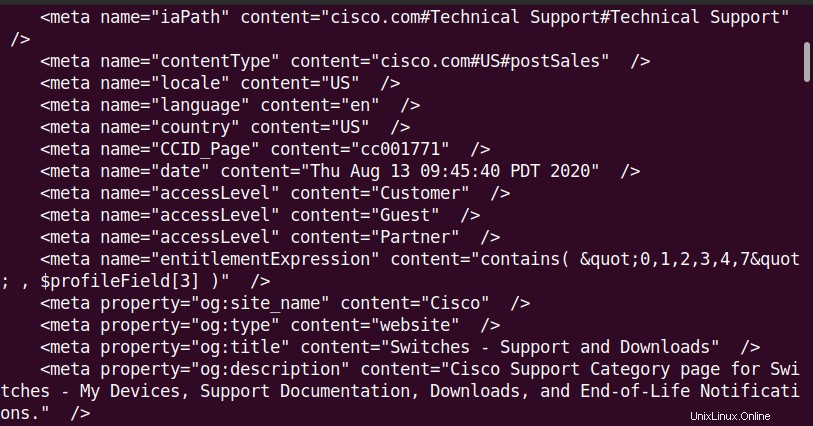
ページのコンテンツをファイルに保存する
ページのコンテンツを画面に表示する代わりに、ダウンロードしてファイルに保存することができます。ファイルをシステムに保存するには、curlコマンド -Oを使用します または-o オプション。 -O オプションは、ファイルをリモートロケーションのファイルと同じ名前で保存します。 -o オプションを使用すると、ファイルを別の名前で保存できます。
-Oオプションの使用
-Oを使用 オプションの場合、ファイル名を指定する必要はありません。リモートの場所にあるファイルの名前でファイルがシステムに保存されます。
$ curl -O <URL>
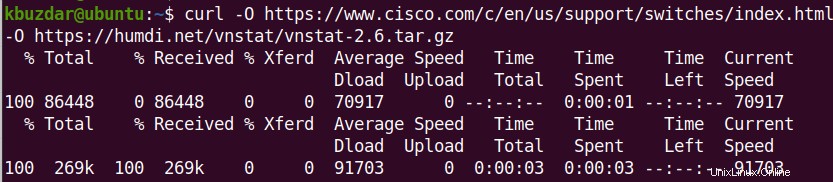
たとえば、次のコマンドは「index.html」という名前でファイルを保存します。
$ curl -O https://www.cisco.com/c/en/us/support/switches/index.html

-oオプションの使用
-oを使用 オプションで、任意のファイル名を指定できます。
$ curl -o filename <URL>
たとえば、次のコマンドは「switches.html」という名前でファイルを保存します。
$ curl -o switches.html https://www.cisco.com/c/en/us/support/switches/index.html
静かにcurlを実行する
カールのダウンロードプロセス中にプログレスバーやエラーメッセージを表示したくない場合は、 -sを使用してサイレントにすることができます。 次のオプション:
$ curl -s <URL>

複数のファイルをダウンロード
複数のファイルをダウンロードするには、 curlと入力します その後にすべてのファイルのURLが続きます:
$ curl -O [URL1] -O [URL2] -O [URL3]….
このコマンドは、すべてのファイルを現在のターミナルディレクトリに保存します。
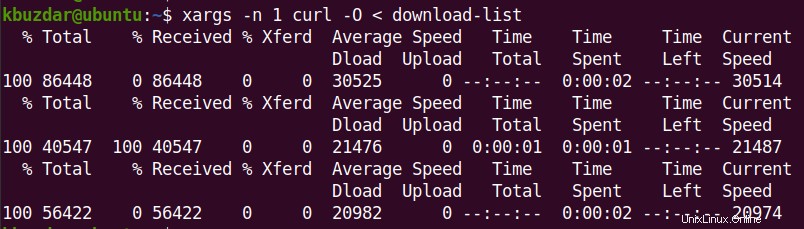
ダウンロードする必要のあるURLが多すぎる場合は、テキストファイルを作成し、その中にURLをリストします。

次に、ファイルにリストされているすべてのURLをダウンロードするには、次のコマンドを使用します。
$ xargs -n 1 curl -O < filename
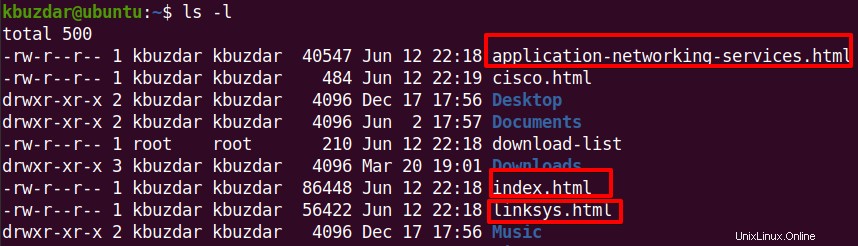
その後、 lsを使用できます すべてのファイルがダウンロードされたかどうかを確認するコマンド。
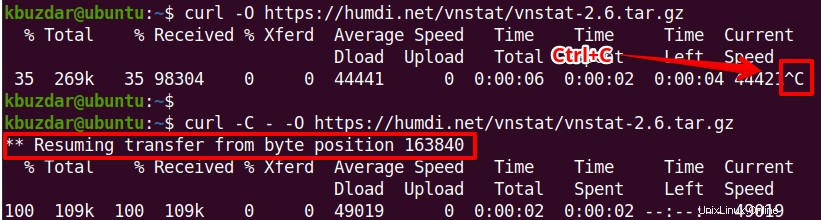
部分的にダウンロードされたファイルを再開します
何らかの理由でダウンロードが停止した場合、またはCtrl + Cを押して手動でダウンロードを停止した場合は、curlコマンド「 -C –」を使用してダウンロードを再開できます。 " オプション。このオプションを使用すると、部分的にダウンロードしたファイルを中断したところから続行できます。
$ curl -C - <URL>
wgetとcurlはどちらも、ファイルの非対話型ダウンロードに使用される無料のオープンソースコマンドラインユーティリティです。どちらのユーティリティもWebからファイルをダウンロードできますが、覚えておいてください。それらは機能の点で大きく異なります。これらのユーティリティの機能の詳細な概要については、wgetおよびcurlのマニュアルページにアクセスしてください。