はい、Linux はページングを使用するため、すべてのアドレスは常に仮想です。 (既知の物理アドレスでメモリにアクセスするために、Linux はすべての物理メモリを 1:1 でカーネル仮想アドレス空間の範囲にマップしたままにするため、物理アドレスをオフセットとして使用してその「配列」に単純にインデックスを付けることができます。32 のモジュロの複雑さカーネル アドレス空間より多くの物理 RAM を持つシステム上の -bit カーネル。)
<ブロック引用>ページで構成されるこの線形アドレス空間は、4 つのセグメントに分割されます
いいえ、Linux はフラット メモリ モデルを使用します。これら 4 つのセグメント記述子すべてのベースとリミットは 0 と -1 (無制限) です。つまり、それらはすべて完全にオーバーラップし、32 ビットの仮想リニア アドレス空間全体をカバーします。
<ブロック引用>
したがって、赤い部分は 2 つのセグメント __KERNEL_CS で構成されます そして __KERNEL_DS
いいえ、これはあなたが間違ったところです。 x86 セグメント レジスタはではありません セグメンテーションに使用されます。これらは、x86-64 での CPU モードと特権レベルの選択にのみ使用される x86 レガシー バゲージです .そのための新しいメカニズムを追加し、ロング モード用にセグメントを完全に削除する代わりに、AMD はロング モードでセグメンテーションを中和し (基本は 32 ビット モードで使用されるすべてのユーザーと同じように 0 に固定)、マシン構成以外の目的でのみセグメントを使用し続けました。実際に 32 ビット モードなどに切り替えるコードを書いていない限り、特に興味深いことです。
(ただし、FS および/または GS にゼロ以外のベースを設定できます。Linux はスレッド ローカル ストレージに設定します。しかし、これは copy_from_user() の方法とは関係ありません。 実装されている、または何か。セグメントまたはセグメント記述子の CPL / RPL を参照するのではなく、そのポインター値をチェックするだけで済みます。)
32 ビット レガシー モードでは、セグメント化されたメモリ モデルを使用するカーネルを作成することは可能ですが、主流の OS で実際にそれを行ったものはありません。ただし、それが実現したことを望む人もいます。 Multics スタイルの OS を不可能にする x86-64 を嘆くこの回答を参照してください。しかし、これはそうではありません Linux の仕組み
Linux は https://wiki.osdev.org/Higher_Half_Kernel であり、カーネル ポインターには 1 つの値の範囲 (赤い部分) があり、ユーザー空間のアドレスは緑の部分にあります。適切なユーザー空間ページテーブルがマップされている場合、カーネルはユーザー空間アドレスを簡単に逆参照できます。それらを変換したり、セグメントで何かをしたりする必要はありません。 これがフラットなメモリ モデルを持つことの意味です . (カーネルは「ユーザー」ページ テーブル エントリを使用できますが、使用できません 逆に)。特に x86-64 の場合、実際のメモリ マップについては https://www.kernel.org/doc/Documentation/x86/x86_64/mm.txt を参照してください。
これら 4 つの GDT エントリをすべて個別にする必要がある唯一の理由は、特権レベルの理由と、データ セグメント記述子とコード セグメント記述子の形式が異なるためです。 (GDT エントリには、基本/制限以外のものが含まれています。これらは異なる必要がある部分です。https://wiki.osdev.org/Global_Descriptor_Table を参照してください)
特に https://wiki.osdev.org/Segmentation#Notes_Regarding_C では、「通常の」OS が GDT を使用してフラットなメモリ モデルを作成する方法と理由を説明しており、特権レベルごとにコードとデータ記述子のペアを使用します。 .
