Elasticsearch は拡張性の高いオープンソースの全文検索および分析エンジンです。 。一般に、複雑な検索機能と要件を備えたアプリケーションを強化するのは、基盤となるエンジン/テクノロジーです。このソフトウェアは、大量のデータを迅速かつほぼリアルタイムで保存、検索、分析できるRESTful操作をサポートしています。 Elasticsearchは、Luceneライブラリに基づく強力な検索エンジンであるため、システム管理者や開発者の間で人気があり、人気があります。
次のチュートリアルでは、 openSUSELeap15にElasticSearchをインストールする方法を学習します。 。
前提条件
- 推奨OS: openSUSE Leap – 15.x
- ユーザーアカウント: sudoまたはrootアクセス権を持つユーザーアカウント。
オペレーティングシステムの更新
openSUSEを更新します 既存のすべてのパッケージが最新であることを確認するためのオペレーティングシステム:
sudo zypper refreshチュートリアルでは、sudoコマンドを使用します およびsudoステータスがあると仮定 。
アカウントのsudoステータスを確認するには:
sudo whoamisudoステータスを示す出力例:
[joshua@opensuse ~]$ sudo whoami
root既存または新規のsudoアカウントを設定するには、openSUSEでのSudoersへのユーザーの追加に関するチュートリアルにアクセスしてください。 。
rootアカウントを使用するには 、rootパスワードを指定して次のコマンドを使用してログインします。
suCURLパッケージのインストール
CURL このガイドの一部にはコマンドが必要です。このパッケージをインストールするには、次のコマンドを入力します。
sudo zyper install curlJavaパッケージのインストール
正常にインストールし、さらに重要なことに、 Elasticsearchを使用するには 、 Javaをインストールする必要があります 。プロセスは比較的簡単です。
次のコマンドを入力して、 OpenJDKをインストールします パッケージ:
sudo zypper install java-11-openjdk-develElasticsearchをインストールする
Elasticsearchは利用できません 標準のopenSUSEリポジトリ 、したがって、Elasticsearchリポジトリからインストールする必要があります 。
リポジトリを追加する前に、GPGキーをインポートしてください 次のコマンドを使用します:
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch次のステップは、次のようにElasticsearchリポジトリファイルを作成することです。
sudo zypper ar https://artifacts.elastic.co/packages/7.x/yum elasticsearch次に、次のコマンドを使用してElasticsearchをインストールします。
sudo zypper install elasticsearch出力例:
「Y」と入力します 次に、「ENTERキー」を押します。 インストールを続行するには
Elasticsearchをデフォルトで有効にするには、insservパッケージをインストールする必要があります 。
sudo zypper install insservデフォルトでは、Elasticsearchサービスは起動時に無効になり、アクティブではありません。サービスを開始してシステム起動時に有効にするには、次のように入力します(systemctl) コマンド:
sudo systemctl enable elasticsearch.service --now出力例:
Synchronizing state of elasticsearch.service with SysV service script with /usr/lib/systemd/systemd-sysv-install.
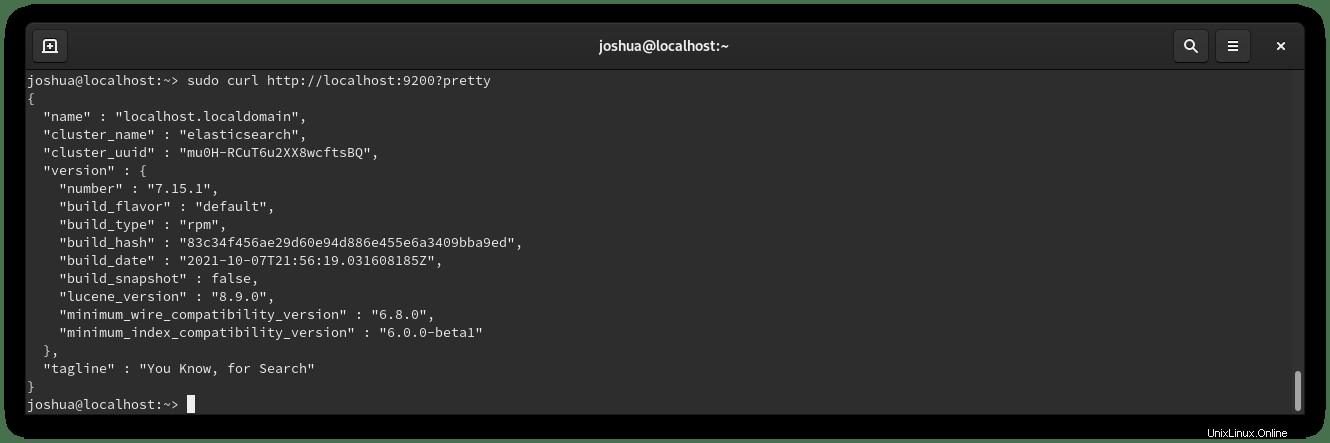
Executing: /usr/lib/systemd/systemd-sysv-install enable elasticsearchcurlコマンドを使用して、Elasticsearchが正しく実行されていることを確認します HTTPリクエストを送信するには ポート9200 ローカルホスト 次のように:
sudo curl http://localhost:9200?pretty出力例:
Elasticsearchを設定する方法
Elasticsearchデータはデフォルトのディレクトリの場所(/ var / lib / elasticsearch)に保存されます 。構成ファイルを表示または編集するには、ディレクトリの場所(/ etc / elasticsearch)にあります。 、およびjava起動オプションは(/ etc / default / elasticsearch)で構成できます 構成ファイル。
