はじめに
MySQLは、意味があり、簡単にアクセスできる方法でデータを格納および構造化する、人気のあるオープンソースデータベースアプリケーションです。大規模なアプリケーションでは、膨大な量のデータがパフォーマンスの問題につながる可能性があります。
このガイドは、MySQLデータベースのパフォーマンスを向上させる方法に関するいくつかのチューニングのヒントを提供します 。

前提条件
- MySQLがインストールされ実行されているLinuxシステム、CentosまたはUbuntu
- 既存のデータベース
- オペレーティングシステムとデータベースの管理者の資格情報
システムMySQLパフォーマンスチューニング
システムレベルでは、ハードウェアとソフトウェアのオプションを調整して、MySQLのパフォーマンスを向上させます。
1。 4つの主要なハードウェアリソースのバランスをとる

ストレージ
ストレージを評価してください。従来のハードディスクドライブ(HDD)を使用している場合は、パフォーマンスを向上させるためにソリッドステートドライブ(SSD)にアップグレードできます。
iotopなどのツールを使用する またはsar sysstatから ディスクの入出力レートを監視するパッケージ。ディスク使用量が他のリソースの使用量よりもはるかに多い場合は、ストレージを追加するか、より高速なストレージにアップグレードすることを検討してください。
プロセッサー
プロセッサは通常、システムの速度の尺度と見なされます。 Linuxのトップを使用する リソースの使用方法の内訳を示すコマンド。 MySQLプロセスとそれらが必要とするプロセッサ使用率に注意してください。
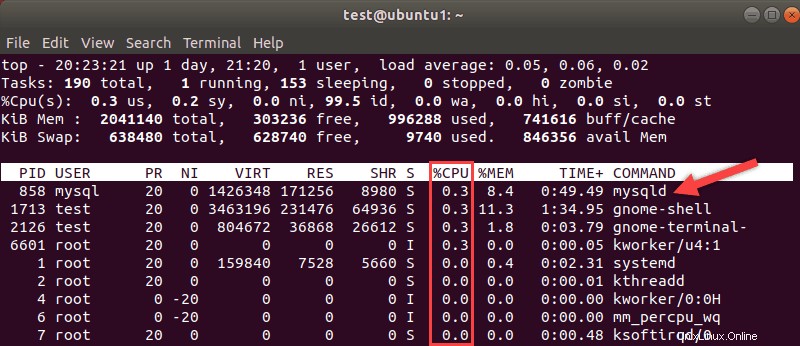
プロセッサのアップグレードには費用がかかりますが、CPUがボトルネックの場合は、アップグレードが必要になる可能性があります。
メモリ
メモリは、MySQLデータベースストレージサーバーのRAMの合計量を表します。メモリキャッシュを調整できます(詳細は後で説明します)パフォーマンスを向上させる 。十分なメモリがない場合、または既存のメモリが最適化されていない場合、パフォーマンスを向上させるのではなく、パフォーマンスを損なう可能性があります。
他のボトルネックと同様に、サーバーのメモリが常に不足している場合は、さらに追加することでアップグレードできます。メモリが不足すると、サーバーはデータストレージ(ハードドライブなど)をキャッシュしてメモリとして機能します。データベースキャッシングはパフォーマンスを低下させます。
ネットワーク
ネットワークトラフィックを監視して、負荷を管理するのに十分なインフラストラクチャがあることを確認することが重要です。
ネットワークに過負荷がかかると、遅延、パケットのドロップ、さらにはサーバーの停止につながる可能性があります。通常のレベルのデータベーストラフィックに対応するのに十分なネットワーク帯域幅があることを確認してください。
2。 MyISAMではなくInnoDBを使用する
MyISAM 一部のMySQLデータベースで使用されている古いデータベーススタイルです。これは、効率の低いデータベース設計です。新しいInnoDB より高度な機能をサポートし、最適化メカニズムが組み込まれています。
InnoDBはクラスター化インデックスを使用し、データをページに保持します。ページは連続する物理ブロックに格納されます。値がページに対して大きすぎる場合、InnoDBはその値を別の場所に移動してから、値にインデックスを付けます。この機能は、関連するデータをストレージデバイスの同じ場所に保持するのに役立ちます。つまり、物理ハードドライブがデータにアクセスするのにかかる時間が短縮されます。
3。 MySQLの最新バージョンを使用する
最新バージョンの使用は、古いデータベースやレガシーデータベースで常に実行可能であるとは限りません。ただし、可能な限り、使用中のMySQLのバージョンを確認し、最新のものにアップグレードする必要があります。
進行中の開発の一部には、パフォーマンスの強化が含まれます。一部の一般的なパフォーマンス調整は、MySQLの新しいバージョンによって廃止される可能性があります。一般に、スクリプトファイルや構成ファイルよりもネイティブのMySQLパフォーマンス拡張機能を使用することをお勧めします。