32 ビット Linux カーネルの場合、gs のみ スレッドローカルストレージのゼロ以外のベースを取得します (したがって、[gs: 0x10] のようなアドレス指定モード 実行するスレッドに依存する線形アドレスにアクセスします)。または、64 ビット カーネル (および 64 ビット ユーザー空間) では、Linux は fs を使用します。 . (x86-64 は GS を swapgs で特別なものにしたため syscall での使用を意図した命令 カーネルがカーネル スタックを見つけるためです。)
とにかく、FS または GS のゼロ以外のベースは GDT エントリからのものではなく、wrgsbase で設定されています。 命令。 (または、MSR への書き込みを使用して、それをサポートしていない CPU で)。
しかし、これらのフラグ、つまり 0xc09b は何ですか 、 0xa09b 等々 ?私はそれらがセグメントセレクターであると信じがちです
いいえ、セグメントセレクターは GDT へのインデックスです。カーネルは、[GDT_ENTRY_KERNEL32_CS] = initializer_for_that_selector のような指定初期化子構文を使用して、GDT を C 配列として定義しています。 .
(実際には、セレクタの下位 2 ビット、つまりセグメント レジスタの値が現在の特権レベルです。つまり、GDT_ENTRY_DEFAULT_USER_CS `__USER_CS>> 2.)
mov ds, eax メモリ内の一致するデータを線形検索するのではなく、GDT にインデックスを付けるようにハードウェアをトリガーします!
GDT データ形式:
x86-64 Linux ソース コードを見ているので、カーネルは保護モードではなくロング モードになります。 USER_CS には別のエントリがあるのでわかります。 と USER32_CS . 32 ビット コード セグメント記述子の L は ビットがクリアされました。現在の CS セグメントの説明は、x86-64 CPU を 32 ビット互換モードと 64 ビット long モードにするものです。 32 ビットのユーザー空間に入るには、iret または sysret CS:RIP をユーザー モードの 32 ビット セグメント セレクターに設定します。
思う CPU を 16 ビット コンパット モードにすることもできます (コンパット モードはリアル モードではありませんが、デフォルトのオペランド サイズとアドレス サイズは 16 です)。ただし、Linux はこれを行いません。
とにかく、https://wiki.osdev.org/Global_Descriptor_Table とセグメンテーションで説明されているように、
<ブロック引用>各セグメント記述子には、次の情報が含まれています:
- セグメントのベースアドレス
- セグメントのデフォルト操作サイズ (16 ビット/32 ビット)
- 記述子の特権レベル (リング 0 -> リング 3)
- 粒度 (セグメント制限はバイト/4kb 単位)
- セグメント制限 (セグメント内の最大の正当なオフセット)
- セグメントの存在 (存在するかどうか)
- 記述子のタイプ (0 =システム、1 =コード/データ)
- セグメントの種類 (コード/データ/読み取り/書き込み/アクセス済み/準拠/非準拠/展開アップ/展開ダウン)
これらは余分なビットです。実際にどのようにエンコードされているかの詳細には触れずに、さまざまな GDT エントリの目的とその機能の概要を理解している (と思う) ので、どのビットがどのビットであるかについては特に関心がありません。
しかし、x86 マニュアルまたは osdev wiki、およびそれらの init マクロの定義を確認すると、それらが L の GDT エントリになることがわかるはずです。 ビットは 64 ビット コード セグメントに対して設定され、32 ビット コード セグメントに対してクリアされます。そして明らかに、タイプ (コードとデータ) と特権レベルが異なります。
免責事項
このトピックの誤解を解消するために、この回答を投稿しています (@PeterCordes が指摘しているように)。
ページング
Linux (x86 保護モード) のメモリ管理では、ページングを使用して、物理アドレスを仮想化された フラット にマッピングします。 0x00000000 からの線形アドレス空間 0xFFFFFFFF へ (32 ビット)、フラット メモリ モデルとして知られています。 . Linux は、CPU の MMU (メモリ管理ユニット) と共に、対応する物理アドレスに 1:1 でマップされたすべての仮想アドレスと論理アドレスを維持します。物理メモリは通常、メモリの管理を容易にするために 4KiB ページに分割されます。