Elasticsearchはlocalhostで実行されるため、デフォルト設定は主に単一のオペレーティングサーバーに適しています。 それだけ。ただし、クラスターをセットアップする場合は、リモート接続を許可するように構成ファイルを変更する必要があります。
リモートアクセスの設定(オプション)
デフォルトでは、Elasticsearchはlocalhostのみをリッスンします。これを変更するには、次のように構成ファイルを開きます。
sudo nano /etc/elasticsearch/elasticsearch.yml56行目まで下にスクロールします ネットワークセクションを見つけて、コメント解除(#) 次の行を次のように内部プライベートIPアドレスまたは外部IPアドレスに置き換えます。
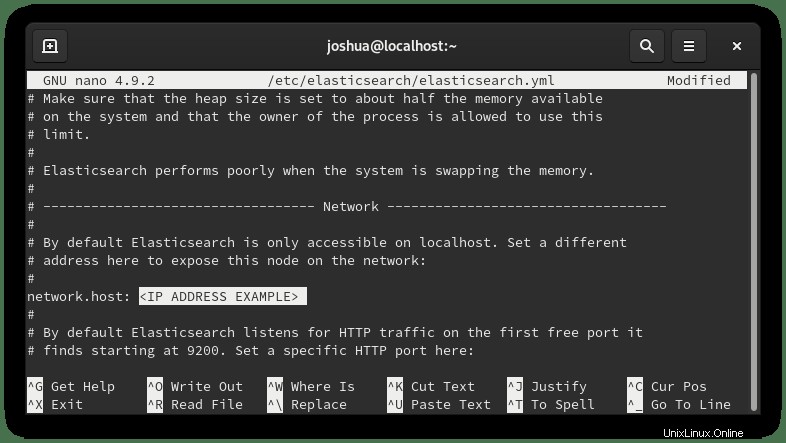
この例では、コメントを外しました(#) (network.host) 上記のように内部プライベートIPアドレスに変更しました。
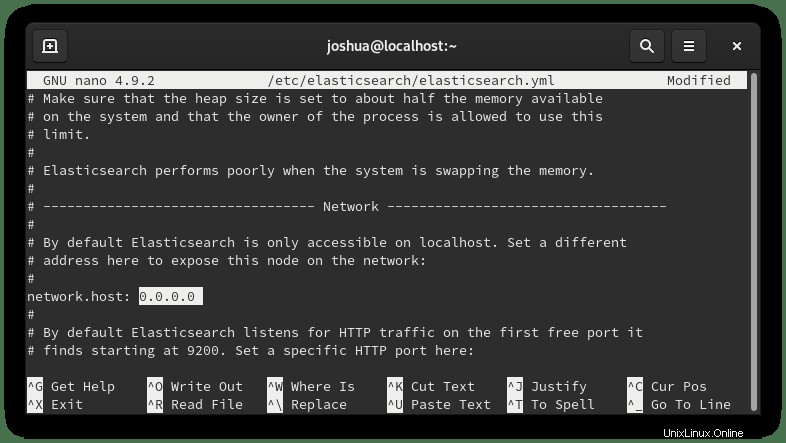
セキュリティ上の理由から、アドレスを指定するのに理想的です。ただし、サーバーにアクセスする複数の内部または外部IPアドレスがある場合は、ネットワークインターフェイスを変更して、(0.0.0.0)を入力してすべてをリッスンします。 次のように:
構成ファイルを保存します(CTRL + O)、 次に、(CLTR + X)を終了します 。
変更を有効にするには、次のコマンドを使用してElasticsearchサービスを再起動する必要があります。
sudo systemctl restart elasticsearchElasticsearch用にFirewallを設定する
デフォルトでは、Elasticsearchにルールが設定されていないため、問題が発生する可能性があります。
まず、Elasticsearchのfirewalldポリシー専用の新しいゾーンを追加します:
sudo firewall-cmd --permanent --new-zone=elasticsearch次に、Memcachedへのアクセスを許可する許可されたIPアドレスを指定します。
sudo firewall-cmd --permanent --zone=elasticsearch --add-source=1.2.3.41.2.3.4をIPに置き換えます 許可リストに追加されるアドレス。
IPアドレスの追加が完了したら、Memcachedのポートを開きます。
たとえば、TCPポート11211 。
sudo firewall-cmd --permanent --zone=elasticsearch --add-port=9200/tcp上記のファイアウォールポートオープンルールを新しい値に変更すると、構成ファイルのデフォルトポートを変更できることに注意してください。
これらのコマンドを実行した後、ファイアウォールをリロードして新しいルールを実装します。
sudo firewall-cmd --reload成功した場合の出力例:
successElasticsearchの使用方法
curlコマンドを使用してElasticsearchを使用するには 簡単なプロセスです。以下は、最も一般的に使用されるものの一部です。
インデックスの削除
インデックスの下にはサンプルという名前が付けられています 。
curl -X DELETE 'http://localhost:9200/samples'すべてのインデックスを一覧表示
curl -X GET 'http://localhost:9200/_cat/indices?v'すべてのドキュメントをインデックスに一覧表示
curl -X GET 'http://localhost:9200/sample/_search'URLパラメータを使用したクエリ
ここでは、Luceneクエリ形式を使用してq =school:Harvardを記述します。
curl -X GET http://localhost:9200/samples/_search?q=school:HarvardJSONを使用したクエリ(別名ElasticsearchクエリDSL)
URLのパラメータを使用してクエリを実行できます。ただし、次の例に示すように、JSONを使用することもできます。複雑なクエリがある場合、URLパラメータの1つの巨大な文字列よりも、JSONの方が読みやすくデバッグしやすいでしょう。
curl -XGET --header 'Content-Type: application/json' http://localhost:9200/samples/_search -d '{
"query" : {
"match" : { "school": "Harvard" }
}
}'リストインデックスマッピング
すべてのElasticsearchフィールドはインデックスです。したがって、これにより、インデックス内のすべてのフィールドとそのタイプが一覧表示されます。
curl -X GET http://localhost:9200/samplesデータの追加
curl -XPUT --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/1 -d '{
"school" : "Harvard"
}'ドキュメントの更新