ソフトウェアMySQLパフォーマンスチューニング
SQLパフォーマンスの調整は、リレーショナルデータベースでクエリ速度を最大化するプロセスです。このタスクには通常、複数のツールとテクニックが含まれます。
これらの方法には以下が含まれます:
- MySQL構成ファイルの調整。
- より効率的なデータベースクエリの作成。
- より効率的にデータを取得するためのデータベースの構造化。
4。自動パフォーマンス改善ツールの使用を検討してください
ほとんどのソフトウェアと同様に、すべてのツールがすべてのバージョンのMySQLで機能するわけではありません。 MySQLデータベースを評価するための3つのユーティリティを調べ、パフォーマンスを向上させるための変更を推奨します。
1つ目はチューニングプライマーです。このツールは少し古く、MySQL 5.5 –5.7用に設計されています。データベースを分析し、パフォーマンスを向上させるための設定を提案できます。たとえば、 query_cache_sizeを上げることを提案する場合があります システムがキャッシュをクリアに保つのに十分な速さでクエリを処理できないと思われる場合は、パラメータ。
最新のSQLデータベースのほとんどに役立つ2番目のチューニングツールは、MySQLTunerです。このスクリプト( mysqltuner.pl )はPerlで書かれています。チューニングプライマーと同様に、データベース構成を分析してボトルネックと非効率性を探します。出力には、指標と推奨事項が表示されます:
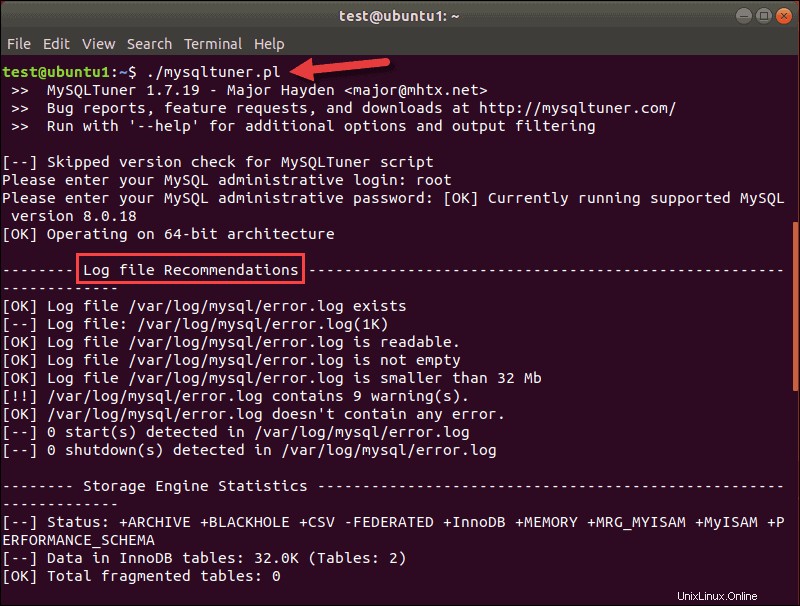
出力の上部に、MySQLTunerツールのバージョンとデータベースが表示されます。
スクリプトはMySQL8.xで動作します。ログファイルの推奨事項がリストの最初にありますが、一番下までスクロールすると、MySQLのパフォーマンスを向上させるための一般的な推奨事項が表示されます。
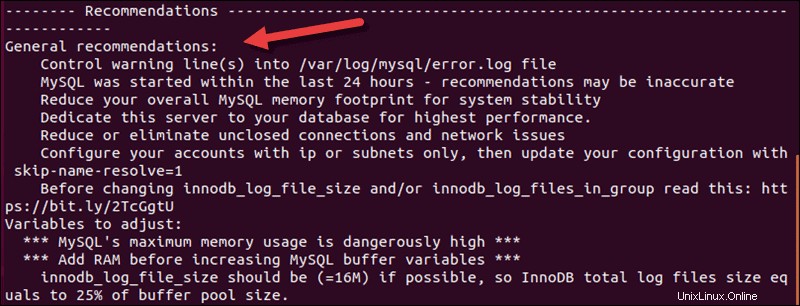
すでにお持ちの3つ目のユーティリティは、 phpMyAdmin Advisorです。 。他の2つのユーティリティと同様に、データベースを評価し、調整を推奨します。すでにphpMyAdminを使用している場合、AdvisorはGUI内で使用できる便利なツールです。
5。クエリの最適化
クエリは、特定の値に一致するデータをデータベースで検索するためのコード化されたリクエストです。クエリ演算子の中には、その性質上、実行に長い時間がかかるものがあります。 SQLパフォーマンスチューニング手法は、クエリを最適化して実行時間を改善するのに役立ちます。
実行時間が短いクエリの検出は、パフォーマンス調整の主要なタスクの1つです。大規模なデータセットに一般的に実装されるクエリは低速で、データベースを占有します。したがって、テーブルは他のタスクには使用できません。
たとえば、OLTPデータベースには、高速なトランザクションと効果的なクエリ処理が必要です。非効率的なクエリを実行すると、データベースの使用がブロックされ、情報の更新が停止します。
環境がトリガーなどの自動クエリに依存している場合、それらはパフォーマンスに影響を与える可能性があります。時間内に蓄積する可能性のあるMySQLプロセスを確認して終了します。
6。適切な場所でインデックスを使用する
多くのデータベースクエリは、次のような構造を使用しています。
SELECT … WHEREこれらのクエリには、結果の評価、フィルタリング、および取得が含まれます。関連するテーブルのインデックスの小さなセットを追加することで、これらを再構築できます。クエリをインデックスに送信して、クエリを高速化できます。
7。述語の関数
クエリの述語で関数を使用することは避けてください。例:
SELECT * FROM MYTABLE WHERE UPPER(COL1)='123'Copy
UPPER 表記は関数を作成します。この関数はSELECTの間に動作する必要があります 手術。これにより、クエリが実行している作業が2倍になるため、可能であれば回避する必要があります。