カーネル仮想アドレス 連続したカーネル logical にすることができます 連続する物理ページに直接マップされたアドレス。他のカーネル仮想アドレスは完全に 大規模なバッファ割り当て (小規模メモリ システムの連続領域を超える) および/または PAE メモリ (32 ビットのみ) に使用される非連続物理ページにマップされた仮想アドレス。 MMIO ポート (Memory-Mapped I/O) も、カーネル仮想アドレスを使用してマップされます。
<ブロック引用>すべての逆参照アドレスはする必要があります 仮想アドレスになります。論理アドレスまたは完全仮想アドレスのいずれかであり、物理 RAM および MMIO ポートは、使用前に仮想アドレス空間にマップされます。
カーネルは kmalloc() を使用して仮想メモリのチャンクを取得します 、仮想アドレスによって指されますが、さらに重要なことは、それも カーネル論理アドレス。つまり、連続への直接マッピングがあります 物理ページ (したがって DMA に適しています)。一方、vmalloc() ルーチンは full のチャンクを返します 仮想アドレスによって指されるが、仮想アドレス空間上でのみ連続しており、連続していない物理ページにマップされている仮想メモリ。
カーネル論理アドレスは固定マッピングを使用します 物理アドレス空間と仮想アドレス空間の間。これは、事実上隣接する領域は、本質的に物理的にも隣接していることを意味します。これは、連続していない物理ページを指す完全仮想アドレスには当てはまりません。
ユーザー仮想アドレス - カーネルの論理アドレスとは異なり、仮想アドレスと物理アドレスの間の固定マッピングを使用しないでください。ユーザーランド プロセスは MMU をフルに活用します:
- 物理メモリの使用済み部分のみがマップされます。
- メモリが連続していません。
- メモリがスワップアウトされる可能性があります。
- メモリは移動できます;
詳細には、4KiB の物理メモリ ページは OS ページ テーブルの仮想アドレスにマッピングされ、各マッピングは PTE (ページ テーブル エントリ) と呼ばれます。 CPU の MMU は、最近使用された各 PTE のキャッシュを OS ページ テーブルから保持します。このキャッシュ領域は、TLB (Translation Lookaside Buffer) として知られています。 cr3 register は、OS ページ テーブルの場所を特定するために使用されます。
仮想アドレスを物理アドレスに変換する必要があるときはいつでも、TLB が検索されます。一致が見つかった場合 (TLB hit )、物理アドレスが返され、アクセスされます。ただし、一致がない場合 (TLB miss )、TLB ミス ハンドラーはページ テーブルを検索して、マッピングが存在するかどうかを確認します (ページ walk )。存在する場合は、TLB に書き戻され、障害のある命令が再開されます。この後続の変換で TLB ヒット が検出されます。 メモリアクセスは継続します。これは未成年者として知られています ページ違反。
場合によっては、OS がページをハード ディスクに移動して、物理 RAM のサイズを増やす必要がある場合があります。仮想アドレスがハードディスクにマップされたページに解決される場合、そのページはアクセスする前に物理 RAM にロードする必要があります。これはメジャーとして知られています ページ違反。次に、OS ページ フォールト ハンドラーは、メモリ内の空きページを見つける必要があります。
仮想アドレスに使用できるマッピングがない場合、つまり仮想アドレスが無効な場合、変換プロセスは失敗する可能性があります。これは無効と呼ばれます ページ フォールト例外、および segfault OS ページ フォールト ハンドラによってプロセスに発行されます。
メモリ セグメンテーション
リアルモード
リアル モードでも 20 ビットのセグメント化されたメモリ アドレス空間を使用し、1MiB のアドレス可能なメモリ (0x00000 - 0xFFFFF) を使用します。 ) およびすべてのアドレス指定可能なメモリ、バス アドレス、PMIO ポート (ポート マップ I/O)、および周辺ハードウェアへの無制限の直接ソフトウェア アクセス。リアル モードはメモリ保護なしを提供します 、権限レベルなし、仮想化アドレスなし。通常、セグメント レジスタにはセグメント セレクタ値が含まれ、メモリ オペランドはセグメント ベースに対するオフセット値です。