既存のドキュメントにフィールドを追加する方法は次のとおりです。まず、新しいものを作成します。次に、それを更新します。
curl -XPUT --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/2 -d '
{
"school": "Clemson"
}'
curl -XPOST --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/2/_update -d '{
"doc" : {
"students": 50000}
}'バックアップインデックス
curl -XPOST --header 'Content-Type: application/json' http://localhost:9200/_reindex -d '{
"source": {
"index": "samples"
},
"dest": {
"index": "samples_backup"
}
}'
JSON形式の一括読み込みデータ
export pwd="elastic:"
curl --user $pwd -H 'Content-Type: application/x-ndjson' -XPOST 'https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/0/_bulk?pretty' --data-binary @<file>クラスターの状態を表示する
curl --user $pwd -H 'Content-Type: application/json' -XGET https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/_cluster/health?pretty集約とバケット集約
Nginx Webサーバーの場合、これによりユーザー都市ごとのWebヒット数が生成されます:
curl -XGET --user $pwd --header 'Content-Type: application/json' https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/logstash/_search?pretty -d '{
"aggs": {
"cityName": {
"terms": {
"field": "geoip.city_name.keyword",
"size": 50
}
}
}
}
'これにより、NginxWebサーバーログ内の町の製品応答コード数に拡張されます
curl -XGET --user $pwd --header 'Content-Type: application/json' https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/logstash/_search?pretty -d '{
"aggs": {
"city": {
"terms": {
"field": "geoip.city_name.keyword"
},
"aggs": {
"responses": {
"terms": {
"field": "response"
}
}
}
},
"responses": {
"terms": {
"field": "response"
}
}
}
}'基本認証でのElasticSearchの使用
ElasticSearchでセキュリティをオンにしている場合は、すべてのcurlコマンドに以下に示すようなユーザーとパスワードを指定する必要があります。
curl -X GET 'http://localhost:9200/_cat/indices?v' -u elastic:(password)プリティプリント
JSONをきれいに印刷するには、検索に?pretty=trueを追加します。このように:
curl -X GET 'http://localhost:9200/(index)/_search'?pretty=true特定のフィールドのみを照会して返すには
特定のフィールドのみを返すには、それらを_source配列に入れます:
GET filebeat-7.6.2-2020.05.05-000001/_search
{
"_source": ["suricata.eve.timestamp","source.geo.region_name","event.created"],
"query": {
"match" : { "source.geo.country_iso_code": "GR" }
}
}日付でクエリするには
フィールドのタイプがdateの場合、次のように日付計算を使用できます。
GET filebeat-7.6.2-2020.05.05-000001/_search
{
"query": {
"range" : {
"event.created": {
"gte" : "now-7d/d"
}
}
}
}Elasticsearchを削除(アンインストール)する方法
Elasticsearchが不要になった場合は、次のコマンドでソフトウェアを削除できます。
sudo zypper remove elasticsearch出力例:
「Y」と入力します 次に、「ENTERキー」を押します。 Elasticsearchの削除を続行します。