8。述語で%ワイルドカードを使用しない
テキストデータを検索する場合、ワイルドカードはより広い検索を行うのに役立ちます。たとえば、 chで始まるすべての名前を選択するには 、名前列にインデックスを作成して実行します:
SELECT * FROM person WHERE name LIKE "ch%"クエリはインデックスをスキャンするため、クエリのコストが低くなります。

ただし、最初にワイルドカードを使用して名前を検索すると、インデックススキャンが文字列の末尾に適用されないため、クエリコストが大幅に増加します。
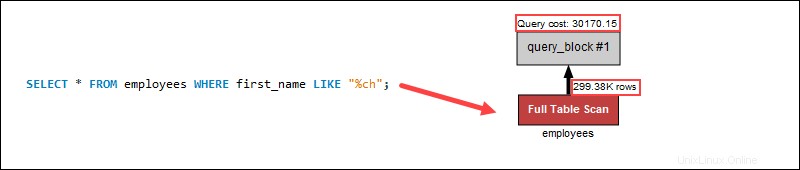
検索の開始時にワイルドカードを使用しても、インデックスは適用されません。代わりに、全表スキャンが各行を個別に検索するため、プロセスのクエリコストが増加します。クエリの例では、最後にワイルドカードを使用すると、テーブルの行が少なくなるため、クエリのコストを削減できます。
文字列の終わりを検索する方法は、文字列を反転し、反転した文字列にインデックスを付けて、開始文字を確認することです。ワイルドカードを最後に配置すると、逆の文字列の先頭が検索されるようになり、検索がより効率的になります。
9。 SELECT関数で列を指定する
分析クエリと探索クエリで一般的に使用される式は、 SELECT *です。 。必要以上に選択すると、不要なパフォーマンスの低下と冗長性が発生します。必要な列を指定すると、クエリで無関係な列をスキャンする必要がなくなります。
すべての列が必要な場合、それを実行する他の方法はありません。ただし、ほとんどのビジネス要件では、データセット内で使用可能なすべての列が必要なわけではありません。代わりに特定の列を選択することを検討してください。
要約すると、以下の使用は避けてください。
SELECT * FROM table代わりに、次のことを試してください:
SELECT column1, column2 FROM table10。 ORDERBYを適切に使用する
ORDER BY 式は、指定された列で結果を並べ替えます。一度に2列でソートするために使用できます。これらは、昇順または降順で同じ順序で並べ替える必要があります。
異なる列を異なる順序で並べ替えようとすると、パフォーマンスが低下します。これをインデックスと組み合わせて、並べ替えを高速化できます。
11。 SELECTDISTINCTの代わりにGROUPBY
SELECT DISTINCT 重複する値を削除しようとするときに、クエリが役立ちます。ただし、このステートメントには大量の処理能力が必要です。
可能な限り、 SELECT DISTINCTの使用は避けてください 、それは非常に非効率的で、時には混乱するためです。たとえば、テーブルに次の構造の顧客に関する情報がリストされている場合:
| id | 名前 | lastName | アドレス | 都市 | 状態 | zip |
|---|---|---|---|---|---|---|
| 0 | ジョン | スミス | 652フラワーストリート | ロサンゼルス | CA | 90017 |
| 1 | ジョン | スミス | 1215 Ocean Boulevard | ロサンゼルス | CA | 90802 |
| 2 | マーサ | マシューズ | 3104 Pico Boulevard | ロサンゼルス | CA | 90019 |
| 3 | マーサ | ジョーンズ | 2712ベニスブルバード | ロサンゼルス | CA | 90019 |
次のクエリを実行すると、4つの結果が返されます。
SELECT DISTINCT name, address FROM person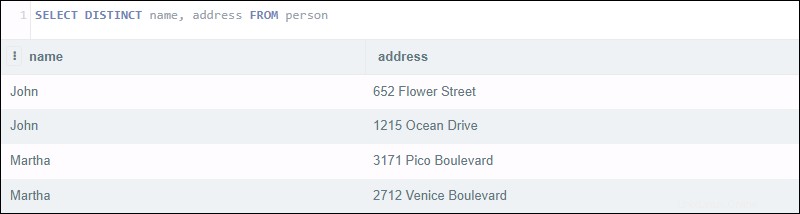
このステートメントは、個別の名前のリストとそのアドレスを返す必要があるようです。代わりに、クエリは両方を調べます 名前とアドレスの列。同じ名前の顧客が2組いますが、住所が異なります。
重複する名前を除外してアドレスを返すには、 GROUP BYを使用してみてください ステートメント:
SELECT name, address FROM person GROUP BY name
結果は、アドレスとともに最初の個別の名前を返し、ステートメントのあいまいさを軽減します。一意のアドレスでグループ化するには、 GROUP BY パラメータはアドレスに変更され、 DISTINCTと同じ結果を返します。 ステートメントを高速化します。
要約すると、以下の使用は避けてください。
SELECT DISTINCT column1, column2 FROM table代わりに、以下を使用してみてください:
SELECT column1, column2 FROM table GROUP BY column112。 JOIN、WHERE、UNION、DISTINCT
可能な限り、内部結合を使用するようにしてください。外部結合は、指定された列の外側にある追加のデータを調べます。そのデータが必要な場合は問題ありませんが、不要なデータを含めるのはパフォーマンスの無駄です。
INNER JOINを使用する テーブルを結合するための標準的なアプローチです。ほとんどのデータベースエンジンは、 WHEREの使用を受け入れます 同じように。たとえば、次の2つのクエリは同じ結果を出力します。
SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.id比較対象:
SELECT * FROM table1, table2 WHERE table1.id = table2.id理論的には、実行時間も同じです。
JOINを使用するかどうかの選択 またはWHERE クエリはデータベースエンジンに依存します。ほとんどのエンジンは2つの方法で同じランタイムを使用しますが、一部のデータベースシステムでは、一方が他方よりも高速に実行されます。
UNION およびDISTINCT コマンドがクエリに含まれることがあります。外部結合と同様に、必要に応じてこれらの式を使用しても問題ありません。ただし、データベースの並べ替えと読み取りが追加されます。それらが必要ない場合は、より効率的な表現を見つけることをお勧めします。
13。 EXPLAIN関数を使用する
最新のMySQLデータベースには、 EXPLAINが含まれています 機能。
EXPLAINを追加する クエリの先頭への式は、クエリを読み取って評価します。非効率的な式や紛らわしい構造がある場合は、 EXPLAIN あなたがそれらを見つけるのを助けることができます。次に、クエリの言い回しを調整して、意図しないテーブルスキャンやその他のパフォーマンスへの影響を回避できます。
14。 MySQLサーバーの構成
この構成には、 /etc/mysql/my.cnfに変更を加えることが含まれます。 ファイル。注意して続行し、一度に小さな変更を加えます。
query_cache_size –実行を待機しているMySQLクエリのキャッシュのサイズを指定します。 10MB前後の小さな値から始めて、100〜200MB以下に増やすことをお勧めします。キャッシュされたクエリが多すぎると、「キャッシュロックを待機しています」という一連のクエリが発生する可能性があります。クエリが引き続きバックアップされる場合は、 EXPLAINを使用することをお勧めします。 各クエリを評価し、それらをより効率的にする方法を見つけるため。
max_connection –データベースへの接続が許可されている数を指します。 「接続が多すぎます」などのエラーが発生した場合 」この値を増やすと役立つ場合があります。
innodb_buffer_pool_size –この設定は、データベースのデータキャッシュとしてシステムメモリを割り当てます。データのチャンクが大きい場合は、この値を増やしてください。他のシステムリソースを実行するために必要なRAMに注意してください。
innodb_io_capacity –この変数は、ストレージデバイスからの入出力のレートを設定します。これは、ストレージドライブのタイプと速度に直接関係しています。 5400 rpm HDDの容量は、ハイエンドSSDやIntelOptaneよりもはるかに低くなります。この値は、ハードウェアに合わせて調整できます。