セグメンテーションを回避するために (C コンパイラは通常、フラット メモリ モデルのみをサポートします)、C コンパイラは非公式の far を使用しました。 segment:offset で物理アドレスを表すポインタ型 論理アドレス表記。たとえば、論理アドレス 0x5555:0x0005 、 0x5555 * 16 + 0x0005 を計算した後 20 ビットの物理アドレス 0x55555 を生成します 、以下に示すように far ポインターで使用可能:
char far *ptr; /* declare a far pointer */
ptr = (char far *)0x55555; /* initialize a far pointer */
現在、最新の x86 CPU のほとんどは、下位互換性のためにリアル モードで起動し、その後保護モードに切り替えます。
保護モード
プロテクト モードで、フラット メモリ モデルを使用 、セグメンテーションは未使用です . 4 つのセグメント、つまり __KERNEL_CS 、 __KERNEL_DS 、 __USER_CS 、 __USER_DS すべてのベース アドレスは 0 に設定されています。これらのセグメントは、セグメント化されたメモリ管理が使用されていた以前の x86 モデルの単なるレガシー バゲージです。プロテクト モードでは、すべてのセグメントのベース アドレスが 0 に設定されているため、論理アドレスは同等です。
フラット メモリ モデルの保護モードは、セグメンテーションがないことを意味します。セグメントのベース アドレスが 0 以外の値に設定されている唯一の例外は、スレッド ローカル ストレージが関係している場合です。 FS (そして GS 64 ビット) セグメント レジスタは、この目的で使用されます。
ただし、SS などのセグメント レジスタ (スタック セグメント レジスタ)、DS (データ セグメント レジスタ) または CS (コード セグメント レジスタ) はまだ存在し、16 ビット セグメント セレクター を格納するために使用されます 、セグメントの記述子へのインデックスが含まれています LDT および GDT (ローカルおよびグローバル記述子テーブル) 内。
暗黙的にメモリにアクセスする各命令 セグメントレジスタを使用します。コンテキストに応じて、特定のセグメント レジスタが使用されます。たとえば、JMP 命令は CS を使用します PUSH の間 SS を使用 .セレクターは MOV のような命令でレジスターにロードできます 、唯一の例外は CS です 実行フローに影響する命令によってのみ変更されるレジスタ 、 CALL のように または JMP .
CS レジスタは、セグメント セレクタで CPL (現在の特権レベル) を追跡し、現在のセグメントの特権レベルを維持するため、特に便利です。この 2 ビットの CPL 値は、常に CPU の現在の特権レベルに相当します。
メモリー保護
ページング
モード ビットまたは保護リングとも呼ばれる CPU 特権レベル 0 ~ 3 は、ユーザー モードで許可されている場合に保護メカニズムを破壊したり混乱を引き起こしたりする可能性のある一部の命令を制限するため、それらはカーネルに予約されています。リング 0 の外でそれらを実行しようとすると、一般保護が発生します フォルト例外、無効なセグメント アクセス エラーが発生した場合と同じシナリオ (特権、タイプ、制限、読み取り/書き込み権限)。同様に、メモリおよび MMIO デバイスへのアクセスは特権レベルに基づいて制限され、必要な特権レベルなしで保護されたページにアクセスしようとすると、ページ フォールト例外が発生します。
モード ビットは、割り込み要求が発生するたびに、ユーザー モードからスーパーバイザー モードに自動的に切り替わります。 (IRQ)、いずれかのソフトウェア (つまり、syscall ) またはハードウェアが発生します。
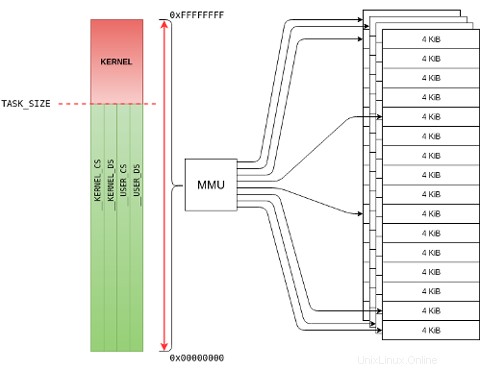
32 ビット システムでは、4GiB のメモリしか効果的にアドレス指定できず、メモリは 3GiB/1GiB 形式で分割されます。 Linux (ページングが有効になっている) は、上位ハーフ カーネルと呼ばれる保護スキーマを使用します。 ここで、フラットなアドレス空間は仮想アドレスの 2 つの範囲に分割されます:
-
0xC0000000 - 0xFFFFFFFFの範囲のアドレス カーネル仮想アドレス (赤い領域) です。 896MiB の範囲0xC0000000 - 0xF7FFFFFFカーネルの論理アドレスとカーネルの物理アドレスを 1:1 で、連続した低メモリに直接マップします ページ (__pa()を使用) および__va()マクロ)。残りの 128MiB 範囲0xF8000000 - 0xFFFFFFFF次に、大きなバッファ割り当て、MMIO ポート (メモリ マップド I/O)、および/または PAE メモリの仮想アドレスを、連続していない 高メモリ にマップするために使用されます。 ページ (ioremap()を使用) とiounmap()). -
0x00000000 - 0xBFFFFFFFの範囲のアドレス ユーザーの仮想アドレスです (緑色の領域)、ユーザーランド コード、データ、およびライブラリが存在します。マッピングは、連続していない低メモリ ページと高メモリ ページにある可能性があります。
ハイ メモリは、32 ビット システムにのみ存在します。 kmalloc() で割り当てられたすべてのメモリ 論理的な 仮想アドレス (直接物理マッピングを使用); vmalloc() によって割り当てられたメモリ 完全に 仮想アドレス (ただし、直接の物理マッピングはありません)。 64 ビット システムには膨大なアドレス指定機能があるため、物理 RAM のすべてのページを効果的にアドレス指定できるため、大容量メモリは必要ありません。
境界 スーパーバイザーの上半分とユーザーランドの下半分の間のアドレスは TASK_SIZE_MAX として知られています Linux カーネルで。カーネルは、以下のコードに示すように、ユーザーランド プロセスからアクセスされたすべての仮想アドレスがその境界より下にあることを確認します:
static int fault_in_kernel_space(unsigned long address)
{
/*
* On 64-bit systems, the vsyscall page is at an address above
* TASK_SIZE_MAX, but is not considered part of the kernel
* address space.
*/
if (IS_ENABLED(CONFIG_X86_64) && is_vsyscall_vaddr(address))
return false;
return address >= TASK_SIZE_MAX;
}
ユーザーランド プロセスが TASK_SIZE_MAX よりも高いメモリ アドレスにアクセスしようとした場合 、do_kern_addr_fault() ルーチンは __bad_area_nosemaphore() を呼び出します ルーチン、最終的に SIGSEGV で障害のあるタスクを通知します (get_current() を使用) task_struct を取得するには ):
/*
* To avoid leaking information about the kernel page table
* layout, pretend that user-mode accesses to kernel addresses
* are always protection faults.
*/
if (address >= TASK_SIZE_MAX)
error_code |= X86_PF_PROT;
force_sig_fault(SIGSEGV, si_code, (void __user *)address, tsk); /* Kill the process */
ページには、U として知られる特権ビットもあります。 R に加えて SMAP (Supervisor Mode Access Prevention) に使用される ser/Supervisor フラグ SMEP (Supervisor Mode Execution Prevention) が使用する read/write フラグ。
セグメンテーション
セグメンテーションを使用する古いアーキテクチャは、通常、要求された各セグメントに対して GDT 特権ビットを使用してセグメント アクセス検証を実行します。 DPL (Descriptor Privilege Level) として知られる要求されたセグメントの特権ビットは、現在のセグメントの CPL と比較され、CPL <= DPL が保証されます。 . true の場合、要求されたセグメントへのメモリ アクセスが許可されます。